Prompt Weights and new text Parser (beta)
New Weights Parser, Updated
Updated June 11th with clearer examples, exercises, and a mini quiz
Weights are a new feature in our Web UI and Telegram Bot, made possible by a subsystem called a Text Parser, literally a piece of code that tries to understand which words are most important to you. The old text parser did not support weights, the new one does. You can flip between both.
Web UI: Hit advanced options and switch this toggle to turn it on:

Telegram: Adding this command when you are rendering:
/render /parser:new your prompt goes here (dog:2) etc
Unless one of these are invoked, weights are ignored. The parser command goes away when our Beta period is over.
Introduction to Weights
You’ve probably seen an Stable Diffusion prompt that looks like thing like this:
Side note about syntax: In our system, pointed brackets like
Weight Ranges and Safe Defaults
A number greater than 0, even fractional, is still a positive weight. So even though 0.7 looks is less than a whole 1, an expression like (dog:0.7) still means that some image of a dog will enter the picture. Less than 0 is negative, and negatives are generally bad news.
In weights, negatives don’t work like negative prompts. You probably mean zero, not negative. Negative weight is the Twilight Zone, things get eerie like Negative Guidance. Possible, but odd.
The most-used weight is 0.7
Especially for LoRAs. Many consider 0.7 as the safest place to start, because it gives the right of way so that a base model can set the art style, but is still present to do its job. When using LoRAs especially, you rarely want to use a weight of 1 or more unless you want a very bold effect.
Figure 1: Weights vs. Positive Prompts
Three ways to express extra attention to the word dog are:
(dog:1.1), (dog) and ((dog:1.1)), but the last one is generally not advised as it makes things harder to control and may lead to bad results.
Why weights are useful
Weighted prompts are useful for expressing relative ideas. For example, to render an image of a dog that has some traits of a cat, you can prompt:

/render /parser:new a (cat:2,dog:0.5)
Notice how the nose and paws are a bit dog like, but it’s primarily a cat.
Side note: Remember that word order also matters, more so than weights. If we switch the order of those two simple words, it becomes a different image, despite the weights remaining the same. In the case of blending two animals, it’s hard to discern this idea, so let’s blend more concepts next.
Good Ranges to Remember
- The middle is 1
- positive prompts are like this
- (good:0.7) <– weaker positive
- (good:1.3) <–stronger positive
- Negative prompts like this [(thing:1), (thing:1.3), thing:0.7)]
- Use negative weights with LoRA only (at your own risk!)
dog – neutral
(dog) – dog is 1.1x important
(dog:1) – neutral
(dog:1.1) – dog is 1.1x important
Mixing positive syntax with positive weights works (but isn’t advised)
((dog:0.5)) – dog is 0.5x is strenghtened by the (positive) syntax
((dog:2.0)) – dog is 2x is strenghtened by the (positive) syntax and will most likely break your render as it makes this single prompt too strong
But the same can’t be said for negative prompts
dog – neutral
[dog] – a standard negative prompt, meaning it is 1.1x discouraged
[dog:2] – 2x is ignored, this only processes as a 1.1x negative prompt
[[dog:2]] – 2x is also ignored, and the [negative] syntax takes over
Did you get it? Test Yourself
Q) Can you use weights without ()? For example, is good:1.6 valid, or do you have to go with (good:1.6)?
A) You have to use (good:1.2)
Q) How does it work with negatives? The same way? [bad:1.6]?
A) You have to use [(bad:1.2)] for it to work properly. Also don’t worry about () inside [] with added weight, as it’s influence is non-existent.
Degrees of precision
As for decimals, one or two degrees is more than sufficient. In our testing, (dog:0.55) isn’t that different from (dog:0.55348567) when all the other values are locked.
When you’re testing relative weights, remember that our system assigns random values for seed, guidance, and sampler. If those values aren’t set, you’re going to get very different pictures every time by design. Let’s do some exercises where those values are always the same and compare.
Exercise: Red, Blue, Dog, Cat
Here we have some dog-like looking cats, some are blue and some are red. Use what you learned to try to eliminate a color or an animal feature from the image, can you do it? Weights aside, Guidance is also important, you can put any prompts you want but with a low guidance the AI will ignore most of your orders anyway. So set your guidance to 13 so it listens to you well.

/render /seed:32745 /sampler:ddim /guidance:13 /parser:new /images:1 blue cat, red dog, [blue cat, red dog]
Let’s start with a control image. No weights. Now let’s try to remove the red.

/render /seed:32745 /sampler:ddim /guidance:13 /parser:new /images:1 blue cat, red dog, [blue cat, (red dog:2)]
We have raised negative weight of “red dog” got rid of token “dog” and token “red”, so these are now more clearly cat-like and there isn’t a red animal in the image.
Let’s try another exercise: Can you get rid of all the cats?

A possible solution is:
/render /seed:32745 /sampler:ddim /guidance:13 /parser:new /images:1 (blue cat:0.1), (red dog:2), [(blue cat:2), (red dog:0.1)]
Blue cat was harder to get rid of, possibly because it was first in prompt order. So a lot of the weights were shifted around to get rid of them.
Exercise 1: Why does this prompt produce nearly the same image as the very first control image?

/render /seed:32745 /sampler:ddim /guidance:13 /parser:new /images:1 blue cat, red dog, [blue cat, red dog:2]
Answer: Because a parenthesis is missing inside the negative prompt. What was processed was not weights, but a weak [negative prompt] weight 2 negative was ignored. Without the parenthesis, it just literally means “number 2”.
Now let’s try double square brackets as a substitute for parenthesis, will it work the same as parenthesis inside a negative tag?

/render /seed:32745 /sampler:ddim /guidance:13 /parser:new /images:1 blue cat, red dog, [blue cat, [red dog:2]]
Here, what is processed is a double strong negative [[like this]] and weights were also ignored. So now we know that doesn’t work, it needs parenthesis. But if we just wanted to get rid of dogs, using negatives instead of weights is also a valid strategy. See? Dog traits are gone due to the stronger negative. If that is all we wanted, there’s no need for weights. A simple negative works.
Exercise 2: Spot the mistake
Will this prompt work as intended?
Figure 1 - /render /parser:new /clipskip:1 /seed:761614 /sampler:ddim /guidance:11.5 1girl [lowres:2, blurry:2, worst quality:2, pixelated:2]
Or maybe this one will?
Figure 2 - /render /parser:new /clipskip:1 /seed:761614 /sampler:ddim /guidance:11.5 1girl [lowres;2, blurry;2, worst quality;2, pixelated;2]
The correct answers is that neither of them will work properly, they’re both wrong. Both are missing the ( weights parenthesis ) so no weights took hold. In additon, figure 2 has an intentional typo of semi-colons to prove a point — they both result in basically the same picture. The results are shown below, the changes are very minor due to the token difference of the erroneous ; processed as words. That they resulted in minor shading differences is arbitrary, this isn’t a thing.


We can take the same seed and make those weights fire, and the same prompt is suddenly a very different picture.

/render /parser:new /clipskip:1 /seed:761614 /sampler:ddim /guidance:11.5 1girl [(lowres:2), (blurry:2), (worst quality:2), (pixelated:2)]
Whether or not to individually put them in parenthesis, or to use weights and commas in one long parenthesis is up to you. Both of those work and result in a similar picture relative to each other, but the weights are working in both.

/render /parser:new /clipskip:1 /seed:761614 /sampler:ddim /guidance:11.5 1girl [(lowres:2, blurry:2, worst quality:2, pixelated:2)]
Granted, these are both beautiful pictures so the nuances are harder to spot. If you’re ever completely lost, go back to the red/blue, dog/cat strategy to make sure your prompt is doing what you think it is.
Using Weights in Web UI
If you know what you’re doing, just type them out and they work as they do in the PC version of Stable Diffusion. To turn on the New Parser in Web UI:
- Click Advanced (bottom left)
- Click on the Weights button on the top right of the screen (pictured)
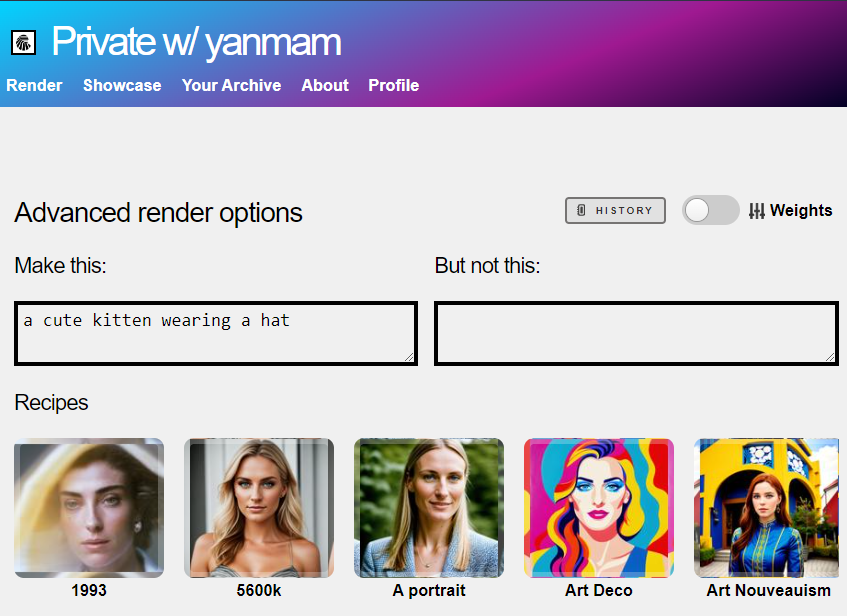
The weights mode will then reveal sliders, so you can more easily set words and stack other kinds of visual concepts together to create a unique composition.
Let’s review all of the elements you can play with on this page:
- Top right: the weights tab is activated, so you can type individual words and add weight to each word separately, using a slider. Click the ‘add weighted word’ gray button to add more, or type your whole positive prompt there if all of those words should have equal weight.
- The blue slider shows a weight of 1.0. If you slide it left, it will turn the box red, indicating it will have a negative effect.
- Optionally, you can select a recipe. Recipes are prompt templates that create visual result similar to the photo shown. Recipes have their own base model, but you can override it.
- Base art style, or base model, is the over-arching visual style and contents model. The base model has the biggest visual impact over the image. Here the model
aka Rev Animated is selected. Base models do not have weights, they are the foundation that everything else sits on top of.

Here, we have added a new keyword and given it a negative weight of 0.49
Clicking the “Add Concept” Button lets us change the Base Model, or stack additional visual concepts, like characters, effects, poses, and more.

I’m creating a strange fantasy animal, so I went into the creatures category and picked one. See “Best Practices and Troubleshooting” below to learn how to make the most of this feature.
If you make a mistake, can hit your History button and edit again.
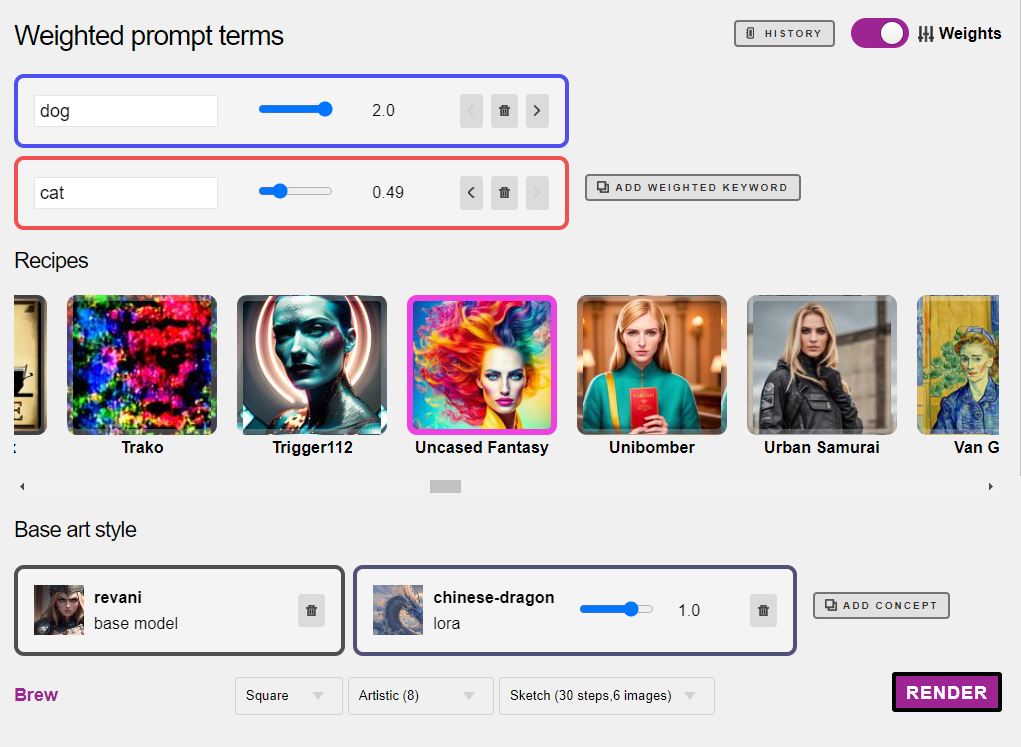
At the bottom, you’ll also find a Brew button, which takes you back to the easy non-weights mode, as well as pulldowns for guidance (CFG), Aspect Ratio, and Steps vs. Number of Images. Each value takes the same time to render.
Putting it together
We have also added a Lora with a weight of 1.0. That should probably be adjusted to 0.7 to be safe, tsk tsk. So the visual concept “chinese dragon” will become the subject of the image, with the prompt template “Uncased Fantasy” which probably adds tokens like “masterpiece” and “high quality” while also adding common negative prompts like “not mutated”, etc.

And here’s my 70% dragon dog-cat. Mostly dragon cat, to be fair. I guess the stronger associations with cats and dragons in Asian art beat out my more beefily weighted dog, so I can go back and reduce cat further, or add more words about what a dog looks like to change my outcome.
When you end up with images that aren’t quite right, you can click My Archive to backtrack on your prompt history, and clear out the ones you don’t want.
When working in Telegram, you can also do the /delete command to wipe an image out from your history and archive by replying to the picture.
Best Practices & Troubleshooting
Most problems arise when weights are too high, or when concepts conflict. If you have everything set between 0.5 to 0.7 you can avoid most problems.
Some models are very sensitive. Try as low as 0.1 if they are glitching. We’ve written a separate section on fixing common LoRA problems with examples.
How many visual concepts is too much?
You can safely add 2-3 LoRAs with low weights to an image, though think carefully how they overlap. If the image doesn’t come back, the server ran out of memory and the image could not be completed. Try a lower image count.
Choose Draft in the Quality settings, to test your idea. No sense in waiting longer if there are conflicting concepts, its better to build your idea slowly and iterate on your idea.
Blue Artifacts are common
When working with LoRAs and Weights, you will inevitably run into conflicts. For example, adding a LoRA of a Zombie and also adding a LoRA of a Knight’s Helmet means both will fight to influence the face, and blue artifacts will occur. If this happens, lower your weights, or choose a different visual concept. Keep things simple and build slowly.
The image comes back as a colorful square, no subject
There are some (very few) models that aren’t compatible with our system, but generally speaking when LoRAs have low weights, this shouldn’t happen. If you’re getting a red square, lower your weights. If you’re still getting something that looks like green mountains or noise, please let us know.
Different results from something you saw on the Internet
We’re right there with you. Not everyone publishes their best kept secrets, including fixing their images for 3 hours using inpaint and Lightroom. The competition within the Stable Diffusion community to create the very best images is fierce. There’s a little cheating. Don’t get caught up in it.
In the case of the popular Civitai website, see what other users in the comments are saying and make sure you’re using all the same concepts. If we are missing a model that you need, just let us know and we’ll add it.
Very different results from your local PC
In this case, we really want to know — please contact us. It might be due to different versions of AI models, in which case we can update them right away.
Our system is also calibrated a bit differently due to hardware, drivers, and other web components, but the general image quality should be comparable.
If you think you’ve encountered a bug, please do let us know.