概述 Pirate Diffusion by Graydient AI is the most powerful bot on Telegram. It is a multi-modal bot, meaning that it handles large language models like DeepSeek and Llama 3.3, tens of thousands of image models like HiDream, Chroma, FLUX, Stable Diffusion 3.5, AuraFlow, Pony, and SDXL and also video models like Wan, Hunyuan and LightTricks (LTX).
难以置信的价值
与其他生成式人工智能服务不同的是,它不需要 "代币 "或 "信用点数"。PirateDiffusion 可无限制使用,免版税,并与Graydient的webUI 捆绑。
为什么使用机器人?
它在移动设备上运行速度极快,而且非常轻便,你可以单独使用,也可以在陌生人群组或与朋友一起使用。我们的community 正在为强大的 ComfyUI 工作流程制作聊天宏,因此您可以从简单的聊天机器人中获得桌面渲染结果的全部优势。太疯狂了
它还能做什么?
Images、视频和LLM 聊天。它几乎无所不能。
无需图形用户界面,敲几下键盘就能制作 4kimages 。你可以通过聊天使用所有主要的 Stable Diffusion 功能。有些功能需要可视化界面,它会为这些功能弹出一个网页(统一WebUI 集成)
您可以使用自己的私人机器人进行创作,也可以加入群组,看看其他人在做什么。您还可以创建像 /animebot 这样的主题bots ,将我们的 PollyGPT LLM 与 StableDiffusion 模型连接起来,并与他们聊天,帮助您进行创作!使用 loadouts、recipe (宏)widgets(可视化向导生成器)和自定义bots 创建完全属于你的workflow 。它可以做很多事情!
起源故事
Pirate Diffusion 这个名字来源于 2022 年 10 月泄露的稳定扩散 1.5 模型,该模型被 开源 Pirate Diffusion 。 它吸引了很多有趣的人。
为 Plus 会员提供无限制的视频再生功能!
如果您是Graydient视频计划的会员,您可以使用各种视频工作流程。视频工作流程一般分为两类:将提示转为视频,以及将现有照片转为视频。 (未来,我们的目标是增加视频到视频的功能,但目前还未推出)。
Text to music – two modes! AUTOMATIC LYRICS
/makesong Write a song about being in the face by a California Rattlesnake. Incorporate "dirty sanchez" and "Roosevelt Hoover"
MANUAL LYRICS
We plan to offer multiple music workflows. The first is called “music-ace” and it works like this:
/workflow /run:music-ace [verse] gonna make some songs [bridge] gonna make em [chorus] with pirate diffusion yeah! 文字转视频 首先,浏览我们的工作流程页面,找到文本到视频的简短名称。 常用的有
WAN 2.1-- 目前最顶级的开源视频模型,编写一个简单的提示就能实现!WAN 似乎比浑源有更好的提示附着力和动画效果,但解剖效果较差Boringvideo - 制作栩栩如生的普通视频,看起来就像来自 iPhone 的视频浑源 --三种类型,请在workflow 页面底部查找。浑源制作的视频最逼真。Q "数字越大,质量越高,但视频越短。视频 - 仅称为 "视频 "的版本使用 LTX Lighttricks,非常适合制作 3D 动画片
/wf /run:video-hunylora-q8 cinematic low angle video of a ronald mcdonald clown eating a square hamburger, the restaurant ((sign text says "Wendys")), ronald mcdonald's clown costume has red afro hair and a red nose with white face paint, the restaurant is brown, the burger is pointy and square, the background has blur bokeh and people are walking around
PirateDiffusion 支持浑源、LightTricks / LTX 视频和萝拉! 我们正在添加多种视频模型,作为我们服务的一部分,您可以无限制地使用它们,同时还可以无限制地进行图像和萝拉培训。
在 LTX 中,提示的结构非常重要。简短的提示会产生静态图像。带有过多操作和指令的提示会导致视频随机切换到不同的房间或角色。
最佳实践:如何让您的images 协调一致地移动
我们建议采用这样的提示模式:
首先描述摄像机在做什么或在跟踪谁。例如,低角度摄像机zoom 、俯拍摄像机、慢镜头、放大或缩小等。 接下来描述主体以及他们对什么或什么人所做的一个动作。这部分需要练习! 在上面的例子中,注意罗纳德吃汉堡是在摄像机和场景设置之后进行的 描述场景。 这可以帮助人工智能 "分割 "你想看到的东西。因此,在我们的示例中,我们描述了小丑的服装和背景。 提供辅助参考资料。 例如,说 "这看起来像是电影或电视剧中的一个场景"。 You can specify a lora to control the art direction or character likeness. Add this to the end of the prompt like <move-enhancer-huny>
图片转视频
你可以上传一张照片,然后将其制作成视频。并不是只有一种命令--请查看 "动画 "workflow 系列,使用不同类型的人工智能模型。尝试不同的模型和提示策略,找到最适合你的项目的模型,或者在PirateDiffusion 的 PLAYROOM 频道中查看其他人用它们制作的作品。
视频的长宽比将由您上传的图片决定,因此请相应裁剪。
要做到这一点,首先要把照片粘贴到聊天中,然后点击 "回复",就像你要和照片对话一样,然后给照片下达这样的命令:
/wf /run:animate-wan21 a woman makes silly faces towards the camera 或尝试 SkyReels 等其他工作流程:
/wf /run:animate-skyreels camera video that slightly changes the angle, focused on a lovely girl smiling and looking at the camera, she looks curious and confident while maintaining eyes on the viewer, her hair is parted, she sits in front of a bookshelf and peeping gremlin eyes behind her, she is relaxing vibe 我们托管用于图像到视频的开源人工智能模型。 最受欢迎的两个模型是
动画-skyreels = 使用浑源逼真视频将图像转换为视频
animate-ltx90 = 使用 LightTricks 模型。最适合 3D 动画片和电影视频
特殊参数:
/slot1 =length 视频的帧数。 安全的settings 为 89、97、105、113、121、137、153、185、201、225、241、257。 可能会有更多,但不稳定
/slot2 = 每秒帧数。 建议 24 帧。 Turbo 工作流程以 18 帧/秒运行,但可以更改。24 帧/秒以上是电影画面,30 帧/秒看起来更逼真。 在低帧率下可以达到 60fps,但看起来像花栗鼠的速度。
局限性:
您必须是Graydient Plus 的会员才能创建视频 今天,VIP 和游戏室频道中提供了许多视频样本。 在我们对视频进行最后润色的同时,欢迎前来游玩并向我们发送您的即时想法。
上一页 / 更新日志:
已添加 Wan 2.1 和 Skyreels。使用workflow /show: 查看两者的参数。 添加了新的Flux 工作流程,如 ur4(超逼真 4)和 bento-flux (Bento TWO 模型) 添加了支持 lora 的 Hunyuan 和 LightTricks / LTX 视频
已添加 Llama 3.3 和更多 LLM,请键入 //lm 命令浏览它们
现在,您可以在某些Flux 工作流程中使用多达六个Flux loras
添加了高清Anime Illustriousworkflow 。清脆!
Flux Redux、Flux Controlnet Depth 以及许多新的工作流程现已推出
更好的外绘! 试试用 /zoomout- 回复图片。flux
更好的 LoRamaker 集成。 使用/makelora 在网页浏览器中创建私人 lora,然后几分钟内就能在 Telegram 中使用。
新的LLM* 命令。 输入/llm ,然后输入任何问题。 目前由 700 亿参数的 Llama 3 型号驱动,速度很快! 我们不会对您的提示进行审查,但该模型本身可能有一些自己的防护措施。*LLM 是 "大型语言模型 "的简称,与 ChatGPT 的聊天模型类似。
这里有许多 FLUX 检查点 。键入 /workflows 浏览它们并获取它们的命令。新增功能:工作流程的快捷键是 /wf。 视频教程
更多型号,超过 10,000 个! 试试全新的 Juggernaut 9 Lightning,它比 Juggernaut X 更快:#jugg9
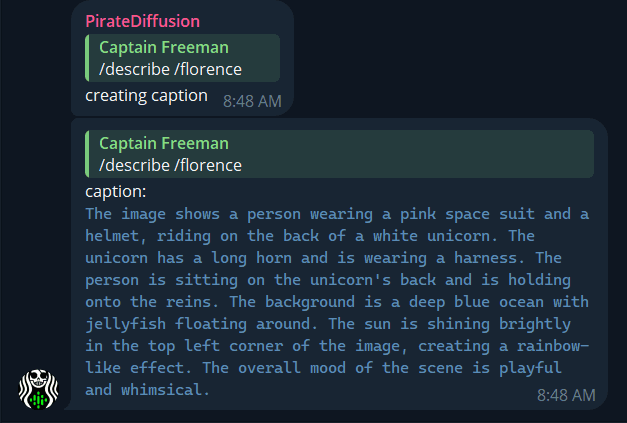
Florence 新增计算机视觉模型 - 上传任何照片并输入/describe / florence ,即可获得详细生动的提示描述,供工作流程使用 自定义bots 现在可以保留记忆。请参阅PollyGPT 教程 中的 "记忆"。
更好的render 监控!输入/monitor 即可弹出,这是一个小网页。如果您所在城市的 Telegram 服务器繁忙或离线,images 可以更快地从我们的云驱动器中提取!
新Bots !试试吧:/xtralargebot /animebot /lightningbot 和健谈的bots ,如 /kimmybot /angelinabot /nicolebot /senseibot
现在,Plus 计划的会员可以为他们的产品选择 Llama3 700 亿参数。bots
新食谱:尝试 #quick 快速高清images ,或 #quickp 人像,#quickw 宽屏。
Polly 已更新!- 使用/polly 与机器人聊天,右键单击回复进行交流
Polly 现在也只使用您在"我的 模型" 中标记为收藏的模型
新的/unified 命令可将images 发送到 Stable2go 进行网络编辑
新的/bots 命令 - 根据您的喜好定制Polly ,LLM + 图像模型!
下一个?
建议一项功能
查看 路线图 更新日志
预制和定制bots
基本原理:LLM 命令
/llm who would win a fight between a pacifist tiger with a shotgun or a thousand angry penguins parachuting above with forks and knives?
键入 /llm (如LLM, 大型语言模型)并提问,类似于 ChatGPT。 它由 700 亿参数的 Llama3 模型提供支持。
创建自己的LLM 代理
要切换到其他模式并个性化其他聊天机器人角色,请登录my.graydient.ai ,点击聊天机器人,选择其他 LLM,如 Mixtral 和 Wizard。
介绍 "POLLY"
Polly 是PirateDiffusion 中会说话和创建images 的角色之一。试试吧
如果您在 @piratediffusion_机器人中,您可以像这样与Polly 对话:
/polly a silly policeman investigates a donut factory您也可以登录my.graydient.ai, 点击聊天Bots 图标,通过网络浏览器使用它。
定制入门BOTS
Polly 只是community 创建的众多角色之一。要查看其他公开角色的列表,请键入
/bots
要创建一个新的,请键入
/bots /new
这将在网络浏览器中启动 PollyGPT,训练你自己的角色,随后可将其作为 @piratediffusion_机器人中的一个角色访问。
探索定制BOTS
人工智能community 充满了许多有趣的创造者。有些人正在开源大型语言模型(ChatGPT 的替代品)以及开源图像模型(DALLE 和 MJ 的替代品)。我们的原创软件将这两者结合在一起,成为 Telegram 或网络上易于使用的 "机器人 "制造商。请访问我们的Polly GPT 文档--现在有了回忆! 页面,了解更多信息和模板,创建您自己的bots 。
激活机器人
使用PirateDiffusion 需要Graydient 账户和(免费)Telegram 账户。 设置
您的机器人需要帮助吗?被困在免费的mode?联系我们
账户基础知识 新用户
/start 如何开始
登录my.graydient.ai ,在仪表板中找到设置图标,然后按说明操作。
如果您需要帮助,请访问我们的支持频道
电子邮件
/email [email protected] 如果您在 Patreon 上升级了账户 ,您的电子邮件和 Patreon 电子邮件必须一致。 如果无法激活和解锁所有功能,请键入 /debug 并发送该号码
USERNAME
/username Tiny Dancer 机器人会使用你的 Telegram 名称作为你的公开community username (显示在食谱等地方,特色images )。你可以随时用 /username 命令来更改,比如:WEBUI 和PASSWORD PirateDiffusion ,还附带了一个网站伴侣,用于进行一些比较麻烦的操作,比如整理文件和内画。 要访问您的存档,请键入
/webui 默认情况下它是私有的。要设置password ,请使用以下命令
/community /password:My-Super-Secure-Password123@#$%@#$ 要禁用password ,请键入
/community /password:none
什么是好的提示?
提示 是一个完整的描述,告诉人工智能生成什么图像:
是否应该写实?艺术品的类型? 描述时间、视角和光线 很好地描述主体及其行为 最后描述地点及其他细节 基本示例
一位 25 岁的金发女郎,Instagram 影视达人,过着旅行车的生活方式
快速提示技巧
1.每次都要描述全貌
提示不是聊天信息 ,也就是说不是多轮对话。每次提示都是对系统的一次全新尝试,会忘记上一轮输入的所有内容。例如,如果 我们提示 "一只穿着戏服的狗",我们肯定会得到它。 这条提示完全描述了一张照片。 如果我们只提示 "让它变成红色"(不完整的想法),我们就根本看不到狗,因为 "它 "没有被带过去,所以提示会被误解。一定要给出完整的提示。
2.词序很重要
将最重要的词语放在提示语的开头。如果您要创作一幅肖像画,则应将人物的外貌和穿着放在首位,其次才是他们在什么地方,这些都是最不重要的细节。
3.Length 也很重要
开头的单词最重要,结尾的每个单词受到的关注越来越少--最多大约 77 个 "标记 "或指令。不过,您应该知道,我们系统中的每个人工智能concept 都是根据不同的主题进行训练的,因此选择正确的concept 会影响您被理解的程度。 最好直奔主题,学习 concepts 系统 下文),而不是撰写冗长的提示,以获得最高质量的结果。
正面提示
正面提示和负面提示是告诉人工智能我们想看什么和不想看什么的词语。人类通常不会以这种二进制形式进行交流,但在非常嘈杂的环境中,我们可能会说 "这个,但是那个!"
正面: 白天的海滩景色,湛蓝的沙滩,棕榈树
在 Stable2go 编辑器的两个方框中输入的内容如下:
正面提示包含图像的主题和辅助细节。它有助于描述艺术style 和周围环境,以及您对美学的期望。 举例说明:
最逼真的小狗照片 向日葵的杰作画,虚化背景 车道上一辆踏板车的低角度照片,水彩画 乌龟与((啤酒)
重要 :
图像创建命令 必须位于正提示符之前,
如 /render 和 /polly 。
语法见下文 :
让积极因素更有力量
要进一步强调某些词语,可添加嵌套括号。这样,它们的系数就会增加 1.1 倍。
在上面的例子中,我们说 "乌龟 "是主语,因为它出现在提示语的开头,但啤酒同样重要,尽管它出现在提示语的后面。 在创造不可能的情境时,额外的强调会有所帮助。
更多例子
消极提示 底片 描述您不希望在图像中出现的内容。
如果您想要海怪,但又不喜欢大海,那么海怪就是您的最佳选择。 积极 而海洋是你的 负数 .
底片还能提高照片质量,避免出现多余肢体、分辨率低等问题。
让否定词更有力
括号的强调程度为 1.1 倍。使用方括号表示否定。
(给我想要的)[但不是这些东西]
(漂亮的猫)最佳质量[[[丑猫,低分辨率,低质量]]]
一只狗(梗犬、小狗),但不是[猫、小猫、毛球、加菲猫]
you can also call a negative concept [[<fastnegative-xl>]]
故障排除 如果图像看起来有缝隙,而guidance 设置为 7,则底片可能设置得太强烈。 试着降低其强度。
正反面曾经是引导人工智能获得我们想要的东西的唯一方法,但现在已经没有必要了。请使用concepts (如下)
更多例子
专业指令 使用这些参数可以像稳定扩散专业人员一样创建images :
RENDER 如果不需要Polly 或自定义bots 的提示帮助,请切换到 /render 命令,完全手动操作。 尝试快速学习
/render a close-up photo of a gorilla jogging in the park <sdxl> The trigger word <sdxl> refers to a concept
内联正面、反面
正值 告诉人工智能要强调什么。这可以用(圆括号)来表示。每对括号代表正强化的 1.1 倍。反方 则用 [方] 括号表示。
/render <sdxl>
((high quality, masterpiece, masterwork)) [[low resolution, worst quality, blurry, mediocre, bad art, deformed, disfigured, elongated, disproportionate, anatomically incorrect, unrealistic proportions, mutant, mutated, melted, abstract, surrealism, sloppy, crooked]]
Takoyaki on a plate 添加过多的括号可能会限制人工智能的填充能力,因此如果您发现图像出现故障,请尝试减少括号和反转的数量。
提示:如何快速编辑提示:
翻译 您喜欢用其他语言提示吗? 您可以使用 50 多种语言render images ,比如这样:
/render /translate un perro muy guapo <sdxl> 它不需要说明是哪种语言,它知道就行了。使用翻译时,避免使用俚语。如果人工智能不理解您的提示,可以尝试用更明显的词语重新表述。
翻译限制
一些地区俚语可能会被误解,因此在使用翻译功能时,应尽量按字面意思提示。例如,"cubito de hielo "在西班牙语中可以指小冰块,也可以指一桶小冰块,具体取决于地区和上下文的细微差别。
公平地说,这种情况在英语中也会发生,因为人工智能可能会把事情想得太简单。例如,一位用户要求狩猎一只北极熊, 人工智能却给了它一把狙击步枪 。恶意遵从!
为避免出现这种情况,请在正反面提示中使用多个词语。
RECIPE 宏观 食谱是提示模板。recipe 可以包含标记、采样器、模型、文本反转等内容。如果您发现自己的提示音中总是重复同样的内容,那么这就非常省时,值得学习。
当我们引入负倒置时,很多人问:"为什么不在默认情况下打开这些功能?"答案是control - 每个人都喜欢略有不同的settings 。我们的解决方案是食谱:召唤提示模板的标签。
要查看它们的列表,请键入 /recipes 或在我们的网站上浏览:提示模板主列表
/recipes 大多数食谱由community 创建,由于由其各自所有者管理,因此可能随时更改。一个提示符只能有一个recipe ,否则事情会变得很奇怪。
使用recipe 有两种方法。您可以使用标签来称呼它的名称,如 "快速 "recipe :
/render a cool dog #quick 一些受欢迎的食谱包括 #nfix 和 #eggs 以及 #boost 和 #everythingbad 和 #sdxlreal。
重要提示:在创建recipe 时,必须在正提示区的某个位置添加 $prompt,否则recipe 无法接受文本输入。您可以将其添加到任何地方,这很灵活。
在 "其他命令 "字段中,您可以堆叠下面的其他质量提升参数。
COMPOSE Compose 允许创建多提示、多区域。可用区域包括:背景、底部、底部中央、底部左侧、底部右侧、中央、左侧、右侧、顶部、顶部中央、顶部左侧、顶部右侧。 每个区域的格式为 x1、y1、x2、y2
/compose /size:2000x700 /left:The tower of Thai food /center:Jungles of Thailand, tropical rainforest [blurry] /right: Castle made of stone, castle in the jungle, tropical vegetation 另一个例子
/compose /seed:1 /images:2/size:384×960 /top:ZeldaKingdom GloomyCumulonimbus /bottom:1983Toyota Have a Cookie /guidance:5
提示:使用 5 左右的guidance 可以获得更好的混合效果。您还可以指定模型。Guidance 适用于整个图像。我们正在努力添加区域guidance 。
/compose /size:1000x2000 /top: Lion roaring, lion on top of building /center: Apartment building, front of building, entrance /bottom: Dirty city streets, New York city streets [[ugly]] [[blurry] /images:1 /guidance:7 BLEND (IP 适配器)
前提条件:请先掌握ControlNet 。
Blend 允许您从ControlNet 库中融合存储在images 的多个images 。这是基于一种名为 IP 适配器的技术。对大多数人来说,这是一个令人困惑的名字,所以我们称之为blend 。
首先,将一张照片粘贴到机器人中,创建一些预设图片concepts ,并按照ControlNet 的方法为其命名。 如果你已经保存了控件,也可以使用。
/control /new:chicken 有了两个或更多这样的网站后,您可以将它们blend 。
/render /blend:chicken:1 /blend:zelda:-0.4 提示:IP 适配器支持负images 。建议减去噪点图像,以获得更好的图像。
您可以使用 /blendnoise 设置图像的噪点control
默认值为 0.25。您可以使用 /blendnoise:0.0 将其禁用。
您还可以使用 /blendguidance 设置 IP 适配器效果的强度,默认值为 0.7。
提示:Blend 也可用于内绘和 SDXL 模型
详细说明 render 命令有许多强大的参数。一个常用的参数是After Detailer,又名 Adetailer
/render /adetailer a close-up photo of a gorilla jogging in the park <sdxl> 创建图像后,它将立即扫描图像,查找手、眼睛和脸部的缺陷,并自动修复。它适用于 SDXL 和 SD15(截至 24 年 3 月
限制:
在使用 "After Detailer "时,最好同时使用良好的正面和负面提示以及反转提示,具体说明如下:
免费 U FreeU (Free Lunch in Diffusion U-Net)是一个实验细节器 ,它在render 期间的四个不同时间间隔扩展guidance 范围。有 4 个可能的值,每个值介于 0-2 之间。
/render <av5> a drunk horse in Rome /freeu:1.1,1.2,0.9,0.2
图像创建命令 POLLY
Polly 是您的图像创作助手,也是撰写详细提示的最快方法。Fave 当您在 concepts Polly 会随机选择一个您最喜欢的模型。
要在 Telegram 中使用Polly ,请这样与它对话:
/polly a silly policeman investigates a donut factory回复将包含一个提示,您可以直接render ,或复制到剪贴板,与 /render 命令一起使用(解释如下)。
您也可以使用 /raw 开始常规聊天对话。
/polly /raw explain the cultural significance of japanese randoseru 您也可以登录my.graydient.ai, 点击Polly 图标,通过网络浏览器使用它。
BOTS
Polly 可以定制。您可以培训助理
/bots Bots 会显示你创建的助手列表。例如,如果我的助手是 Alice,我可以使用 /alicebot go make me a sandwich 这样的命令。 @piratediffusion_bot 必须与你在同一个频道。
要创建一个新的,请键入
/bots /new RENDER 如果不需要Polly 或自定义bots 的提示帮助,请切换到 /render 命令,完全手动操作。 尝试快速学习
/render a close-up photo of a gorilla jogging in the park <sdxl> The trigger word <sdxl> refers to a concept
内联正面、反面
正值 告诉人工智能要强调什么。这可以用(圆括号)来表示。每对括号代表正强化的 1.1 倍。反方 则用 [方] 括号表示。
/render <sdxl>
((high quality, masterpiece, masterwork)) [[low resolution, worst quality, blurry, mediocre, bad art, deformed, disfigured, elongated, disproportionate, anatomically incorrect, unrealistic proportions, mutant, mutated, melted, abstract, surrealism, sloppy, crooked]]
Takoyaki on a plate 添加过多的括号可能会限制人工智能的填充能力,因此如果您发现图像出现故障,请尝试减少括号和反转的数量。
提示:如何快速编辑提示:
翻译 您喜欢用其他语言提示吗? 您可以使用 50 多种语言render images ,比如这样:
/render /translate un perro muy guapo <sdxl> 它不需要说明是哪种语言,它知道就行了。使用翻译时,避免使用俚语。如果人工智能不理解您的提示,可以尝试用更明显的词语重新表述。
翻译限制
一些地区俚语可能会被误解,因此在使用翻译功能时,应尽量按字面意思提示。例如,"cubito de hielo "在西班牙语中可以指小冰块,也可以指一桶小冰块,具体取决于地区和上下文的细微差别。
公平地说,这种情况在英语中也会发生,因为人工智能可能会把事情想得太简单。例如,一位用户要求狩猎一只北极熊, 人工智能却给了它一把狙击步枪 。恶意遵从!
为避免出现这种情况,请在正反面提示中使用多个词语。
RECIPE 宏观 食谱是提示模板。recipe 可以包含标记、采样器、模型、文本反转等内容。如果您发现自己的提示音中总是重复同样的内容,那么这就非常省时,值得学习。
当我们引入负倒置时,很多人问:"为什么不在默认情况下打开这些功能?"答案是control - 每个人都喜欢略有不同的settings 。我们的解决方案是食谱:召唤提示模板的标签。
要查看它们的列表,请键入 /recipes 或在我们的网站上浏览:提示模板主列表
/recipes 大多数食谱由community 创建,由于由其各自所有者管理,因此可能随时更改。一个提示符只能有一个recipe ,否则事情会变得很奇怪。
使用recipe 有两种方法。您可以使用标签来称呼它的名称,如 "快速 "recipe :
/render a cool dog #quick 一些受欢迎的食谱包括 #nfix 和 #eggs 以及 #boost 和 #everythingbad 和 #sdxlreal。
重要提示:在创建recipe 时,必须在正提示区的某个位置添加 $prompt,否则recipe 无法接受文本输入。您可以将其添加到任何地方,这很灵活。
在 "其他命令 "字段中,您可以堆叠下面的其他质量提升参数。
COMPOSE Compose 允许创建多提示、多区域。可用区域包括:背景、底部、底部中央、底部左侧、底部右侧、中央、左侧、右侧、顶部、顶部中央、顶部左侧、顶部右侧。 每个区域的格式为 x1、y1、x2、y2
/compose /size:2000x700 /left:The tower of Thai food /center:Jungles of Thailand, tropical rainforest [blurry] /right: Castle made of stone, castle in the jungle, tropical vegetation 另一个例子
/compose /seed:1 /images:2/size:384×960 /top:ZeldaKingdom GloomyCumulonimbus /bottom:1983Toyota Have a Cookie /guidance:5
提示:使用 5 左右的guidance 可以获得更好的混合效果。您还可以指定模型。Guidance 适用于整个图像。我们正在努力添加区域guidance 。
/compose /size:1000x2000 /top: Lion roaring, lion on top of building /center: Apartment building, front of building, entrance /bottom: Dirty city streets, New York city streets [[ugly]] [[blurry] /images:1 /guidance:7 BLEND (IP 适配器)
前提条件:请先掌握ControlNet 。
Blend 允许您从ControlNet 库中融合存储在images 的多个images 。这是基于一种名为 IP 适配器的技术。对大多数人来说,这是一个令人困惑的名字,所以我们称之为blend 。
首先,将一张照片粘贴到机器人中,创建一些预设图片concepts ,并按照ControlNet 的方法为其命名。 如果你已经保存了控件,也可以使用。
/control /new:chicken 有了两个或更多这样的网站后,您可以将它们blend 。
/render /blend:chicken:1 /blend:zelda:-0.4 提示:IP 适配器支持负images 。建议减去噪点图像,以获得更好的图像。
您可以使用 /blendnoise 设置图像的噪点control
默认值为 0.25。您可以使用 /blendnoise:0.0 将其禁用。
您还可以使用 /blendguidance 设置 IP 适配器效果的强度,默认值为 0.7。
提示:Blend 也可用于内绘和 SDXL 模型
详细说明 render 命令有许多强大的参数。一个常用的参数是After Detailer,又名 Adetailer
/render /adetailer a close-up photo of a gorilla jogging in the park <sdxl> 创建图像后,它将立即扫描图像,查找手、眼睛和脸部的缺陷,并自动修复。它适用于 SDXL 和 SD15(截至 24 年 3 月
限制:
在使用 "After Detailer "时,最好同时使用良好的正面和负面提示以及反转提示,具体说明如下:
免费 U FreeU (Free Lunch in Diffusion U-Net)是一个实验细节器 ,它在render 期间的四个不同时间间隔扩展guidance 范围。有 4 个可能的值,每个值介于 0-2 之间。
/render <av5> a drunk horse in Rome /freeu:1.1,1.2,0.9,0.2
Concepts 概况 Concepts 是专门的人工智能模型,可生成仅靠提示无法很好理解的特定事物。多个concepts 可以一起使用:最常用的通常是一个基础模型和 1-3 个 LoRas 或反转模型。
您还可以通过启动培训网络界面来培训自己:
/makelora 关于定制罗拉和隐私的说明:
私人洛拉斯: 请始终使用与 @piratediffusion_bot 的私人对话中的/makelora 命令来制作只有您可以看到的 Lora。您也可以在私人子域中使用此命令,但它不会出现在 Stable2go 的共享实例或 MyGraydient 中的快速创建中。公共洛拉斯: 要训练并与整个community 分享您的 LoRa,请登录 my.graydient.ai,然后单击 LoRaMaker 图标。包括您的电报机器人在内的所有人都将看到这些 Loras。
模型系列 目前,我们的软件支持两个稳定扩散系列:SD15(旧版本,训练分辨率为 512×512)和 Stable Diffusion XL(原生分辨率为 1024×1024)。 接近这些分辨率将产生最佳结果(并避免重复肢体等)。
最重要的一点是,Families 不相互兼容。 SDXL 底座不能与 SD15 Lora 底座一起使用,反之亦然。
语法
型号列表
The term AI model can also mean chat models, so we call image models “concepts”. A concept can be a person, pose, effect, or art style. To bring those things into your creation, we call their “trigger word” which appear in angled brackets like this: <sdxl>
/concepts /concepts 命令的目的是在 Telegram 中以列表形式快速查找模型的触发词。在该列表的末尾,您还可以找到一个链接,以便 在我们的网站上 直观地浏览concepts 。
使用concepts
要创建图片,请将concept的触发词与render 命令配对(解释如下)并描述照片。
To use one, use it’s trigger name anywhere in the prompt. For example, one of the most popular concepts of the moment is called Realistic Vision 5 SDXL, a realistic “base model” — the basis of the overall image style. The trigger name for Realistic Vision 5 SDXL is <realvis5-xl> so we would then prompt.
/render a dog <realvis4-xl> 提示:选择 1 个基本模型(如 realvis4-xl)、1 或 3 个萝拉和一些负倒置来创建平衡的图像。添加过多或相互冲突的concepts (如 2 个姿势)可能会造成假象。尝试学习 或自己制作
搜索型号
您可以在 Telegram 上直接搜索。
/concept /search:emma 最新机型
快速回忆一下您最近尝试过的方法:
/concept /recent 最喜欢的模特
使用fave 命令在个人列表中跟踪并记住您最喜欢的模型
/concept /fave:concept-name 我的默认模型
Stable Diffusion 1.5 是默认模型,但为什么不将其替换为您的绝对首选模型呢?
This will impact both your Telegram and Stable2go account. After you do this command, you don’t have to write that <concept-name> every time in your prompts. Of course, you can override it with a different model in a /render.
/concept /default:concept-name
类型Concepts
基本模型也称为 "完整模型",它对图像的style 决定性最强。LoRas 和文本反转 是用于精细控制的较小模型。这些小文件只针对一个主题,通常是一个人或一个姿势。Inpainting 模型仅用于Inpaint 和 Outpaint 工具,不得用于渲染或其他用途。
特殊concept 标签
concepts 系统按标签组织,主题广泛,从动物到姿势应有尽有。
有一些特殊的标签称为 "类型",可以告诉您模型的行为方式。此外,还有一些可以替代正片提示和负片提示的标记,称为 "细节 "和 "负片"。使用负值concept 类型时,请记得将权重也设置为负值。
负倒置 模型系统有一种特殊的模型,叫做负反转,也叫负嵌入。这些模型有意在看起来很糟糕的images 上进行训练,以指导人工智能不要做什么。因此,将这些模型作为负模型调用,可以大大提高质量。这些模型的权重必须是双[[负括号]],介于-0.01 和-2 之间。
/render <sdxl> [[<fastnegative-xl:-2>]]
Takoyaki on a plate
具有 "Hyper "和 "Turbo "等听起来很快的名字的型号可以用较低的参数快速render images ,解释如下 Guidance / CFG .
除型号名称外的这些数字是 "重量"。
您可以通过调整模型的权重来control 模型对图像的影响程度。我们需要权重,因为模型是有主见的,所以它们会将图像拉向自己的训练方向。当添加多个模型时,如果它们的意见不一致,就会导致图像像素化和失真。为了解决这个问题,我们可以降低或增加每个模型的权重,以达到我们想要的效果。
权重规则
全型号不可调节。 也称为 检查点或基本模型,它们是决定整体美术style 的大型文件。要改变基础模型对美术的影响,我们只需将其切换到另一个基础模型。这就是为什么我们的系统中有这么多基本模型的原因。
LoRas 和文本反转具有灵活的权重。
将权重向正方向移动会使这些模型更加大胆。通俗地说,LoRas 是文本反演的更详细版本。
最佳做法
始终使用 1 个基本模型,然后添加罗拉和倒置。
加载多个基本模型不会blend ,只会加载一个,但会 "标记化 "已加载的其他模型,这意味着您只需键入它们的名称,就会发生同样的事情,而不会降低render 的速度(内存中的模型越少 = 速度越快)。
对于 LoRas 和 Inversions,你可以同时使用两种或多种,但大多数人坚持使用 1-3,因为这样更容易平衡。
对于 SDXL 用户,您会在系统中发现许多名为"-type "的标签。 这是一个模型子系列,在一起加载时效果最佳。在编写本指南时,最流行的类型是小马(并非字面意义上的小马),它具有更好的提示凝聚力,特别是对于性感的东西。小马洛拉斯最适合与小马基本模型搭配使用,以此类推。
正模型权重
权重的极限是-2(负值)和 2(最大值)。权重一般在 0.4 - 0.7 之间效果最佳。0.1 以上的数字与((正提示))的效果类似。有超过十位数的小数精度可供选择,但大多数人坚持使用一位数,这也是我们的建议。
负模型权重 (见上文的负反演)
可以对图像产生负面影响,从而获得净正面效果。
例如,有人训练了一组外形狰狞的人工智能手,并将其作为底片加载,创造出了一双漂亮的手。这个解决方案非常巧妙。在我们的系统中,你会发现许多类似的高质量黑客。 save 质量差]]的时间。 使用负值模型时,将权重滑动到负值,通常是-1 或-2。 它具有类似于[[负值提示]]的效果。
故障排除
使用多种型号就像同时播放多首歌曲:如果它们的音量(重量)都一样,就很难分辨出什么。
如果images 显得过于块状或像素化,请确保您使用的是基本模型,并且您的guidance 设置为 7 或更低,正片和负片也不要太强。尝试调整权重以找到最佳平衡。请在下面的指南中了解有关Guidance 和参数的更多信息。
参数
分辨率:宽度和高度
人工智能模型照片是在特定尺寸下 "训练 "出来的,因此创建接近这些尺寸的images 可产生最佳效果。如果我们过早尝试过大的尺寸,可能会导致故障(双胞胎、多余的肢体)。
指导方针
稳定的 Diffusion XL 型号:从 1024×1024 开始,低于 1400×1400 通常是安全的。 稳定扩散 1.5 在 512×512 下进行了训练,因此上限为 768×768。一些高级模型,如 Photon,可以在 960×576 下运行。更多 SD15 尺寸提示 您可以在接近 4K 的第二步上进行升频,请参阅下面的Facelift 升频器 信息。 语法
使用这些速记命令,您可以轻松改变图像的形状:/portrait /tall /landscape/wide
/render /portrait a gorilla jogging in the park <sdxl> 您也可以通过/size 手动设置分辨率。默认情况下,草稿images 的创建分辨率为 512×512。这样看起来会有点模糊,因此使用尺寸命令会让效果更清晰。
/render /size: 768x768 a gorilla jogging in the park <sdxl> 局限性:Stable Diffusion 1.5 是在 512×512 的尺寸下训练的,因此过大的尺寸会导致双头和其他突变。SDXL 是以 1024×1024 的尺寸训练的,因此 1200×800 这样的尺寸使用 SDXL 模型比使用 SD 1.5 模型效果更好,因为重复的可能性更小。如果您在使用/size 时出现重复主题,请尝试以 1 名女性/男性开始提示,并在提示结束时更详细地描述背景。尺寸 ,请使用升频技术 。
Seed
用于初始化图像生成过程的任意数字。这不是一个具体的图像(它不像数据库中的照片 ID),而更像是一个通用标记。seed 的目的是帮助重复图像提示。最初,Seed 是维护持久字符 的最佳方法,但现在已被Concepts 系统取代。
重复图像:Seed,Guidance,Sampler,Concepts 和提示符应相同。任何偏差都会改变图像。
SYNTAX
/render /seed: 123456 cats in space
Steps
人工智能对图像进行refine 的迭代次数,一般来说,steps 的次数越多,质量越高。当然,步数越多,处理速度越慢。
/render /steps:25 (((cool))) cats in space, heavens 将steps 设置为 25 是平均值。如果您没有指定steps ,我们默认设置为 50,这是一个高值。手动设置时,steps 的范围为 1 到 100,使用预设时,steps 的范围可高达 200。预设值有
waymore - 200steps, twoimages - 质量最佳 更多 -100steps, 三images 少 - 25steps, 六images 无路 - 15steps, 9images ! - 最适合草稿 /render /steps:waymore (((cool))) cats in space, heavens 虽然在每个render 上设置 /steps:waymore 可能很诱人,但这只会拖慢workflow 的速度,因为计算时间会更长。当您制作出最佳提示时,请调高steps 。或者,学习如何使用LCM sampler ,以最少的steps 得到最高质量的images 。过多的steps 也会损坏图像 。
例外情况
以前的建议是,工作温度高于 35steps 或更高,才能获得高质量的图像,但现在情况已不再总是如此,因为较新的高效机型 只需 4steps 就能产生令人惊叹的图像!
Guidance (CFG)
无分类器Guidance 标度是一个参数,用于控制人工智能在多大程度上遵循提示;数值越大,表示越遵循提示。
该值设置得越高,图像看起来就越清晰,但人工智能填充空间的 "创造力 "就越弱,因此可能会出现像素化和毛刺。
最常见的基本型号的安全默认值为 7。不过,也有一些特殊的高效机型使用不同的guidance 标度,具体说明如下。
SYNTAX
/render <sdxl> [[<fastnegative-xl:-2>]]
/guidance:7
/size:1024x1024
Takoyaki on a plate guidance 的设置高低取决于您使用的sampler 。下文将对采样器进行说明。允许 "解决 "图像的steps 数量也起着重要作用。
规则的例外情况
典型的机型遵循这种guidance 和步进模式,但新型高效机型所需的guidance 要少得多,在 1.5 - 2.5 之间。 下文对此进行了解释:
高效机型 低Steps, 低Guidance
大多数concepts 都需要 7 和 35 以上的guidance steps 才能生成出色的图像。随着更高效型号的出现,这种情况正在发生变化。
这些模型可以在 1/4 的时间内创建images ,只需要 4-12 个steps ,guidance 。您可以找到 标记为 Turbo、Hyper、LCM 和 Lightning 在concepts 系统中,它们与经典模型兼容。您可以将它们与同一型号系列的 Loras 和 Inversions 一起使用。SDXL 系列的选择最多(使用最右侧的下拉菜单)。Juggernaut 9 Lightining 是最受欢迎的选择。
Some of our other favorite Lightning models are <boltning-xl> and <realvis4light-xl> which look great with a guidance of 2, steps between 4-12, and Refiner (no fix) turned off. Polish it off with a good negative like [[<fastnegative-xl:-2>]]. Follow it up with an upscale, and the effects are stunning!
请查阅这些特殊型号的注释,了解更多使用细节,例如 Aetherverse-XL(如下图),guidance ,如下图所示,2.5 和 8steps 。
VASS(仅限 SDXL)
Vass 是 SDXL 的 HDRmode ,它还可以改善构图和降低色彩饱和度。有些人喜欢,有些人可能不喜欢。如果图像看起来过于艳丽,请尝试不使用 Refiner (NoFix)
这个名字来自独立研究员蒂莫西-亚历克西斯-瓦斯(Timothy Alexis Vass)。 发现了一些有趣的现象 .他的目标是色彩校正和改进images 的内容。我们对他发布的代码进行了改编,以便在PirateDiffusion 中运行。
/render a cool cat <sdxl> /vass 为什么以及何时使用:在 SDXLimages 上试用,如果照片太黄、偏离中心或色彩范围感觉有限。你会看到更好的鲜艳度和更干净的背景。
限制:此功能仅适用于 SDXL。
解析器和权重 软件中摄取提示信息的部分称为 "解析器"。 解析器对提示语的内聚力影响最大,即人工智能对您试图表达的内容和优先级的理解程度。
PirateDiffusion 有三种解析器模式:默认、LPW 和 Weights("新 "解析器)。它们各有优缺点,因此真正的选择取决于您的提示style 以及您对语法的看法。
MODE 1 - 默认解析器(最简单)
默认解析器提供了最大的兼容性和功能,但只能通过 77 个标记(逻辑构思或单词部分),然后 Stable Diffusion 才会停止关注长提示。为了表达重要内容,您可以添加(正面)和[负面]强化,如上一节所述(见正面)。这适用于 SD 1.5 和 SDXL。
长提示权重(试验性) 开启后,您可以写更长的正面和负面提示。观看视频演示 。
例如
((high quality, masterpiece, masterwork)) A wizard browsing through a magical marketplace with a mystical air around him. He has pointy ears, spectacles perched precariously on his nose, and a wand twirling in hsi hand. His robes are adorned with intricate patterns and patterns of magic dust. There is a bubbling magical cauldron, and mythical creatures peeking around from behind him.
这是一种提示语再平衡实用程序,它能让提示语的理解能力远远超过 77 个标记,从整体上提高提示语的理解能力。 当然,如果不是因为一些不幸的取舍,我们会将其作为标准:
局限性
需要较低的guidance 才能达到最佳效果,约为 7 或更低 LPW 不应与非常严厉的正面或负面提示相结合(((((This will break))))) [[[[so will this]]]] 与洛拉斯或反转效果不佳 concepts LPW 与Remix 工具 并非 100% 兼容 不能与LCM sampler 提示LENGTH
/render /lpw my spoon is too big, ((((big spoon)))) [small spoon], super big, massively big, you would not believe the size, and I've seen many spoons and let me tell you, this spoon in my hand, right here, is yuuuuge, the biggest spoon you'll ever see, and if anyone's said they've seen a bigger spoon, they're cheating, Big spoon, gigantic ladle, extra large serving bowl, oversized utensil, huge portion size, bulky kitchenware, impressive cooking tools, rustic table setting, hearty meals, heavyweight handle, strong grip, stylish design, handcrafted wooden piece, <coma2> 字数 解析器 "新 "又称提示权重
另一种提高提示语凝聚力的策略是为每个单词赋予 "权重"。 权重范围为 0 - 2,使用小数,类似于 LoRas。语法有点复杂,但为了达到令人难以置信的精确度,正负权重均可支持
/render /parser:new (blue cat:0.1) (green bird:0.2) [(blue cat:2), (red dog:0.1)] 要特别注意否定词,它们使用一对组合[( )]来表达否定。在上例中,"蓝猫 "和 "红狗 "就是否定词。此功能不能与 /lpw(上文)混合使用
CLIP SKIP
这一功能很有争议,因为它非常主观,而且不同车型的效果会有很大差异。
人工智能模型由多个层次组成,据说在第一层中包含了太多的一般信息(有些人可能会说是垃圾信息),导致了枯燥或重复的合成。
Clip Skip 背后的理念是忽略这些层中产生的噪音,直接切入重点。
/render /images:1 /guidance:8 /seed:123 /size:1024x1024 /sampler:dpm2m /karras <sdxl> huge diet coke /clipskip:2 从理论上讲,它可以增强凝聚力和提示意图。然而,在实践中,裁剪过多的图层可能会导致图像效果不佳。虽然这个问题还没有定论,但一种流行的 "安全 "设置是clipskip 2。
精炼机(仅限 SDXL)
细化器是一种去噪和平滑技术,建议用于绘画和插图。它能使images 更加平滑,色彩更加纯净。不过,有时会事与愿违。对于写实的images ,关闭细化器会使色彩和细节更加丰富,如下图所示。然后,您可以放大图像以减少噪点并提高分辨率。
SYNTAX
/render a cool cat <sdxl> /nofix 为什么以及何时使用:当图像看起来过于粗糙或肤色显得暗淡时。使用/highdef 或/facelift 等回复命令(如下)添加后期处理,使图像更加完美。
采样器
sampler (也称调度程序)是一种算法,它决定人工智能应如何在给定参数的情况下解决您的提示问题。最佳 "sampler 是非常主观的。
更多信息和比较images
LCM sampler 是一个例外,它专门用于在低guidance 和低steps 下进行渲染。
SAMPLER 命令和语法
要查看可用采样器列表,只需键入 /取样器
采样器是人工智能爱好者常用的一种调整功能,它们的作用如下。 采样器也叫噪点调度器。steps 的数量和您选择的sampler 会对图像产生很大的影响。即使在steps 较低的情况下,使用sampler (如 DPM 2++)和可选的mode "Karras",也能获得非常出色的图像。 有关比较,请参见采样器页面。
要使用它,请在提示符中添加以下内容
/render /sampler:dpm2m /karras a beautiful woman <sdxl> Karras 是一个可选的mode ,可与 4 个采样器一起使用。在我们的测试中,它可以产生更令人满意的结果。
LCM 在 Stable Diffusion 中代表 Latent Consistency Models(潜在一致性模型)。 通过将images 与较低的steps 和guidance 堆叠使用,可以更快地得到 的结果。虽然它可以大批量快速生成令人惊叹的images ,但其代价是速度高于质量。
/render /sampler:lcm /guidance:1.5 /steps:6 /images:9 /size:1024x1024 <realvis2-xl> /seed:469498 /nofix Oil painting, oil on board, painted picture Retro fantasy art by Brom by Gerald Brom ((high quality, masterpiece,masterwork)) [[low resolution,m worst quality, blurry, mediocre, bad art, deformed, disfigured, elongated, disproportionate, anatomically incorrect, unrealistic proportions, melted, abstract, surrealism, sloppy, crooked, skull, skulls]] Closeup Portrait A wizard stands in an alien landscape desert wearing wizards robes and a magic hat 提示: 使用 SDXL 时,请添加 /nofix 以禁用细化器,它可能有助于提高质量,尤其是在进行以下操作时/more
它适用于 SD 1.5 和 SDXL 型号。请在guidance 介于 2-4 和steps 介于 8-12 之间时试用。 请进行试验,并在 Patreon 会员专区的 VIP 提示工程讨论组中分享您的发现。
不同型号会有差异,但即使 /guidance:1.5 /steps:6 /images:9 也能在 10 秒内返回良好的 SDXL 结果!
/render
/size:1024x1024
<airtist-xl> [[<fastnegative-xl:-2>]]
/sampler:lcm
/guidance:1.5
/steps:6
/nofix
/vae:madebyollin__sdxl-vae-fp16-fix
((high quality, masterpiece,masterwork)) [[low resolution, worst quality, blurry, mediocre, bad art, deformed, disfigured, elongated, disproportionate, anatomically incorrect, unrealistic proportions, mutant, mutated, melted, abstract, surrealism, sloppy, crooked]]
Takoyaki on a plate 在上面的示例中,创建者使用的是特殊的LCM sampler ,可以创建非常低的guidance 和低的steps ,但仍然可以创建非常高质量的images 。将此提示与类似内容进行比较:/sampler:dpm2m /karras /guidance:7 /steps:35
VAE 覆盖 VAE 代表变异自动编码器(Variational AutoEncoder),它是软件的一部分,对图像的色彩有很大影响。对于 SDXL,目前只有一个梦幻般的VAE 。
VAE 是一种特殊的模型,可用于改变对比度、质量和色彩饱和度。如果图像看起来雾蒙蒙的,而您的guidance 设置为 10 以上,那么VAE 可能就是罪魁祸首。VAE 是 "变异自动编码器 "的缩写,是一种对images 进行重新分类的技术,类似于压缩文件压缩和还原图像的方式。VAE 根据图像所接触的数据而不是离散值对图像进行 "再水化"。如果您的所有渲染images 都出现不饱和、模糊或紫斑,那么更改VAE 是最好的解决方案。(也请通知我们,以便我们在默认情况下设置正确的值)。16 位VAE 运行速度最快。
语法
/render #sdxlreal a hamster singing in the subway /vae:GraydientPlatformAPI__bright-vae-xl
可用的预设VAE 选项:
/vae:GraydientPlatformAPI__bright-vae-xl
/vae:GraydientPlatformAPI__sd-vae-ft-ema
/vae:GraydientPlatformAPI__vae-klf8anime2
/vae:GraydientPlatformAPI__vae-blessed2
/vae:GraydientPlatformAPI__vae-anything45
/vae:GraydientPlatformAPI__vae-orange
/vae:GraydientPlatformAPI__vae-pastel
第三方VAE :
上传或在 Huggingface 网站上找到一个设置了此文件夹目录的文件:
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix
然后替换斜线并删除 URL 前面的部分,就像这样:
/render whatever /vae:madebyollin__sdxl-vae-fp16-fix
vae 文件夹必须具备以下特征:
如上图所示,在 Huggingface 配置文件的顶级文件夹中,每个文件夹只有一个VAE
文件夹中必须包含 config.json
文件必须是 .bin 格式
bin 文件必须命名为 "diffusion_pytorch_model.bin"。
从哪里可以找到更多:Huggingface 和 Civitai 可能还有其他文件,但必须转换为上述格式
对于 SD15,我们有很多选择。以下是一个人对其差异的不科学看法:
kofi2 - 色彩丰富,饱和度高
祝福2 - 饱和度低于科菲2
anything45 - 饱和度低于 blessed2
橙色--中等饱和度,浓郁的绿色
粉彩--色彩鲜艳,像古老的荷兰绘画大师
ft-mse-840000-ema-pruned - 非常逼真
故障排除: 某些VAE 与某些基本型号不兼容。这将导致两种故障:
绿色霓虹灯漏光 (或)黑色方块,如果出现这种情况,请尝试另一个VAE 。
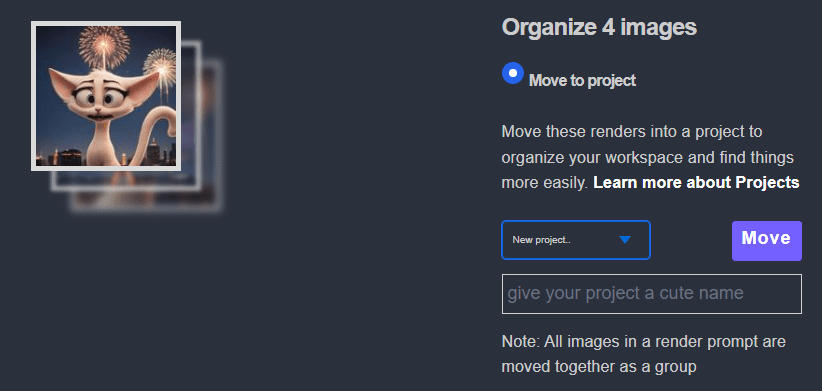
项目
您可以在 UnifiedWebUI 和PirateDiffusion Telegram 中直接将images render 到项目文件夹中。
Telegram 和 API 方法:
/render my cool prompt /project: xyz 网络方法:
首先,在您的 @piratediffusion_bot 中render 一张图片来启动您的项目
启动我的Graydient > 我的Images
选择images
单击 "组织
单击项目下拉菜单
为项目命名
移动您的第一个images
继续查看本指南底部与 / 项目相关的命令
ControlNet 经由PirateDiffusion
控制网是用于引导最终图像的图像到图像模板。不管你信不信,你都可以在 Telegram 中使用Controlnet ,而无需浏览器,不过我们同时支持浏览器和控制网。
您可以提供一个起始图像作为模版,选择mode ,并通过正负提示改变源图像的外观。您可以使用重量滑块control 效果。输入images 在 768×768 或 1400×1400 之间效果最佳。
目前支持的模式有轮廓、深度、边缘、手部、姿势、参考、分段、骨架和facepush ,每种模式都有子参数。更多示例
查看controlnet 已保存的预置
/control
制作ControlNet 预设值
首先,上传一张图片。然后用这条命令 "回复 "该图片,并给它起一个类似 "myfavoriteguy2 "这样的名字
/control /new:myfavoriteguy2
控制网对分辨率很敏感,因此会将图片分辨率作为名称的一部分来回应。因此,如果我上传一张威尔-史密斯的照片,机器人就会回复 will-smith-1000×1000 或我的图片尺寸。这可以帮助你记住以后的目标尺寸。
调用ControlNet 预设值
如果您忘记了预置的功能,请使用 show 命令查看:/control 或查看特定预置:
/control /show:myfavoriteguy2
使用ControlNet 模式
control guidance 的(新)速记参数是 /cg:0.1-2--控制render 与给定controlnet mode 的粘合程度。最佳值为 0.1-0.5。 也可以用老方法写成 /controlguidance:1
交换面孔 换脸 "也可作为回复命令使用。你还可以使用这个方便的换脸 (roop, insightface)功能来更换上传图片中的人脸。 首先为图片创建control ,然后添加第二张图片来交换面孔
作为回复命令(右键单击任何模型的成品图像)
/faceswap myfavoriteguy2facelift 也支持/strength 参数,但其工作方式与你所期望的不同:
/faceswap /strength:0.5 myfavoriteguy2
如果您将/strength 设置为小于 1,它将 *blend*"之前的图像 "与 "之后的图像"--字面上是blend ,就像在 photoshop 中使用 50%的不透明度一样(如果强度为 0.5)。 原因是 因为底层算法并不像你想象的那样有 "强度 "设置,所以这是我们唯一的选择。
推脸 换脸(如上所述),但作为render-time 命令称为 "推脸"。
您也可以在某种程度上使用我们的 FaceSwap 技术(类似于 LoRa),但这只是一种节省时间的换脸方式。它没有权重,也没有太大的灵活性,但它会在新的render 中找到每张真实的脸,并将images 换成 1 张脸。请使用与ControlNet 相同的预设名称来使用它。
/render a man eating a sandwich /facepush: myfavoriteguy2
Facepush 局限性
Facepush 仅适用于 Stable Diffusion 1.5 模型,且检查点必须真实。它不适用于 SDXL 模型,也可能不适用于/more 命令或某些高分辨率。此功能还在试验阶段。如果您在使用 /facepush 时遇到问题,请尝试渲染您的提示,然后在图像上执行/faceswap 。它会告诉你图像是否不够逼真。有时可以通过使用 /facelift 来锐化目标来解决这个问题。/more 和 /remix 可能无法像预期的那样工作(目前还不行)。
高档工具(各种)
提升像素和细节
将图像的细节增加 4 倍,还能去除照片上的线条和瑕疵,类似于智能手机相机上的 "美颜 "mode 。逼真照片和艺术品模式。 更多信息
高分辨率
HighDef 命令(又称 "高分辨率修复")是一种快速像素倍增器。 只需回复图片即可提高像素。
/highdef
highdef 命令没有参数,因为/more 命令可以做HighDef 所做的事情,甚至更多。这里只是为了方便您使用。想要了解更多control 的专业人士,请返回上一页查看/more 视频教程。
在使用 /highdef 或/more 命令后,您可以按照下面的说明再次进行缩放。
UPSCALERS
Facelift 用于拍摄逼真的肖像照片。
您可以使用介于 0.1 和 1 之间的/strength 来control 效果。如果没有指定,默认值为 1。
/facelift
/facelift 命令还能让您访问我们的升级程序库。 添加这些参数,control 效果:
Facelift 是第 2 阶段升频器。在使用Facelift 之前,应先使用HighDef 。这是一般的升频命令,有两个作用:增强面部细节和 4 倍像素。它的工作原理类似于智能手机上的美图mode ,这意味着它有时会对面部进行喷砂处理,尤其是插图。 幸运的是,它还有其他操作模式:
/facelift /photo
这将关闭面部修饰,适合拍摄风景或自然肖像
/facelift /anime
尽管名字如此,它并不只是用于anime - 用它来增强任何插图的效果
/facelift /size:2000x2000
限制:Facelift 会尝试将图片放大 4 倍,最大可达 4000×4000。Telegram 通常不允许这种尺寸,而且如果您的图片已经是高清的,尝试 4 倍大小很可能会耗尽内存。 如果图片过大且没有返回,请尝试输入/history 从网页界面抓取,因为 Telegram 有文件大小限制。或者,使用如上所示的大小参数,在放大时使用较少的内存。
REFINE
Refine 是为了让你在 Telegram 之外的网页浏览器中编辑文本。提高生活质量。
您订购的服务同时包含 Telegram 和 Stable2goWebUI 。 refine 命令可让您在 Telegram 和网页界面之间切换。这对于在网页浏览器中快速更改文本(而不是复制/粘贴)非常有用。
/refine
WebUI 默认在Brew mode 启动。单击 "高级 "切换到Render 。
Remix 工具
图像到图像的转换
remix 工具非常神奇。使用Remix 工具,可以在concept 的艺术style 中转换上传或渲染的图像。您还可以使用输入的照片作为参考图片,对不同的主题进行大幅修改。
SYNTAX
Remix 是图像到图像style 传输命令,也称为重新提示命令。
Remix 需要输入一幅图像,它会破坏图像中的每一个像素,创建一幅全新的图像。它与/more 命令类似,但可以通过另一个模型名称和提示来更改图像的艺术style 。
Remix 是第二受欢迎的 "回复 "命令。 字面意思是回复照片,就像你要与照片对话一样,然后输入命令。 此示例会将您从任何艺术style 开始,切换到称为第 4 层的基本模型。
/remix a portrait <level4> 您可以使用 /remix 上传照片,它将完全改变照片。要保留像素(比如不改变脸部),可以考虑使用Inpaint 绘制蒙版 。
用途:Style 转让和创意 "高档"
您还可以使用remix 工具将低分辨率的images 重新诠释成新的东西,例如将低分辨率的视频游戏照片变成现代写实的images ,或将自己变成漫画或anime 插图。本视频将向你展示如何操作:
更多工具(回复命令)
更多 "工具可创建同一图像的各种变体
要查看同一主题的不同变化,请使用 "更多 "工具。
引擎盖下发生了什么?seed 值会增加,guidance 会随机化,同时保留您的原始提示。 局限性: 在使用高效模型 时,它可能会过度使用guidance 。
要使用更多命令,只需右击图片即可回复,就像与人交谈一样。回复命令用于操作images 和检查信息,如 IMG2IMG 或查找原始提示。
更多语法
more 是最常用的回复命令。在回复已由提示符生成的图片时,它会返回类似的images 。/more 命令对上传的图片不起作用。
/more more 命令比看上去更强大。它还可以接受强度(Strength)、Guidance 和大小(Size),因此您也可以将它用作第二阶段的升频器,尤其适用于稳定扩散 1.5 模型。请观看视频教程来掌握它。
上色工具
又名生成填充
Inpainting 是一种遮罩工具,可以在某个区域周围绘制遮罩,并在其中提示新的内容,或者像魔法橡皮擦一样移除对象。inpaint 工具有自己的正反面提示框,也接受以下触发代码 concepts .
注:自本视频发布以来,我们的软件已经更新,但相同的原则仍然适用。
VIDEO
生成填充,又称内画 Inpaint 可用于更改照片上的斑点区域。与 After Detailer 不同的是,inpaint 工具允许你选择并遮盖要更改的区域。
该工具有一个图形用户界面--它与Stable2go 集成。Inpaint 打开一个网页浏览器,您可以在图片上涂画,创建一个可提示的遮罩区域。可以在上传的非 AI 照片(改变手、天空、发型、衣服等)以及 AIimages 上进行涂画。
/inpaint 萤火虫在夜晚嗡嗡作响
在图形用户界面中,该工具的下拉菜单中有一些特殊的、特定的艺术风格(inpaint 模型),请不要忘记选择其中一种。.使用强度和guidance 来control 效果,其中强度仅指您的inpaint 提示。
/inpaint /size:512x768 /strength:1 /guidance:7 fireflies at (night)
提示:尺寸将继承自原始图片,建议使用 512×768。建议指定一个尺寸,否则默认为 512×512,可能会挤压图像。如果图像中的人物距离较远,其面部可能会发生变化,除非图像的保真度较高。
您还可以反向inpaint ,例如首先使用/bg 命令自动去除图像的背景,然后提示更改背景。 要做到这一点,请从/bg 结果中复制遮罩 ID。 然后使用 /maskinvert 属性
/inpaint /mask :IAKdybW /maskinvert 夜空中行星和彗星飞驰而过的壮丽景色
OUTPAINT 又名画布ZOOM 和平移
最新版本 (FLUX)
使用与inpaint 相同的规则展开任何图片,但没有图形用户界面,因此我们必须指定一个触发词,才能使用哪种艺术style 。 您可以用插槽值指定它的方向
/workflow /run:zoomout-flux fireflies at night
方向性CONTROL
您可以使用槽值逆时针添加填充。因此 slot1 = TOP
/workflow /run:zoomout-flux fireflies at night /slot1 :200 /slot2:50 /slot3:100 /slot4:300
旧版本(SDXL)
使用与inpaint 相同的规则展开任何图片,但没有图形用户界面,因此我们必须指定一个触发词来指定使用哪种艺术style 。外绘使用完全相同的inpaint 模型。通过浏览模型页面或使用
您可以查看/concept /喷漆的机型。
/outpaint fireflies at night <sdxl-inpainting>
Outpaint 还有其他参数。使用顶部、右侧、底部和左侧来control 画布的展开方向。如果不使用side,画布会向四个方向均匀展开。您还可以添加背景blur 虚化 (1-100)、zoom 因子 (1-12) 和原始区域收缩 (0-256)。添加强度以控制它。
/outpaint /side:top /blur:10 /zoom:6 /contract:50 /strength:1 the moon is exploding, fireworks <sdxl-inpainting>
可选参数
/side:bottom/top/left/right - 如果不添加此命令,您可以指定一个方向来展开图片,或者同时展开四个方向的图片。
/blur:1-100 - 模糊原始区域和新添加区域之间的边缘。
/zoom:1-12 - 影响整幅图片的比例,默认设置为 4。
/contract:0-256 - 使原始区域小于绘制后的区域。默认设置为 64。
提示:为了获得更好的效果,每次使用 Outpaint 时都要更改提示,并在新扩展的区域中只包含您想看到的内容。复制原始提示不一定能达到预期效果。
移除 BG 工具
快如闪电的背景扫描
使用背景移除工具,只需一步就能轻松消除主体后面的一切。Images 800×800 左右的分辨率效果最佳。您还可以使用内画工具 (如上图)遮盖并提示新的背景。
后台移除命令 要移除现实背景,只需回复/bg
/bg 对于任何类型的插图,添加此anime 参数后,移除效果会变得更清晰
/bg /anime 您还可以添加 PNG 参数来download 未压缩的图像。默认情况下,它会返回高分辨率的 JPG 图像。
/bg /format:png 您还可以使用十六进制颜色值来指定背景颜色
/bg /anime /format:png /color:FF4433 您还可以单独download 面具
/bg /masks
提示:如何处理遮罩?只提示背景!但不能一步到位。首先用 /showprompt 回复遮罩,以获取用于内绘的图像代码,或从内绘最近的遮罩中选取。在制作render 时,将 /maskinvert 添加到背景而不是前景。
背景替换
您还可以使用ControlNet style 命令 来交换预设背景:
上传背景或render 用 /control /new 回复背景照片:卧室(或任何房间/区域) 上传或render 目标图像,即接收存储背景的第二张图像 使用/bg /replace:Bedroom /blur:10 回复目标 blur 参数范围在 0-255 之间,用于控制主体与背景之间的羽化程度。 当整个主体都在视图中时,背景替换效果最佳,这意味着身体或物体的某些部分没有被其他物体遮挡。 这样可以防止图像浮动或产生不真实的背景包裹。
旋转物体 您可以旋转任何图像,就像旋转 3D 物体一样。首先用/bg
/spin 删除背景后,旋转效果最佳。Spin 命令支持 /guidance 。我们的系统会随机选择guidance 2 - 10。如需更多细节,还可添加 /steps:100
描写 已更新! 现在有两种描述模式:CLIP 和 FLORENCE2
利用 Describe 的计算机视觉功能,从任何图像中生成提示! 这是一个 "回复 "命令,所以请右键单击图像,就像要与图像对话一样,然后写下
/describe /florence
附加的Florence 参数可提供更详细的提示。/describe 本身使用的是 CLIP 模型。
示例
在PirateDiffusion
您可以创建预设按钮,无需学习如何编写代码,即可轻松创建按钮。我们的 Widgets 系统使之成为可能。只需在电子表格中填写您的提示模板,并将其连接到您的机器人。 例如,我们提供了一个制作widget 角色的模板:
小工具可同时创建 Telegram 和WebUI ,让你同时享受这两种功能! 观看 视频 和download 模板 开始创建。无需编码!
文件和队列管理 取消 使用/cancel 终止正在渲染的内容
/cancel DOWNLOAD 您在 Telegram 中看到的images 使用的是 Telegram 内置的图像压缩器。
/download 如果download 请求password ,请参阅本 "秘籍 "中的 "私人图库共享和密码 "部分。
删除 删除images 有两种方法:从本地设备删除,或从云驱动器永久删除。
要从本地设备上删除images 但保留在云端硬盘上,请使用 Telegram 内置的删除功能。长按图片(或在电脑上右击图片)并选择删除。
使用/delete 回复图像,将其从云驱动器中抹除。
/delete 您也可以键入 /webui 并启动我们的文件管理器,然后使用整理命令一次性批量删除images 。
历史 在指定的 Telegram 频道中查看您最近创建的images 。 在公共群组中使用时,它只会显示您在该公共频道中创建的images ,因此/history 对您的隐私也很敏感。
/history SHOWPROMPT 比较 要查看图像的提示,请右键单击该图像并键入 /。showprompt
/showprompt 通过这个便捷的命令,您可以查看图像是如何制作的。它会显示对图像进行的最后一次操作。要查看完整的历史记录,请这样写 /showprompt /history
showprompt 输出中内置了一个图像对比工具。 点击该链接,该工具将在浏览器中打开。
剪辑 /showprompt 命令会给出人工智能图像的准确提示,但非人工智能images 呢?
我们的/describe 命令将利用计算机视觉技术为您上传的任何照片编写提示。
/describe /describe 使用的语言有时会让人感到好奇。例如,"rafed "的意思是有趣或活泼的人。
巴新 默认情况下,PirateDiffusion 会以近乎无损的 JPG 格式创建images 。您也可以将images 创建为更高分辨率的 PNG 而不是 JPG。警告:这将占用 5-10 倍的存储空间:这会占用 5-10 倍的存储空间。不过,有一个问题。Telegram 无法原生显示 PNG 文件,因此在创建 PNG 后,请使用 /download 命令(如上)查看。
/render a cool cat #everythingbad /format:png 向量 将图像转换为 SVG/矢量!将生成或上传的图像回复为trace 的矢量图,特别是 SVG。矢量图images 可以无限缩放,因为它们不像普通images 那样用光栅化像素渲染;因此你可以看到清晰锐利的边缘。非常适合印刷、产品等。如果要创建徽标或贴纸,请使用/bg 命令。
/trace 下面列出了所有可用选项。我们还不知道哪些是可选的,所以请在 VIP 聊天室分享您的发现,帮助我们得出一个好的默认值。
speckle - 整数 - 默认值 4 - 范围 1 ... 128 - 丢弃大小小于 X px 的修补码 color - 默认 - 设置图像颜色 bw - 使图像黑白相间 mode - 多边形、样条线或无 - 默认样条线 - 曲线拟合mode 精度 - 整数 - 默认值 6 - 范围 1 ... 8 - 在 RGB 通道中使用的有效位数 - 即以更多 "斑点 "为代价获得更高的色彩保真度 gradient - 整数 - 默认值 16 - 范围 1 ..128 -gradient 图层之间的色差 corner - 整数 - 默认值 60 - 范围 1 ... 180 - 可被视为瞬时角度的最小值(度)。corner length - 浮点数 - 默认值 4 - 范围 3.5 ... 10 - 执行迭代平滑细分,直至所有线段都短于此值length 带有可选微调参数的示例trace :
/trace /color /gradient:32 /corner:1 网页界面文件管理器 便于在浏览器中管理文件,并快速查看模型的可视化列表。
/webui 请查看本页顶部的账户部分,了解password 命令等信息。
RENDER 进展情况MONITOR Telegram 有时难免会出现连接问题。如果你想知道我们的服务器是否正在发送images ,但没有发送到 Telegram,请使用此命令。您可以通过render 从云端硬盘提取您的images 。
/monitor 如果 /monitor 无效,请尝试 /start。这会给机器人一个提示。 PING "是我们宕机了,Telegram宕机了,还是队列忘了我? /ping 试图一目了然地回答所有这些问题
/ping 如果 /ping 无效,请尝试 /start。这会给机器人一个提示。
SETTINGS 您可以覆盖机器人的默认配置,例如只选择特定的sampler,steps, 还有一个非常有用的配置:将您最喜欢的基本模型设置为稳定扩散 1.5
/settings 可用settings:
装载量 settings 命令还会在响应的底部显示您的装载情况。
通过保存载荷,让切换工作流程变得更容易。例如,您可能有一个首选的基本模型和sampler ,用于anime ,也可能有一个不同的模型和 ,用于逼真度,或用于特定项目或客户的其他settings 。 Loadouts 可让您在瞬间更换所有settings 。
例如,如果我想按原样save 我的settings ,我可以起一个名字,比如 Morgan's Presets Feb 14:
/settings /save:morgans-presets-feb14 管理您的装载:
SILENT MODE 调试信息(如确认重复提示)是否过于冗长? 您可以使用此功能让机器人完全silent 。 只要别忘了打开这个功能,否则你会以为机器人不理你,它甚至不会告诉你render 的预计时间或任何确认信息!
/settings /silent:on 要重新开启,只需将 "开启 "改为 "关闭 "即可
过时和试验性 这是一个实验集,仍支持旧命令,但已被新技术取代。这些命令很难推荐用于生产,但使用起来仍然很有趣。
美学评分
美学 "是一个实验性选项,可在渲染图像时启用美学评估模型,作为渲染过程的一部分。现在Graydient API 中也提供了这一功能。
这些机器学习模型试图以数字方式对图像的视觉质量/美感进行评分
/render a cool cat <sdxl> /aesthetics 它返回 1-10 分的美学("美观")分数和 1-5 分的人工痕迹分数(低者为佳)。要了解什么被认为是好的或坏的,请看这里的数据集 。 该分数也可以在 / 中查看。showprompt
BREW
Brew 替换为 /polly. (用于添加随机效应)。
/brew a cool dog = /polly cool dog
返回相同的结果。
MEME
我们添加这个是开玩笑的,但它仍然有效,而且非常搞笑。您可以将 Internet Huge IMPACT 字体备忘录文本添加到图片的顶部和底部,每次添加一个部分。
/meme /top:One does not simply
(下一轮)
/meme /bottom:走进魔多
指导 PIX 2 PIX
取而代之的是Inpaint、外涂漆和Remix
这是当时的热门技术,名为 Instruct Pix2Pix,即 /edit 命令。回复这样的照片
/为天空添加烟花
使用自然语言向images 的景观和自然提出 "如果 "style 问题,以了解变化情况。 虽然这项技术很酷,但 Instruct Pix2Pix 产生的结果分辨率很低,因此很难推荐。它还被锁定在自己的艺术style 上,因此与我们的concepts 、loras、嵌入式等不兼容。 它的分辨率锁定在 512×512。如果您正在制作 lewds 或anime ,那么使用它是错误的。请使用 /remix 。您还可以使用强度参数control 效果。
/edit/strength:0.5 如果建筑物着火了怎么办?
风格
样式 "已被功能更强大的 "食谱 "系统取代。 样式用于制作个人提示快捷方式,不用于共享。您可以使用复制命令与他人交换样式,但如果不知道这些代码,它们将无法工作。我们的用户发现这一点令人困惑,因此配方是全局性的。要了解这项功能,请键入
/styles
本页对您有帮助吗?