Pirate Diffusionby Graydient AI is the most powerful bot on Telegram. It is a multi-modal bot, meaning that it handles large language models like DeepSeek and Llama 3.3, tens of thousands of image models like HiDream, Chroma, FLUX, Stable Diffusion 3.5, AuraFlow, Pony, and SDXL and also video models like Wan, Hunyuan and LightTricks (LTX).
놀라운 가치
PirateDiffusion 은 로열티 없이 무제한으로 사용할 수 있도록 설계되었으며, Graydient의 webUI 과 번들로 제공됩니다.
봇을 사용하는 이유는 무엇인가요?
모바일에서 매우 빠르고 가벼우며, 혼자 또는 낯선 사람이나 친구들과 함께 그룹으로 사용할 수 있습니다. 저희 community 에서 강력한 ComfyUI 워크플로우를 위한 채팅 매크로를 만들고 있으므로 간단한 채팅 봇으로 데스크톱 렌더링 결과의 모든 이점을 누릴 수 있습니다. 정말 대단하죠.
그 밖의 기능은 무엇인가요?
Images, 동영상 및 LLM 채팅을 지원합니다. 거의 모든 것을 할 수 있습니다.
GUI 없이 몇 번의 키 입력만으로 4K images 만들 수 있습니다. 채팅을 통해 모든 주요 Stable Diffusion 기능을 사용할 수 있습니다. 일부 기능에는 시각적 인터페이스가 필요하며, 해당 기능을 위한 웹 페이지가 팝업으로 표시됩니다(통합 WebUI 통합).
개인 봇으로 직접 만들거나 그룹에 가입하여 다른 사람들이 무엇을 만들고 있는지 살펴보세요. 또한 PollyGPT LLM을 StableDiffusion 모델에 연결하는 /animebot과 같은 테마의 bots 를 만들고 채팅을 통해 제작에 도움을 받을 수 있습니다! 로드아웃, recipe (매크로) 위젯(비주얼 가이 빌더), 커스텀 bots 을 사용하여 나만의 workflow 을 만들어 보세요. 많은 기능을 제공합니다!
오리진 스토리
Pirate Diffusion 이라는 이름은 2022년 10월에 유출된 Stable Diffusion 1.5 모델에서 따온 것입니다. 오픈 소스. 저희는 텔레그램에 첫 번째 스테이블 디퓨전 봇을 만들었고, 수천명의 사람들이 참여하여, 그렇게 시작하게 되었습니다. 하지만 명확히 말씀드리자면, 불법복제는 전혀 없으며, 단지 그 이름이 마음에 들었을 뿐입니다. 하지만, 많은 사람들이 (그리고 저희 은행에서도) 이름이 너무 많다고 말해서 회사 이름을 "Graydient"로 변경했지만, 저희는 Pirate Diffusion 이 재미있고 흥미로운 사람들을 끌어들이는 이름이라고 생각합니다.
플러스 회원을 위한 무제한 동영상 생성이 시작되었습니다!
Graydient동영상 요금제 회원인 경우 사용할 수 있는 다양한 동영상 워크플로가 있습니다. 동영상 워크플로에는 프롬프트를 동영상으로 전환하는 것과 기존 사진을 동영상으로 전환하는 두 가지 일반적인 카테고리가 있습니다. (향후에는 비디오 대 비디오 기능을 추가할 예정입니다. 아직 제공되지 않습니다.)
Text to music – two modes!
AUTOMATIC LYRICS
/makesong Write a song about being in the face by a California Rattlesnake. Incorporate "dirty sanchez" and "Roosevelt Hoover"
MANUAL LYRICS
We plan to offer multiple music workflows. The first is called “music-ace” and it works like this:
/workflow /run:music-ace [verse] gonna make some songs [bridge] gonna make em [chorus] with pirate diffusion yeah!
먼저 워크플로 페이지를 탐색하여 텍스트와 동영상의 짧은 이름을 찾아보세요. 인기 있는 것은 다음과 같습니다:
WAN 2.1 - 현재 최고의 오픈 소스 비디오 모델, 간단한 프롬프트를 작성하면 실행됩니다! WAN은 훈위안보다 프롬프트 밀착도와 애니메이션이 더 나은 것으로 보이지만, 해부학적 구조는 더 나쁩니다.
보링비디오 - 아이폰에서 촬영한 것처럼 생생한 일반 동영상을 제작합니다.
훈위안 - 세 가지 유형이 있으며, workflow 페이지 하단에서 찾을 수 있습니다. 훈위안은 가장 사실적인 동영상을 제작합니다. "Q" 숫자가 높을수록 화질이 좋지만 동영상의 길이가 짧아집니다.
비디오 - 간단히 비디오라고 불리는 것은 3D 만화에 적합한 LTX 라이트트릭을 사용합니다.
/wf /run:video-hunylora-q8 cinematic low angle video of a ronald mcdonald clown eating a square hamburger, the restaurant ((sign text says "Wendys")), ronald mcdonald's clown costume has red afro hair and a red nose with white face paint, the restaurant is brown, the burger is pointy and square, the background has blur bokeh and people are walking around
PirateDiffusion 훈위안과 라이트트릭스/LTX 동영상과 로라를 지원합니다! 여러 비디오 모델을 추가하고 있으며 무제한 이미지 및 무제한 로라 교육과 함께 서비스의 일부로 무제한으로 사용할 수 있습니다.
LTX에서는 프롬프트의 구조가 매우 중요합니다. 프롬프트가 짧으면 정적인 이미지가 생성됩니다. 프롬프트에 동작과 지침이 너무 많으면 비디오가 다른 임의의 방이나 캐릭터로 이동하게 됩니다.
모범 사례: images 을 일관성 있게 운영하는 방법
다음과 같은 프롬프트 패턴을 권장합니다:
먼저 카메라가 무엇을 하고 있는지 또는 누구를 팔로우하는지 설명하세요. 예를 들어 로우 앵글 카메라 zoom, 오버헤드 카메라, 슬로우 팬, 줌아웃 또는 원거리 등입니다.
다음으로 대상과 그들이 무엇을 또는 누구에게 하는 행동 한 가지를 설명합니다. 이 부분은 연습이 필요합니다! 위의 예에서 로널드가 햄버거를 먹는 장면은 카메라와 장면 설정 이후에 나온 것을 볼 수 있습니다.
장면을 설명합니다. 이렇게 하면 AI가 사용자가 보고 싶은 것을 '세그먼트화'하는 데 도움이 됩니다. 이 예에서는 광대 의상과 배경을 설명합니다.
참고 자료를 제시하세요. 예를 들어 "이것은 영화나 TV 쇼의 한 장면처럼 보입니다"라고 말합니다.
You can specify a lora to control the art direction or character likeness. Add this to the end of the prompt like <move-enhancer-huny>
이미지에서 동영상으로
사진을 업로드하여 동영상으로 만들 수 있습니다. 한 가지 명령만 있는 것이 아니라 '애니메이션' workflow 시리즈를 살펴보고 다양한 종류의 AI 모델을 사용해 보세요. 다양한 모델과 프롬프트 전략을 시도하여 프로젝트에 가장 적합한 모델을 찾거나, PirateDiffusion PLAYROOM 채널에서 다른 사람들이 만든 것을 살펴보세요.
동영상의 화면 비율은 업로드하는 이미지에 따라 결정되므로 그에 맞게 잘라주세요.
이렇게 하려면 먼저 사진을 채팅에 붙여넣고 사진과 대화하듯 '답글'을 클릭한 다음 다음과 같이 명령합니다:
/wf /run:animate-wan21 a woman makes silly faces towards the camera
또는 SkyReels와 같은 다른 워크플로우 중 하나를 사용해 보세요:
/wf /run:animate-skyreels camera video that slightly changes the angle, focused on a lovely girl smiling and looking at the camera, she looks curious and confident while maintaining eyes on the viewer, her hair is parted, she sits in front of a bookshelf and peeping gremlin eyes behind her, she is relaxing vibe
이미지-투-비디오를 위한 오픈 소스 AI 모델을 호스팅합니다. 가장 인기 있는 두 가지 모델은 다음과 같습니다:
애니메이션-스카이릴 = 훈위안 실사 동영상을 사용하여 이미지를 동영상으로 변환합니다.
animate-ltx90 = 라이트트릭스 모델을 사용합니다. 3D 만화 및 시네마틱 비디오에 적합
특수 매개변수:
/슬롯1 = length 비디오의 프레임 수입니다. 안전한 settings 은 89, 97, 105, 113, 121, 137, 137, 153, 185, 201, 225, 241, 257입니다. 그 이상도 가능하지만 불안정
/슬롯2 = 초당 프레임 수. 24를 권장합니다. 터보 워크플로는 18fps로 실행되지만 변경할 수 있습니다. 24 이상이면 시네마틱하고 30fps가 더 사실적으로 보입니다. 낮은 프레임에서는 60fps도 가능하지만 다람쥐 속도처럼 보입니다.
제한 사항:
동영상을 만들려면 Graydient 플러스 회원이어야 합니다.
현재 VIP 및 플레이룸 채널에서 많은 동영상 샘플을 확인할 수 있습니다. 동영상을 완성하는 동안 저희와 함께 시간을 보내며 즉석에서 아이디어를 보내주세요.
이전 / 변경 로그:
Wan 2.1 및 스카이릴 추가. workflow /쇼: 두 매개변수를 모두 검사하려면 다음을 사용하세요.
ur4(울트라 리얼리스틱 4) 및 flux (벤토 TWO 모델)와 같은 새로운 Flux 워크플로가 추가되었습니다.
로라를 지원하는 Hunyuan 및 LightTricks/LTX 동영상 추가
Llama 3.3 및 더 많은 LLM이 추가되었으며, //lm 명령을 입력하여 찾아볼 수 있습니다.
이제 특정 Flux 워크플로에서 최대 6개의 Flux 로라를 사용할 수 있습니다.
HD Anime 훌륭한 workflow 이 추가되었습니다. Crisp!
Flux Redux, Flux Controlnet Depth 및 수많은 새로운 워크플로우를 이제 사용할 수 있습니다.
더 나은 아웃페인팅! zoomout -로 사진에 답글을 달아 보세요.flux
로라메이커 통합 개선. 를 사용하여 웹브라우저에서 비공개 로라를 생성한 후, 몇 분 안에 텔레그램에서 사용하세요.
새로운 LLM* 명령. llm 를 입력하고 그 뒤에 질문을 입력합니다. 현재 700억 개의 파라미터를 가진 라마 3 모델로 구동되며 매우 빠릅니다! 사용자의 프롬프트를 검열하지는 않지만 모델 자체에 자체적인 레일 가드가 있을 수 있습니다. *LLM 은 ChatGPT와 유사한 채팅 모델에서처럼 "대규모 언어 모델"의 줄임말입니다.
여기에 많은 FLUX 체크포인트가 있습니다. 워크플로를 입력하면 이를 탐색하고 해당 명령을 가져올 수 있습니다. 또한 워크플로의 바로 가기는 /wf입니다. 동영상 튜토리얼
더 많은 모델, 10,000개 이상! 저거너트 X보다 빠른 새로운 저거너트 9 라이트닝을 사용해 보세요. 해시태그만 추가하면 사용하실 수 있습니다: #jugg9
/llm who would win a fight between a pacifist tiger with a shotgun or a thousand angry penguins parachuting above with forks and knives?
llm (예: LLM, 대형 언어 모델)을 입력하고 ChatGPT와 유사하게 질문합니다. 이 모델은 700억 개의 파라미터로 구성된 Llama3 모델을 기반으로 합니다.
나만의 LLM 에이전트 만들기
다른 모델로 전환하고 대체 챗봇 캐릭터를 개인화하려면 my.graydient.ai에 로그인하고 챗봇을 클릭하여 믹스트랄 및 마법사와 같은 다른 LLM을 선택하세요.
소개 "POLLY"
Polly 는 PirateDiffusion 에서 말하는 문자 중 하나이며 images 을 만듭니다. 시도해 보세요:
piratediffusion_bot에 있는 경우 다음과 같이 Polly 으로 대화할 수 있습니다:
/polly a silly policeman investigates a donut factory
graydient.ai에 로그인하고 채팅 Bots 아이콘을 클릭하여 웹 브라우저에서도 사용할 수 있습니다.
사용자 지정 소개 BOTS
Polly 는 community 에서 만든 많은 캐릭터 중 하나에 불과합니다. 다른 공개 캐릭터 목록을 보려면 입력하세요:
/bots
새 항목을 만들려면 다음과 같이 입력합니다.
/bots /new
이렇게 하면 웹 브라우저에서 PollyGPT가 실행되어 나만의 캐릭터를 훈련할 수 있으며, 나중에 @piratediffusion_bot 내에서 캐릭터로 액세스할 수 있습니다.
사용자 지정 탐색 BOTS
AI community 에는 흥미로운 크리에이터들이 많이 있습니다. 일부는 오픈소스 대규모 언어 모델(ChatGPT의 대안)과 오픈소스 이미지 모델(DALLE 및 MJ의 대안)을 오픈소싱하고 있습니다. 저희의 오리지널 소프트웨어는 이 두 가지를 텔레그램 내 또는 웹에서 사용하기 쉬운 "봇" 메이커로 연결합니다. 자세한 정보와 자신만의 봇을 만들 수 있는 템플릿은 Polly GPT 문서 - 이제 추억과 함께! 페이지에서 bots 를 참조하세요.
봇 활성화하기
PirateDiffusion 을 사용하려면 Graydient 계정과 (무료) 텔레그램 계정이 필요합니다. 설정하기
Patreon에서 계정을 업그레이드한 경우, 회원님의 이메일과 Patreon 이메일이 일치해야 합니다. 모든 기능을 활성화하고 잠금을 해제할 수 없는 경우 /debug를 입력하여 해당 번호를 보내주세요.
USERNAME
/username Tiny Dancer
봇은 공개 community username (레시피, 추천 images 과 같은 곳에 표시됨)으로 내 텔레그램 이름을 사용하게 됩니다. WEBUI , PASSWORD 처럼 /username 명령으로 언제든지 변경할 수 있습니다.PirateDiffusion 파일 정리, 그림 그리기 등 까다로운 작업을 위한 웹사이트 컴패니언이 함께 제공됩니다. 아카이브에 액세스하려면 다음과 같이 입력합니다:
팁: /render #quick - 매크로를 사용하면 네거티브를 입력하지 않고도 이 품질을 얻을 수 있습니다.
빠른 프롬프트 팁
1. 항상 전체 그림을 설명하세요.
프롬프트는 채팅 메시지가 아니므로 다중 턴 대화가 아닙니다. 각 프롬프트는 시스템에서 완전히 새로운 차례이며, 이전 차례에 입력한 모든 내용은 잊혀집니다. 예를 들어 "코스튬을 입은 개"라는 프롬프트를 입력하면 반드시 그 사진을 받게 됩니다. 이 프롬프트는 사진을 완전히 설명합니다. "빨간색으로 만들어주세요"라고만 프롬프트하면(불완전한 아이디어) "그것"이 이월되지 않았기 때문에 개가 전혀 보이지 않으므로 프롬프트가 잘못 이해될 수 있습니다. 항상 전체 지시를 제시하세요.
2. 어순이 중요합니다.
가장 중요한 단어를 프롬프트의 첫머리에 배치합니다. 인물 사진을 만드는 경우에는 인물의 외모와 옷을 가장 먼저 배치하고, 그다음에 가장 중요하지 않은 세부 사항으로 무엇을 어디에 있는지를 배치합니다.
3. Length 또한 중요합니다.
처음에 나오는 단어가 가장 중요하며, 마지막에 나오는 각 단어는 약 77개의 '토큰' 또는 지침까지 점점 더 적은 비중을 차지합니다. 하지만 저희 시스템의 각 AI concept 는 서로 다른 주제에 대해 학습되었으므로 올바른 concept 을 선택하는 것이 얼마나 잘 이해하느냐에 영향을 미친다는 것을 알아야 합니다. 요점을 파악하고 학습하는 것이 가장 좋습니다. concepts 시스템 아래)를 학습하는 것이 가장 좋습니다.
긍정적 프롬프트
긍정 프롬프트와 부정 프롬프트는 우리가 하고 싶은 것과 보고 싶지 않은 것을 AI에게 알려주는 단어입니다. 인간은 일반적으로 이러한 이분법적인 형태로 의사소통을 하지 않지만, 시끄러운 환경에서는 "이것도, 저것도!"라고 말할 수 있습니다.
긍정적: 긍정: 맑고 푸른 모래, 야자수가 있는 낮의 해변 풍경 부정: 사람, 보트, 비키니, NSFW
Stable2go 에디터의 두 상자에 다음과 같이 입력합니다:
긍정적인 프롬프트에는 이미지의 주제와 이를 뒷받침하는 세부 정보가 포함됩니다. 예술품( style )과 주변 환경, 미학에 대한 기대치를 설명하는 데 도움이 됩니다. 예시:
최고 품질의 사실적인 강아지 사진
해바라기, 보케 배경의 걸작 드로잉
진입로에서 스쿠터의 로우 앵글 사진, 수채화
((맥주))를 든 거북이
중요: 이미지 생성 명령은/render 및 /polly 과 같은 긍정적 프롬프트 앞에 와야 합니다. 아래 구문을 참조하세요:
긍정의 힘을 더 강력하게 만들기
특정 단어를 더 강조하려면 중첩 괄호를 추가합니다. 이렇게 하면 계수가 1.1배 증가합니다.
위의 예에서는 '거북이'가 프롬프트의 시작 부분에 나타나기 때문에 주어를 '거북이'라고 말하지만, 맥주는 프롬프트의 후반부에 나오더라도 마찬가지로 중요합니다. 예상치 못한 상황을 만들 때는 강조하는 것이 도움이 됩니다.
문제 해결이미지가 흐릿하게 보이는데 guidance 이 7로 설정되어 있다면 네거티브가 너무 강하게 설정된 것일 수 있습니다. 네거티브의 강도를 낮춰 보세요.
긍정과 부정은 한때 AI가 원하는 것을 얻도록 유도하는 유일한 방법이었지만 더 이상 필요하지 않습니다. 대신 concepts (아래)를 사용하세요. 더 많은 예제
프로 명령어
이 매개변수를 사용하여 안정적인 확산 전문가처럼 images 을 만드세요:
RENDER
Polly 또는 사용자 지정 bots 의 프롬프트 작성 도움말을 원하지 않는 경우 /render 명령으로 전환하여 완전히 수동으로 작업하세요. 간단한 연습을 해보세요.
/render a close-up photo of a gorilla jogging in the park <sdxl>
괄호를 너무 많이 추가하면 AI가 채울 수 있는 양이 제한될 수 있으므로 이미지에 결함이 있는 경우 괄호와 반전의 개수를 줄여 보세요.
팁: 빠른 프롬프트 수정 방법: 프롬프트가 제출된 후, 텔레그램 데스크톱에서 위쪽 화살표를 눌러 빠르게 불러올 수 있습니다. 또는, 대체 폰트로 표시되는 프롬프트 확인음을 한 번 탭합니다. 단어 순서가 중요합니다. 가장 중요한 단어를 프롬프트의 앞쪽에 배치하면, 최상의 결과를 얻을 수 있습니다: 카메라 각도, 누가, 무엇을, 어디서.
번역
다른 언어로 안내를 받고 싶으신가요? render images 50개 이상의 언어로 제공됩니다:
/render /translate un perro muy guapo <sdxl>
어떤 언어를 지정할 필요 없이 그냥 알아서 알아듣습니다. 번역을 사용할 때는 은어를 사용하지 마세요. AI가 프롬프트를 이해하지 못하면 좀 더 명확한 용어로 다시 표현해 보세요.
번역 제한 사항
일부 지역 속어는 오해를 불러일으킬 수 있으므로 번역 기능을 사용할 때는 가능한 한 문자 그대로 번역하세요. 예를 들어 'cubito de hielo'는 지역과 문맥의 뉘앙스에 따라 스페인어로 작은 얼음 조각 또는 작은 얼음 통을 의미할 수 있습니다.
사실, 영어에서도 인공지능이 너무 문자 그대로 받아들일 수 있기 때문에 이런 일이 발생할 수 있습니다. 예를 들어 한 사용자가 북극곰 사냥을 요청하자 저격용 소총을 제공했습니다. 악의적인 규정 준수!
이런 일이 발생하지 않도록 긍정 및 부정 프롬프트에 여러 단어를 사용하세요.
RECIPE MACROS
레시피는 프롬프트 템플릿입니다. recipe 에는 토큰, 샘플러, 모델, 텍스트 반전 등이 포함될 수 있습니다. 프롬프트에서 같은 내용을 반복해서 입력하는 경우 시간을 크게 절약할 수 있으며 배울 가치가 있습니다.
네거티브 반전 기능을 도입했을 때 많은 사람들이 "왜 기본적으로 이 기능이 켜져 있지 않나요?"라고 물었고, 그 대답은 control - 사람마다 조금씩 다른 것을 좋아합니다 settings 입니다. 이에 대한 해결책은 프롬프트 템플릿을 불러오는 해시태그인 레시피였습니다.
대부분의 레시피는 community 에서 만들었으며, 해당 소유자가 관리하기 때문에 언제든지 변경될 수 있습니다. 프롬프트에는 recipe 이 하나만 표시되도록 되어 있습니다.
recipe 을 사용하는 방법에는 두 가지가 있습니다. "quick" recipe 과 같이 해시태그를 사용하여 이름으로 부를 수 있습니다:
/render a cool dog #quick
인기 있는 레시피로는 #nfix, #eggs, #boost, #verythingbad, #sdxlreal 등이 있습니다.
중요: recipe 를 만들 때 긍정적인 프롬프트 영역의 어딘가에 $prompt를 추가해야 하며, 그렇지 않으면 recipe 에서 텍스트 입력을 받을 수 없습니다. 아무 곳에나 넣을 수 있으며 유연하게 사용할 수 있습니다.
'기타 명령' 필드에는 아래에 다른 품질 향상 매개변수를 쌓을 수 있습니다.
COMPOSE
Compose 를 사용하면 다중 프롬프트, 다중 영역 생성이 가능합니다. 큰 캔버스 크기와 한 번에 하나의 이미지를 지정하는 것이 가장 효과적이며, 사용 가능한 영역은 배경, 하단, 하단 중앙, 하단 왼쪽, 하단 오른쪽, 중앙, 왼쪽, 오른쪽, 상단, 상단 중앙, 상단 왼쪽, 상단 오른쪽입니다. 각 영역의 형식은 x1, y1, x2, y2입니다.
/compose /size:2000x700 /left:The tower of Thai food /center:Jungles of Thailand, tropical rainforest [blurry] /right: Castle made of stone, castle in the jungle, tropical vegetation
팁: 더 나은 블렌딩을 위해 약 5의 guidance 을 사용합니다. 모델을 지정할 수도 있습니다. Guidance 은 전체 이미지에 적용됩니다. 지역 guidance 을 추가하기 위해 작업 중입니다.
/compose /size:1000x2000 /top: Lion roaring, lion on top of building /center: Apartment building, front of building, entrance /bottom: Dirty city streets, New York city streets [[ugly]] [[blurry] /images:1 /guidance:7
괄호를 너무 많이 추가하면 AI가 채울 수 있는 양이 제한될 수 있으므로 이미지에 결함이 있는 경우 괄호와 반전의 개수를 줄여 보세요.
팁: 빠른 프롬프트 수정 방법: 프롬프트가 제출된 후, 텔레그램 데스크톱에서 위쪽 화살표를 눌러 빠르게 불러올 수 있습니다. 또는, 대체 폰트로 표시되는 프롬프트 확인음을 한 번 탭합니다. 단어 순서가 중요합니다. 가장 중요한 단어를 프롬프트의 앞쪽에 배치하면, 최상의 결과를 얻을 수 있습니다: 카메라 각도, 누가, 무엇을, 어디서.
번역
다른 언어로 안내를 받고 싶으신가요? render images 50개 이상의 언어로 제공됩니다:
/render /translate un perro muy guapo <sdxl>
어떤 언어를 지정할 필요 없이 그냥 알아서 알아듣습니다. 번역을 사용할 때는 은어를 사용하지 마세요. AI가 프롬프트를 이해하지 못하면 좀 더 명확한 용어로 다시 표현해 보세요.
번역 제한 사항
일부 지역 속어는 오해를 불러일으킬 수 있으므로 번역 기능을 사용할 때는 가능한 한 문자 그대로 번역하세요. 예를 들어 'cubito de hielo'는 지역과 문맥의 뉘앙스에 따라 스페인어로 작은 얼음 조각 또는 작은 얼음 통을 의미할 수 있습니다.
사실, 영어에서도 인공지능이 너무 문자 그대로 받아들일 수 있기 때문에 이런 일이 발생할 수 있습니다. 예를 들어 한 사용자가 북극곰 사냥을 요청하자 저격용 소총을 제공했습니다. 악의적인 규정 준수!
이런 일이 발생하지 않도록 긍정 및 부정 프롬프트에 여러 단어를 사용하세요.
RECIPE MACROS
레시피는 프롬프트 템플릿입니다. recipe 에는 토큰, 샘플러, 모델, 텍스트 반전 등이 포함될 수 있습니다. 프롬프트에서 같은 내용을 반복해서 입력하는 경우 시간을 크게 절약할 수 있으며 배울 가치가 있습니다.
네거티브 반전 기능을 도입했을 때 많은 사람들이 "왜 기본적으로 이 기능이 켜져 있지 않나요?"라고 물었고, 그 대답은 control - 사람마다 조금씩 다른 것을 좋아합니다 settings 입니다. 이에 대한 해결책은 프롬프트 템플릿을 불러오는 해시태그인 레시피였습니다.
대부분의 레시피는 community 에서 만들었으며, 해당 소유자가 관리하기 때문에 언제든지 변경될 수 있습니다. 프롬프트에는 recipe 이 하나만 표시되도록 되어 있습니다.
recipe 을 사용하는 방법에는 두 가지가 있습니다. "quick" recipe 과 같이 해시태그를 사용하여 이름으로 부를 수 있습니다:
/render a cool dog #quick
인기 있는 레시피로는 #nfix, #eggs, #boost, #verythingbad, #sdxlreal 등이 있습니다.
중요: recipe 를 만들 때 긍정적인 프롬프트 영역의 어딘가에 $prompt를 추가해야 하며, 그렇지 않으면 recipe 에서 텍스트 입력을 받을 수 없습니다. 아무 곳에나 넣을 수 있으며 유연하게 사용할 수 있습니다.
'기타 명령' 필드에는 아래에 다른 품질 향상 매개변수를 쌓을 수 있습니다.
COMPOSE
Compose 를 사용하면 다중 프롬프트, 다중 영역 생성이 가능합니다. 큰 캔버스 크기와 한 번에 하나의 이미지를 지정하는 것이 가장 효과적이며, 사용 가능한 영역은 배경, 하단, 하단 중앙, 하단 왼쪽, 하단 오른쪽, 중앙, 왼쪽, 오른쪽, 상단, 상단 중앙, 상단 왼쪽, 상단 오른쪽입니다. 각 영역의 형식은 x1, y1, x2, y2입니다.
/compose /size:2000x700 /left:The tower of Thai food /center:Jungles of Thailand, tropical rainforest [blurry] /right: Castle made of stone, castle in the jungle, tropical vegetation
팁: 더 나은 블렌딩을 위해 약 5의 guidance 을 사용합니다. 모델을 지정할 수도 있습니다. Guidance 은 전체 이미지에 적용됩니다. 지역 guidance 을 추가하기 위해 작업 중입니다.
/compose /size:1000x2000 /top: Lion roaring, lion on top of building /center: Apartment building, front of building, entrance /bottom: Dirty city streets, New York city streets [[ugly]] [[blurry] /images:1 /guidance:7
Blend 를 사용하면 ControlNet 라이브러리에서 images 저장된 여러 images 을 융합할 수 있습니다. 이것은 IP 어댑터라는 기술을 기반으로 합니다. 대부분의 사람들에게는 매우 혼란스러운 이름이므로 그냥 blend 이라고 부릅니다.
먼저, 사진을 봇에 붙여넣어 사전 설정 이미지 concepts 를 만들고 ControlNet 에 사용할 것과 같은 이름을 지정합니다. 이미 저장된 컨트롤이 있다면 그것도 사용할 수 있습니다.
/control /new:chicken
두 개 이상이 있으면 blend 으로 함께 보낼 수 있습니다.
/render /blend:chicken:1 /blend:zelda:-0.4
팁: IP 어댑터는 네거티브 images 를 지원합니다. 더 나은 사진을 얻으려면 노이즈 이미지를 빼는 것이 좋습니다.
이 이미지의 노이즈를 /blendnoise로 control 제거할 수 있습니다.
기본값은 0.25입니다. 블렌드노이즈:0.0으로 비활성화할 수 있습니다.
블렌드 가이드를 사용하여 IP 어댑터 효과의 강도를 설정할 수도 있습니다(기본값은 0.7).
팁: Blend 인페인팅 및 SDXL 모델에도 사용할 수 있습니다.
자세히 보기
render 명령에는 강력한 매개변수가 많이 있습니다. 가장 많이 사용되는 매개변수는 일명 Adetailer
/render /adetailer a close-up photo of a gorilla jogging in the park <sdxl>
이미지가 생성되는 즉시 이미지에서 잘못된 손, 눈, 얼굴이 있는지 스캔하여 자동으로 수정합니다. '24년 3월부터 SDXL 및 SD15에서 작동합니다.
제한 사항: 이 경우 최대 15도까지 회전된 얼굴을 놓치거나 두 개의 얼굴이 생성될 수 있습니다.
애프터 디테일러는 아래에 설명된 좋은 긍정 및 부정 프롬프트, 반전과 함께 사용할 때 가장 효과적입니다:
FREE U
FreeU ( render 동안 네 가지 간격으로 guidance 범위를 확장하는 실험 디테일러입니다. b1: 1단계의 백본 계수 b2: 2단계의 백본 계수 s1: 1단계의 스킵 계수 s2: 2단계의 스킵 계수입니다.
/render <av5> a drunk horse in Rome /freeu:1.1,1.2,0.9,0.2
Concepts 개요
Concepts 는 프롬프트만으로는 잘 이해할 수 없는 특정 사항을 생성하는 특수 AI 모델입니다. 여러 개의 concepts 을 함께 사용할 수 있습니다: 일반적으로 하나의 기본 모델과 1~3개의 로라 또는 인버전을 사용하는 것이 가장 일반적입니다.
교육 웹 인터페이스를 실행하여 직접 교육할 수도 있습니다:
/makelora
사용자 지정 로라 및 개인정보 보호에 대한 참고 사항입니다:
비공개 로라:piratediffusion _bot과의 비공개 대화에서 항상 /makelora 명령을 사용하여 나만 볼 수 있는 로라를 만드세요. 비공개 하위 도메인 내에서도 사용할 수 있지만 Stable2go의 공유 인스턴스나 MyGraydient의 빠른 생성에는 표시되지 않습니다.
공용 로라: 로라를 훈련시키고 전체와 공유하려면 community 에 로그인하여graydient.ai 로라메이커 아이콘을 클릭하세요. 이 로라들은 텔레그램 봇을 포함한 모든 사람들에게 나타납니다.
모델 제품군 현재 저희 소프트웨어는 두 가지 Stable Diffusion 제품군을 지원합니다: SD15(구형, 512×512로 훈련됨)와 기본적으로 1024×1024인 Stable Diffusion XL입니다. 이 해상도에 가깝게 유지하면 최상의 결과를 얻을 수 있습니다(사지 중복 등을 피할 수 있습니다).
가장 주의해야 할 점은 패밀리는 서로 호환되지 않는다는 것입니다. SDXL 베이스는 SD15 로라와 함께 사용할 수 없으며, 그 반대의 경우도 마찬가지입니다.
구문:
모델 목록
The term AI model can also mean chat models, so we call image models “concepts”. A concept can be a person, pose, effect, or art style. To bring those things into your creation, we call their “trigger word” which appear in angled brackets like this: <sdxl> Our platform has over 8 terabytes of AI concepts preloaded. PirateDiffusion is never stuck in one style, we add new ones daily.
/concepts
concepts 명령의 목적은 모델에 대한 트리거 단어를 텔레그램에서 목록으로 빠르게 조회하는 것입니다. 이 목록의 끝에는 concepts 웹사이트로 이동할 수 있는 링크도 있습니다.
사용 concepts
이미지를 만들려면 concept의 트리거 단어와 render 명령어(아래 설명)를 페어링하고 사진을 설명합니다.
To use one, use it’s trigger name anywhere in the prompt. For example, one of the most popular concepts of the moment is called Realistic Vision 5 SDXL, a realistic “base model” — the basis of the overall image style. The trigger name for Realistic Vision 5 SDXL is <realvis5-xl> so we would then prompt.
/render a dog <realvis4-xl>
팁: 균형 잡힌 이미지를 만들기 위해 기본 모델(예: realvis4-xl) 1개 또는 3개의 로라를 선택하고 네거티브 인버전을 몇 개 추가합니다. 너무 많거나 상충되는 concepts (예: 2개의 포즈)를 추가하면 아티팩트가 발생할 수 있습니다. 레슨을 수강하거나 직접 만들기
모델 검색
텔레그램에서 바로 검색이 가능합니다.
/concept /search:emma
최근 모델
마지막으로 시도했던 것을 빠르게 기억해 보세요:
/concept /recent
즐겨 찾는 모델
fave 명령을 사용하여 개인 목록에서 좋아하는 모델을 추적하고 기억하세요.
/concept /fave:concept-name
내 기본 모델
Stable Diffusion 1.5가 기본 모델이지만, 이 대신 절대적으로 사용하는 모델로 교체하는 것은 어떨까요?
This will impact both your Telegram and Stable2go account. After you do this command, you don’t have to write that <concept-name> every time in your prompts. Of course, you can override it with a different model in a /render.
/concept /default:concept-name
유형 Concepts
기본 모델은 이미지의 style 을 가장 강력하게 결정하는 "전체 모델"이라고도 합니다. 로라 및 텍스트 반전은 미세한 제어를 위한 작은 모델입니다. 일반적으로 사람이나 포즈와 같은 하나의 피사체에 대한 특정성을 가진 작은 파일입니다. 인페인팅 모델은 Inpaint 및 아웃페인팅 도구에서만 사용되며 렌더링이나 다른 용도로 사용해서는 안 됩니다.
특별 concept Tags
concepts 시스템은 동물부터 포즈까지 다양한 주제의 태그별로 구성되어 있습니다.
모델 작동 방식을 알려주는 유형이라는 특수 태그가 있습니다. 긍정 및 부정 프롬프트를 대체하는 디테일러 및 네거티브라는 대체 태그도 있습니다. 네거티브 concept 유형을 사용하는 경우 가중치도 네거티브로 설정해야 한다는 점을 잊지 마세요.
음수 반전
모델 시스템에는 네거티브 임베딩이라고도 하는 네거티브 인버전이라는 특수 모델이 있습니다. 이 모델은 AI가 하지 말아야 할 일을 안내하기 위해 의도적으로 끔찍하게 보이는 images 에 대해 학습되었습니다. 따라서 이러한 모델을 네거티브로 호출하면 품질이 크게 향상됩니다. 이러한 모델의 가중치는 -0.01에서 -2 사이의 두 배 [[음수 괄호]] 안에 있어야 합니다.
/render <sdxl> [[<fastnegative-xl:-2>]]
Takoyaki on a plate
"Hyper" 및 "Turbo"와 같이 빠르게 들리는 이름을 가진 모델은 render images 낮은 매개 변수로 빠르게 할 수 있습니다. Guidance / CFG.
모델 이름 옆에 있는 숫자는 "가중치"입니다.
control 모델의 가중치를 조정하여 이미지에 미치는 영향력을 조절할 수 있습니다. 모델은 의견이 다양하기 때문에 가중치가 필요하므로 이미지를 자신의 학습 방향으로 끌어당깁니다. 여러 모델을 추가하면 모델이 일치하지 않을 경우 픽셀화 및 왜곡이 발생할 수 있습니다. 이 문제를 해결하기 위해 각 모델의 가중치를 낮추거나 높여 원하는 결과를 얻을 수 있습니다.
가중치 규칙
전체 모델은 조정할 수 없습니다. 체크포인트 또는 체크포인트 또는 기본 모델이라고도 하며, 전체 아트를 결정하는 대용량 파일입니다 style. 기본 모델의 아트 영향을 변경하려면 다른 기본 모델로 바꾸기만 하면 됩니다. 이것이 바로 시스템에 많은 체크포인트가 있는 이유입니다.
로라스와 텍스트 반전에는 유연한 가중치가 있습니다.
가중치를 양수 쪽으로 이동하면 이러한 모델이 더 대담해집니다. 쉽게 설명하자면 LoRas는 텍스트 반전의 더 자세한 버전입니다.
모범 사례
항상 하나의 기본 모델을 사용하고 로라 및 반전을 추가합니다.
여러 개의 기본 모델을 로드해도 blend 하나만 로드되지만 로드한 다른 모델은 '토큰화'되므로 이름을 입력하기만 하면 render 속도 저하 없이 동일한 작업이 수행됩니다(메모리 내 모델 수 감소 = 속도 향상).
로라스와 반전의 경우, 두 가지를 한꺼번에 사용할 수도 있고 여러 개를 동시에 사용할 수도 있지만 대부분의 사람들은 밸런스를 맞추기 쉽기 때문에 1~3개를 사용하는 것을 고수합니다.
SDXL 사용자의 경우 시스템에서 "-형"이라는 많은 태그를 찾을 수 있습니다. 이것은 함께 로드했을 때 가장 잘 작동하는 모델의 하위 제품군입니다. 이 가이드를 작성하는 현재 가장 인기 있는 유형은 포니(말 그대로 포니가 아님)로, 특히 섹시한 콘텐츠에 더 잘 어울리는 프롬프트 응집력을 가지고 있습니다. 포니 로라는 포니 기본 모델 등과 가장 잘 어울립니다.
양수 모델 가중치
가중치의 한계는 -2(음수)와 2(최대)입니다. 일반적으로 0.4 - 0.7 사이의 가중치가 가장 효과적입니다. 0.1 이상의 숫자는 ((긍정 프롬프트))와 비슷한 효과를 냅니다. 10자리 이상의 소수점 정밀도를 사용할 수 있지만 대부분의 사람들이 한 자리 숫자를 고수하므로 이를 권장합니다.
음수 모델 가중치 (위의 음의 반전 참조)
이미지에 부정적인 영향을 미쳐 긍정적인 효과를 얻을 수도 있습니다.
예를 들어, 누군가가 인공지능 손 모음을 학습시키고 이를 네거티브로 로드하면 아름다운 손이 만들어집니다. 꽤 기발한 해결책이었습니다. 저희 시스템에서는 이와 같은 다양한 종류의 고급 해킹을 찾을 수 있습니다. 그들은 save 나쁜 품질]]과 같은 것을 반복해서 입력합니다. 네거티브 모델을 사용할 때는 가중치를 음수(일반적으로 -1 또는 -2)로 밀면 [[네거티브 프롬프트]]와 비슷한 효과를 낼 수 있습니다.
문제 해결
여러 모델을 동시에 사용하는 것은 마치 여러 곡을 동시에 연주하는 것과 같아서, 모두 같은 음량(무게)이라면 어떤 곡을 골라내기가 어렵습니다.
images 이 지나치게 뭉개지거나 픽셀화되어 보이는 경우 기본 모델이 있고 guidance 이 7 이하로 설정되어 있는지, 포지티브와 네거티브가 너무 강하지 않은지 확인하세요. 가중치를 조정하여 최적의 균형을 찾아보세요. 아래 가이드에서 Guidance 및 파라미터에 대해 자세히 알아보세요.
매개변수
해상도: 너비 및 높이
AI 모델 사진은 특정 크기로 '학습'되므로 해당 크기에 가까운 images 을 만들면 최상의 결과를 얻을 수 있습니다. 너무 빨리 너무 크게 만들려고 하면 결함(쌍둥이, 여분의 팔다리)이 발생할 수 있습니다.
가이드라인
안정적인 확산 XL 모델: 1024×1024부터 시작하며 일반적으로 1400×1400 이하에서 안전합니다.
스테이블 디퓨전 1.5는 512×512에서 훈련되었으므로 상한은 768×768입니다. 포토톤과 같은 일부 고급 모델은 960×576에서 작동합니다. SD15 크기 팁 더 보기
아래 Facelift 업스케일러 정보를 참조하여 언제든지 4K에 가까운 두 번째 단계로 업스케일링할 수 있습니다.
구문
다음 단축키 명령을 사용하여 이미지의 모양을 쉽게 변경할 수 있습니다: /portrait /tall /landscape /wide
/render /portrait a gorilla jogging in the park <sdxl>
/size 을 사용하여 해상도를 수동으로 설정할 수도 있습니다. 기본적으로 images 초안은 512×512로 생성됩니다. 약간 흐릿하게 보일 수 있으므로 크기 명령을 사용하면 더 선명하게 보이는 결과를 얻을 수 있습니다.
/render /size:768x768 a gorilla jogging in the park <sdxl>
제한 사항: 안정적인 확산 1.5는 512×512로 훈련되므로 너무 높으면 이중 헤드 및 기타 돌연변이가 발생할 수 있습니다. SDXL은 1024×1024로 훈련되므로 1200×800과 같은 크기가 반복될 가능성이 적기 때문에 SD 1.5 모델보다 SDXL 모델에서 더 잘 작동합니다. /size 을 사용하여 피사체가 중복되는 경우 프롬프트를 여성 1명/남성으로 시작하고 프롬프트 끝에 배경을 더 자세히 설명하세요. 2000×2000 및 4000×4000을 얻으려면 업스케일링을 사용하세요.
Seed
이미지 생성 프로세스를 초기화하는 데 사용되는 임의의 숫자입니다. 이것은 특정 이미지가 아니라(데이터베이스의 사진 ID와 같지 않음) 일반적인 마커에 가깝습니다. seed 의 목적은 이미지 프롬프트를 반복하는 데 도움이 됩니다. Seed 은 원래 영구 문자를 유지하는 가장 좋은 방법이었지만 Concepts 시스템으로 대체되었습니다.
이미지를 반복하려면 Seed, Guidance, Sampler, Concepts 및 프롬프트가 동일해야 합니다. 이를 벗어나면 이미지가 변경됩니다.
SYNTAX
/render /seed:123456 cats in space
Steps
AI가 이미지를 refine 처리하는 데 걸리는 반복 횟수이며, 일반적으로 steps 이 많을수록 품질이 높아집니다. 물론 단계 수가 많을수록 처리 속도가 느려집니다.
/render /steps:25 (((cool))) cats in space, heavens
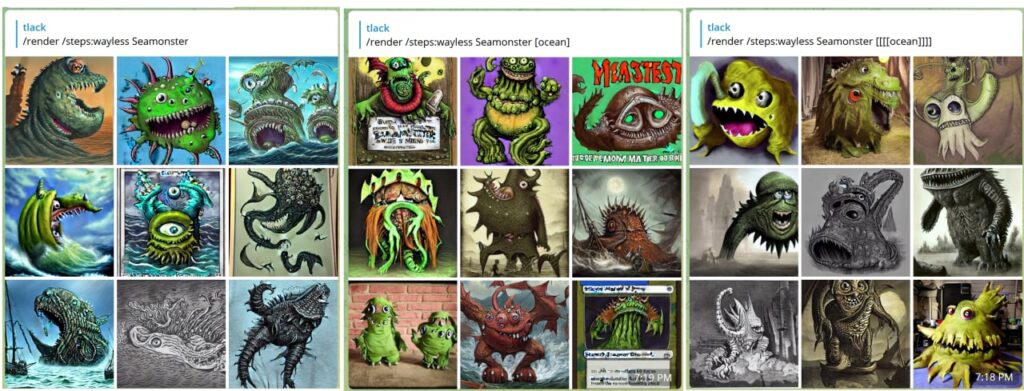
steps 을 25로 설정하면 평균값이 됩니다. steps 을 지정하지 않으면 기본적으로 높은 값인 50으로 설정됩니다. 수동으로 설정할 경우 steps 1~100 범위, 사전 설정과 함께 사용할 경우 최대 200 steps 까지 설정할 수 있습니다. 사전 설정은 다음과 같습니다:
waymore - 200 steps, 두 images - 품질 최고
더 -100 steps, 3 images
미만 - 25 steps, 여섯 images
웨이리스 - 15 steps, 9 images! - 초안에 가장 적합
/render /steps:waymore (((cool))) cats in space, heavens
모든 render 에 /steps:waymore를 설정하고 싶을 수도 있지만, 계산 시간이 오래 걸리므로 workflow 속도가 느려질 뿐입니다. 최상의 프롬프트를 만들었으면 steps 을 크랭크업하세요. 또는 LCM sampler 을 사용하여 가장 적은 수의 steps 으로 최고 품질의 images 를 얻는 방법을 알아보세요. steps 이 너무 많으면 이미지가 손상될 수도 있습니다.
예외
예전에는 35 steps 이상으로 작업해야 화질이 좋다는 조언이 있었지만, 최신 고효율 모델은 단 4개의 steps!로도 멋진 이미지를 만들 수 있기 때문에 더 이상 항상 그렇지는 않습니다.
Guidance (CFG)
분류기 없음 Guidance 척도는 AI가 프롬프트를 얼마나 잘 따르는지를 제어하는 매개변수로, 값이 클수록 프롬프트를 더 잘 준수한다는 의미입니다.
이 값을 높게 설정하면 이미지가 더 선명하게 보일 수 있지만 AI가 공간을 채울 수 있는 '창의성'이 줄어들기 때문에 픽셀화 및 글리치가 발생할 수 있습니다.
가장 일반적인 기본 모델의 경우 안전한 기본값은 7입니다. 그러나 다른 guidance 척도를 사용하는 특수 고효율 모델이 있으며, 아래에 설명되어 있습니다.
SYNTAX
/render <sdxl> [[<fastnegative-xl:-2>]]
/guidance:7
/size:1024x1024
Takoyaki on a plate
guidance 을 얼마나 높게 또는 낮게 설정해야 하는지는 사용 중인 sampler 에 따라 다릅니다. 샘플러는 아래에 설명되어 있습니다. 이미지 '풀기'에 허용되는 steps 의 양 또한 중요한 역할을 할 수 있습니다.
규칙의 예외
일반적인 모델은 이 guidance 및 단계 패턴을 따르지만, 최신 고효율 모델은 동일한 방식으로 작동하는 데 훨씬 적은 guidance (1.5 - 2.5)가 필요합니다. 이에 대한 설명은 아래에 나와 있습니다:
고효율 모델
낮음 Steps, 낮음 Guidance
concepts 대부분 guidance 7, steps 35 이상이면 멋진 이미지를 생성할 수 있습니다. 하지만 고효율 모델이 등장하면서 상황이 달라지고 있습니다.
이 모델은 4-12 steps 을 4/12 guidance 로 낮추면 1/4의 시간으로 images 을 만들 수 있습니다. 태그는 다음과 같이 찾을 수 있습니다. 터보, 하이퍼, LCM, 라이트닝 concepts 로 태그를 지정할 수 있으며 기존 모델과 호환됩니다. 같은 모델군의 로라스 및 인버스와 함께 사용할 수 있습니다. SDXL 제품군은 선택의 폭이 가장 넓습니다(맨 오른쪽 풀다운 메뉴 사용). 저거너트 9 라이트닝이 가장 인기 있는 제품입니다.
Some of our other favorite Lightning models are <boltning-xl> and <realvis4light-xl> which look great with a guidance of 2, steps between 4-12, and Refiner (no fix) turned off. Polish it off with a good negative like [[<fastnegative-xl:-2>]]. Follow it up with an upscale, and the effects are stunning!
아래 그림과 같이 2.5( guidance )와 8( steps )의 Aetherverse-XL(아래 그림)과 같은 특수 모델 유형에 대한 자세한 사용 방법은 해당 모델에 대한 메모를 참조하세요.
VASS(SDXL만 해당)
Vass는 SDXL용 HDR mode 로, 구도를 개선하고 채도를 낮출 수도 있습니다. 어떤 사람들은 선호하지만 어떤 사람들은 선호하지 않을 수도 있습니다. 이미지가 너무 화려해 보인다면 리파이너 없이 사용해 보세요(NoFix).
이 이름은 SDXL 잠재 공간을 탐구해 온 독립 연구자 티모시 알렉시스 바스(Timothy Alexis Vass)의 이름에서 유래했습니다. 흥미로운 관찰을 한. 그의 목표는 색 보정과 images 의 콘텐츠를 개선하는 것입니다. 우리는 그가 게시한 코드를 PirateDiffusion 에서 실행되도록 조정했습니다.
/render a cool cat <sdxl> /vass
사용 이유와 시기 너무 노랗거나 중앙에서 벗어나거나 색상 범위가 제한적으로 느껴지는 SDXL images 에서 사용해 보세요. 더 선명하고 깔끔한 배경을 볼 수 있을 것입니다.
제한 사항: SDXL에서만 작동합니다.
파서 및 가중치
프롬프트를 수집하는 소프트웨어의 일부를 파서라고 합니다. 파서는 AI가 사용자가 표현하려는 내용과 가장 우선순위를 두어야 할 내용을 얼마나 잘 이해하는지, 즉 프롬프트의 응집력에 가장 큰 영향을 미칩니다.
PirateDiffusion 에는 기본, LPW, 가중치(파서 "새")의 세 가지 파서 모드가 있습니다. 모두 장단점이 있으므로 style 및 구문에 대해 어떻게 생각하는지에 따라 결정됩니다.
MODE 1 - 기본 구문 분석기(가장 쉬운)
기본 구문 분석기는 가장 많은 호환성과 기능을 제공하지만, 77개의 토큰(논리적 아이디어 또는 단어 부분)만 통과할 수 있으며, Stable Diffusion은 긴 프롬프트에 대한 주의를 기울이지 않습니다. 중요한 내용을 전달하기 위해 위 섹션에서 설명한 대로 (긍정) 및 [부정] 강화를 추가할 수 있습니다(긍정 참조). 이는 SD 1.5 및 SDXL에서 작동합니다.
긴 프롬프트 가중치(실험 중)
이 기능을 켜면 긍정 및 부정 프롬프트를 더 길게 작성할 수 있습니다. 데모 동영상을 시청하세요.
예시:
((high quality, masterpiece, masterwork)) A wizard browsing through a magical marketplace with a mystical air around him. He has pointy ears, spectacles perched precariously on his nose, and a wand twirling in hsi hand. His robes are adorned with intricate patterns and patterns of magic dust. There is a bubbling magical cauldron, and mythical creatures peeking around from behind him.
이것은 프롬프트 이해도를 77 토큰보다 훨씬 더 높일 수 있는 프롬프트 리밸런싱 유틸리티로, 전반적인 프롬프트 이해도를 향상시킵니다. 물론 몇 가지 안타까운 트레이드오프가 없었다면 이 기능을 표준으로 설정했을 것입니다:
/render /lpw my spoon is too big, ((((big spoon)))) [small spoon], super big, massively big, you would not believe the size, and I've seen many spoons and let me tell you, this spoon in my hand, right here, is yuuuuge, the biggest spoon you'll ever see, and if anyone's said they've seen a bigger spoon, they're cheating, Big spoon, gigantic ladle, extra large serving bowl, oversized utensil, huge portion size, bulky kitchenware, impressive cooking tools, rustic table setting, hearty meals, heavyweight handle, strong grip, stylish design, handcrafted wooden piece, <coma2>
단어 무게
파서 "새" 일명 프롬프트 가중치
프롬프트의 응집력을 높이기 위한 또 다른 전략은 각 단어에 '가중치'를 부여하는 것입니다. 가중치 범위는 소수점을 사용하여 0 - 2이며, LoRas와 유사합니다. 구문은 약간 까다롭지만 양수 및 음수 가중치를 모두 지원하여 놀라운 정밀도를 제공합니다.
이론적으로는 주름이 응집력을 높이고 의도를 명확하게 전달합니다. 그러나 실제로는 너무 많은 레이어를 클리핑하면 이미지가 나빠질 수 있습니다. 배심원단이 이 문제에 대해 판단을 내리는 동안, 널리 사용되는 "안전한" 설정은 clipskip 2.
정제기(SDXL만 해당)
리파이너는 그림과 일러스트레이션에 권장되는 노이즈 제거 및 스무딩 기법입니다. 더 깨끗한 색상으로 더 매끄러운 images 을 만듭니다. 그러나 때로는 원하는 것과 정반대의 결과가 나올 수도 있습니다. 사실적인 images 의 경우 리파이너를 끄면 아래와 같이 더 많은 색상과 디테일을 얻을 수 있습니다. 그런 다음 이미지를 업스케일링하여 노이즈를 줄이고 해상도를 높일 수 있습니다.
SYNTAX
/render a cool cat <sdxl> /nofix
사용 이유와 시기 이미지가 너무 바랜 것처럼 보이거나 피부색이 칙칙해 보일 때. highdef 또는 /facelift 같은 응답 명령어(아래) 중 하나를 사용하여 후처리를 추가하면 이미지의 완성도를 높일 수 있습니다.
샘플러
sampler (스케줄러라고도 함)는 주어진 매개변수로 AI가 프롬프트를 어떻게 풀어야 하는지 결정하는 알고리즘입니다. "최고" sampler 는 매우 주관적입니다. 추가 정보 및 비교 images
한 가지 예외는 LCM sampler 으로, 특히 낮은 guidance 및 낮은 steps 에서 렌더링하는 데 사용됩니다.
SAMPLER 명령 및 구문
사용 가능한 샘플러 목록을 보려면 다음과 같이 입력하세요. /샘플러
샘플러는 AI 애호가들에게 인기 있는 조정 기능으로, 샘플러의 기능은 다음과 같습니다 . 노이즈 스케줄러라고도 합니다. steps 과 sampler 의 양에 따라 이미지에 큰 영향을 미칠 수 있습니다. steps 을 낮게 설정하더라도 mode "Karras" 옵션을 사용하면 DPM 2++ 와 같은 sampler 으로 멋진 사진을 얻을 수 있습니다. 비교는 샘플러 페이지를 참조하세요.
이 기능을 사용하려면 프롬프트에 다음을 추가하세요.
/render /sampler:dpm2m /karras a beautiful woman <sdxl>
Karras 는 4개의 샘플러와 함께 작동하는 mode 옵션입니다. 테스트 결과, 더 만족스러운 결과를 얻을 수 있었습니다.
LCM 는 잠재 일관성 모델을 의미합니다. 이를 사용하면 images 을 낮은 steps 및 guidance 과 함께 쌓아서 더 빠르게 되돌릴 수 있습니다. 품질보다 속도가 더 중요하다는 단점이 있지만, 대량으로 매우 빠르게 images 을 생성할 수 있습니다.
/render /sampler:lcm /guidance:1.5 /steps:6 /images:9 /size:1024x1024 <realvis2-xl> /seed:469498 /nofix Oil painting, oil on board, painted picture Retro fantasy art by Brom by Gerald Brom ((high quality, masterpiece,masterwork)) [[low resolution,m worst quality, blurry, mediocre, bad art, deformed, disfigured, elongated, disproportionate, anatomically incorrect, unrealistic proportions, melted, abstract, surrealism, sloppy, crooked, skull, skulls]] Closeup Portrait A wizard stands in an alien landscape desert wearing wizards robes and a magic hat
팁: SDXL을 사용할 때 /nofix 를 추가하여 정제기를 비활성화하면 특히 다음과 같은 경우 품질을 향상시키는 데 도움이 될 수 있습니다. /more
SD 1.5 및 SDXL 모델에서 작동합니다. 2~4시 사이에는 guidance , 8~12시 사이에는 steps 에서 사용해 보세요. 실험을 해보고 Patreon의 멤버십 섹션에 있는 VIP 프롬프트 엔지니어링 토론 그룹에서 결과를 공유해 주세요.
모델에 따라 다르지만 /guidance:1.5 /steps:6 /images:9에서도 10초 이내에 좋은 SDXL 결과를 반환하고 있습니다!
위의 예에서 제작자는 매우 낮은 guidance 및 낮은 steps 을 허용하지만 여전히 매우 높은 품질 images 을 생성하는 특수 LCM sampler 을 사용하고 있습니다. 이 프롬프트를 다음과 같이 비교해 보세요: /sampler:dpm2m /karras /guidance:7 /steps:35 VAE 명령은 색상을 제어하고 /nofix 은 SDXL 리파이너를 끕니다. LCM 와 잘 작동합니다.
VAE 오버라이드
VAE 는 이미지의 색상에 많은 영향을 미치는 소프트웨어의 일부인 Variational AutoEncoder의 약자입니다. SDXL의 경우 현재로서는 환상적인 VAE 하나만 있습니다.
VAE 는 대비, 품질 및 채도를 변경하는 데 사용할 수 있는 특수한 유형의 모델입니다. 이미지가 지나치게 뿌옇게 보이는데 guidance 이 10 이상으로 설정되어 있다면 VAE 이 원인일 수 있습니다. VAE 은 "변형 자동 인코더"의 약자로, zip 파일이 이미지를 압축 및 복원하는 방식과 유사하게 images 을 재분류하는 기술입니다. VAE 은 개별 값 대신 노출된 데이터를 기반으로 이미지를 "재수화"합니다. images 렌더링이 모두 채도가 낮거나 흐릿하게 보이거나 보라색 반점이 있는 경우 VAE 을 변경하는 것이 가장 좋은 해결책입니다. (또한 기본적으로 올바른 값을 설정할 수 있도록 알려주시기 바랍니다.) 16비트 VAE 가 가장 빠르게 실행됩니다.
구문
/render #sdxlreal a hamster singing in the subway /vae:GraydientPlatformAPI__bright-vae-xl
컨트롤넷은 최종 이미지를 안내하기 위한 이미지 대 이미지 스텐실입니다. 믿거나 말거나, 브라우저 없이도 텔레그램 내에서 Controlnet 을 사용할 수 있지만, 저희는 두 가지 모두 지원합니다.
시작 이미지를 스텐실로 제공하고 mode 을 선택한 다음, 소스 이미지의 모양을 긍정 및 부정 프롬프트를 사용하여 변경할 수 있습니다. 가중치 슬라이더로 효과를 control 할 수 있습니다. 768×768 또는 1400×1400 사이의 images 을 입력하는 것이 가장 좋습니다.
현재 지원되는 모드는 윤곽선, 깊이, 가장자리, 손, 포즈, 참조, 세그먼트, 스켈레톤 및 facepush 이며, 각 모드에는 하위 매개 변수가 있습니다. 더 많은 예제
controlnet 저장된 프리셋 보기
/control
ControlNet 사전 설정 만들기
먼저 이미지를 업로드합니다. 그런 다음 이 명령어로 해당 이미지에 '답글'을 달고 "myfavoriteguy2"와 같은 이름을 지정합니다.
/control /new:myfavoriteguy2
컨트롤넷은 해상도에 민감하므로 이름에 이미지 해상도를 포함하여 응답합니다. 예를 들어 윌 스미스의 사진을 업로드하면 봇은 윌 스미스-1000×1000 또는 이미지 크기가 무엇이든 응답합니다. 이 기능은 나중에 타겟팅할 크기를 기억하는 데 유용합니다.
ControlNet 프리셋 불러오기
프리셋의 기능을 잊어버린 경우 show 명령을 사용하여 프리셋을 확인할 수 있습니다: /control 또는 특정 프리셋을 보려면 다음과 같이 입력하세요:
/control /show:myfavoriteguy2
ControlNet 모드 사용
control guidance 의 (새로운) 단축 매개변수는 /cg:0.1-2이며, render 이 주어진 controlnet mode 에 얼마나 달라붙어야 하는지를 제어합니다. 스위트 스팟은 0.1-0.5입니다. 기존의 긴 방식인 /controlguidance:1로 작성할 수도 있습니다.
얼굴 바꾸기
페이스스왑은 답글 명령으로도 사용할 수 있습니다. 이 편리한 페이스스왑 (로프, 인사이트페이스)을 사용하여 업로드된 사진의 얼굴을 바꿀 수도 있습니다. 먼저 이미지에 control 을 생성한 다음 얼굴을 바꿀 두 번째 사진을 추가합니다.
답장 명령(모든 모델에서 완성된 이미지를 마우스 오른쪽 버튼으로 클릭)
/faceswap myfavoriteguy2
facelift 는 /strength 매개변수도 지원하지만 작동 방식이 예상과 다릅니다:
/faceswap /strength:0.5 myfavoriteguy2
/strength 을 1보다 작게 입력하면 *blend* "이전 이미지"와 "이후 이미지"를 말 그대로 blend - 포토샵에서 불투명도가 50%인 경우(강도가 0.5인 경우)와 같이 표시됩니다. 그 이유는 다음과 같습니다. 기본 알고리즘에는 사용자가 예상하는 것과 같은 "강도" 설정이 없기 때문에 이것이 유일한 옵션이었기 때문입니다.
얼굴 밀기
얼굴 바꾸기(위에서 설명한 것과 같지만 render-타임 명령으로 "얼굴 밀기"라고 합니다.
페이스스왑 기술은 LoRa와 유사한 방식으로 사용할 수도 있지만, 이는 시간을 절약할 수 있는 방법일 뿐 얼굴 스왑을 생성하는 것은 아닙니다. 이 기술은 가중치나 유연성이 없으며, 새로운 render 에서 모든 실제 얼굴을 찾아 images 을 하나의 얼굴로 바꿉니다. 동일한 ControlNet 사전 설정 이름을 사용하여 사용하세요.
/render a man eating a sandwich /facepush:myfavoriteguy2
Facepush 제한 사항
Facepush 와 같은 안정적인 확산 1.5 모델에서만 작동하며 체크포인트가 현실적이어야 합니다. SDXL 모델에서는 작동하지 않으며 /more 명령이나 일부 고해상도에서는 작동하지 않을 수 있습니다. 이 기능은 실험 단계입니다. facepush 에 문제가 있는 경우 프롬프트를 렌더링한 다음 이미지에 /faceswap 을 실행해 보세요. 이미지가 충분히 사실적이지 않은지 알려줍니다. facelift 을 적용하여 대상을 선명하게 하면 이 문제를 해결할 수 있습니다. /more 및 /remix 이 예상대로 작동하지 않을 수 있습니다(아직).
고급 도구(다양한)
픽셀 및 디테일 부스트
스마트폰 카메라의 '뷰티'( mode )와 유사하게 이미지의 디테일을 4배까지 높이고 사진의 선과 잡티를 제거할 수 있습니다. 사실적인 사진 및 아트웍을 위한 모드입니다. 자세한 정보
높은 방어력
HighDef 명령(고해상도 수정이라고도 함)은 빠르게 픽셀을 두 배로 늘릴 수 있는 기능입니다. 사진에 답글을 달아 화질을 높이면 됩니다.
/highdef
/more 명령은 HighDef 명령이 수행하는 작업 등을 수행할 수 있으므로 highdef 명령에는 매개 변수가 없습니다. 이것은 단순히 편의를 위해 여기에 있습니다. 더 자세한 control, 뒤로 스크롤하여 /more 튜토리얼 동영상을 확인하세요.
highdef 또는 /more 명령을 사용한 후 아래에 설명된 대로 한 번 더 업스케일링할 수 있습니다.
업스케일러
Facelift 는 사실적인 인물 사진을 위한 것입니다.
0.1에서 1 사이의 /strength 을 사용하여 control 효과를 설정할 수 있습니다. 지정하지 않으면 기본값은 1입니다.
/facelift
facelift 명령을 사용하면 업스케일러 라이브러리에 액세스할 수도 있습니다. control 에 이러한 매개변수를 추가하여 효과를 적용하세요:
Facelift 는 2단계 업스케일러입니다. Facelift 을 사용하기 전에 HighDef 을 먼저 사용해야 합니다. 이것은 일반적인 업스케일링 명령으로, 얼굴 디테일을 향상시키고 픽셀을 4배로 늘리는 두 가지 작업을 수행합니다. 스마트폰의 뷰티( mode )와 비슷하게 작동하므로 얼굴, 특히 일러스트레이션을 샌드블래스팅할 수 있습니다. 다행히도 다른 작동 모드도 있습니다:
/facelift /photo
얼굴 보정 기능을 끄고 풍경이나 자연스러운 인물 사진에 적합합니다.
/facelift /anime
이름과 달리 anime 전용이 아닌 모든 일러스트레이션을 향상시키는 데 사용할 수 있습니다.
/facelift /size:2000x2000
제한: Facelift 은 최대 4000×4000까지 이미지 4배 확대를 시도합니다. 텔레그램은 일반적으로 이 크기를 허용하지 않으며, 이미지가 이미 HD인 경우, 4배를 시도하면 메모리가 부족할 수 있습니다. 이미지가 너무 커서 다시 전송이 되지 않는 경우, 텔레그램에는 파일 크기 제한이 있기 때문에, /history 을 입력하여 웹 UI에서 이미지를 불러와 보세요. 또는, 위와 같이 크기 매개변수를 사용하여, 업스케일링시 램을 적게 사용하세요.
REFINE
Refine 은 텔레그램 외부와 웹브라우저에서 텍스트를 수정하고 싶을 때를 위한 기능입니다. 삶의 질을 위한 것입니다.
구독에는 텔레그램과 Stable2go가 모두 포함되어 있습니다 WebUI. refine 명령으로, 텔레그램과 웹 인터페이스 사이를 전환할 수 있습니다. 복사/붙여넣기 대신 웹 브라우저에서 빠르게 텍스트를 변경할 때 유용하게 사용할 수 있습니다.
/refine
WebUI 은 기본적으로 Brew mode 에서 실행됩니다. Render 로 전환하려면 "고급"을 클릭합니다.
Remix 도구
이미지 간 변환
remix 도구는 마법과도 같습니다. 업로드하거나 렌더링한 이미지를 Remix 도구를 사용하여 concept 의 아트 style 에서 변형할 수 있습니다. 입력한 사진을 참고 사진으로 사용하여 주제를 크게 다르게 변경할 수도 있습니다.
SYNTAX
Remix 는 이미지에서 이미지로 style 전송 명령으로, 다시 프롬프트 명령이라고도 합니다.
Remix 는 입력으로 이미지가 필요하며 이미지의 모든 픽셀을 파괴하여 완전히 새로운 이미지를 만듭니다. /more 명령과 비슷하지만 다른 모델 이름과 이미지의 아트 style 를 변경하라는 메시지를 전달할 수 있습니다.
Remix 은 두 번째로 많이 사용되는 '답글' 명령어입니다. 말 그대로 사진에 말하듯 답장을 보낸 다음 명령을 입력합니다. 이 예는 style 에서 시작한 아트를 레벨 4라는 기본 모델로 전환합니다.
/remix a portrait <level4>
remix 으로 업로드한 사진을 사용하면 사진이 완전히 변경됩니다. 픽셀을 보존하려면(예: 얼굴을 변경하지 않으려면) 대신 Inpaint 으로 마스크를 그리는 것이 좋습니다.
용도: Style 전송 및 크리에이티브 "업스케일"
또한 remix 도구를 사용하여 저해상도 images 사진을 현대적이고 사실적인 images 으로 바꾸거나 캐리커처 또는 anime 일러스트레이션으로 바꾸는 등 새로운 방식으로 재해석할 수 있습니다. 이 동영상에서 그 방법을 확인하세요:
추가 도구(답장 명령)
더 보기 도구는 동일한 이미지의 변형을 생성합니다.
동일한 피사체를 약간 다르게 변형하여 보려면 더 보기 도구를 사용합니다.
내부적으로 어떤 일이 일어나고 있는지 알아보세요: seed 값이 증가하고 guidance 은 무작위로 변경되며 원래 프롬프트는 그대로 유지됩니다. 제한 사항:효율적인 모델 사용 시 guidance 을 초과할 수 있습니다.
더 많은 기능을 사용하려면 말 그대로 사람과 대화하듯 마우스 오른쪽 버튼을 클릭하여 이미지에 답글을 달면 됩니다. 답글 명령은 images 을 조작하고 IMG2IMG 또는 원본 프롬프트 조회와 같은 정보를 검사하는 데 사용됩니다.
더 보기
가 가장 일반적인 답글 명령입니다. 프롬프트에 의해 이미 생성된 이미지에 답장할 때 비슷한 images 을 반환합니다. /more 명령은 업로드된 이미지에는 작동하지 않습니다.
/more
명령어가 많을수록 보기보다 강력합니다. 또한 강도, Guidance 및 크기를 허용하므로 2단계 업스케일러로도 사용할 수 있으며, 특히 안정적인 확산 1.5 모델에 유용합니다. 이 비디오 튜토리얼을 확인하여 마스터하세요.
인페인팅 도구
일명 생성 채우기
인페인팅은 마스킹 도구로, 특정 영역에 마스크를 그려서 새로운 메시지를 표시하거나 마술 지우개처럼 개체를 제거할 수 있습니다. inpaint 도구에는 자체 긍정 및 부정 프롬프트 상자가 있으며, 트리거 코드인 concepts.
참고: 이 동영상 이후 소프트웨어가 업데이트되었지만 동일한 원칙이 여전히 적용됩니다.
제너레이티브 채우기, 일명 인페인팅
Inpaint 는 사진의 스팟 영역을 변경할 때 유용합니다. 애프터 디테일러와 달리 inpaint 도구를 사용하면 변경하려는 영역을 선택하고 마스킹할 수 있습니다.
Inpaint 을 클릭하면 말 그대로 사진 위에 그림을 그릴 수 있는 웹 브라우저가 열리고, 메시지가 표시될 수 있는 마스크 영역이 만들어집니다. AI뿐만 아니라 업로드된 비AI 사진(손, 하늘, 헤어스타일, 옷 등 변경)에도 그림을 그릴 수 있습니다 images.
/inpaint 밤에 윙윙거리는 반딧불이
GUI에서는 이 도구의 풀다운에서 특별한 특정 아트 스타일(inpaint 모델)을 사용할 수 있으므로 선택하는 것을 잊지 마세요. . 강도와 guidance ~ control 효과를 사용하며, 여기서 강도는 inpaint 프롬프트만 참조합니다.
/inpaint /size:512x768 /strength:1 /guidance:7 fireflies at (night)
팁: 크기는 원본 사진에서 상속되며 512×768이 권장됩니다. 크기를 지정하는 것이 좋으며, 그렇지 않으면 기본값이 512×512로 설정되어 이미지가 찌그러질 수 있습니다. 이미지에서 멀리 떨어져 있는 사람의 경우 이미지의 충실도가 높지 않으면 얼굴이 바뀔 수 있습니다.
/bg 명령을 사용하여 이미지에서 배경을 자동으로 제거한 다음 배경을 변경하라는 메시지를 표시하는 등 inpaint 을 역으로 사용할 수도 있습니다. 이렇게 하려면 /bg 결과에서 마스크 ID를 복사합니다. 그런 다음 /maskinvert 속성
inpaint 와 동일한 규칙을 사용하여 그림을 펼치지만 GUI가 없으므로 어떤 종류의 아트 style 를 사용할지 트리거 단어를 지정해야 합니다. 슬롯 값으로 어느 방향으로 이동할지 지정할 수 있습니다.
/workflow /run:zoomout-flux fireflies at night
방향 CONTROL
슬롯 값을 시계 반대 방향으로 사용하여 패딩을 추가할 수 있습니다. 따라서 슬롯1 = TOP
/workflow /run:zoomout-flux fireflies at night /slot1:200 /slot2:50 /slot3:100 /slot4:300
이전 버전(SDXL)
inpaint 과 동일한 규칙을 사용하여 그림을 펼치지만 GUI가 없으므로 어떤 종류의 아트 style 를 사용할지 트리거 단어를 지정해야 합니다. 아웃페인팅에는 정확히 동일한 inpaint 모델이 사용됩니다. 모델 페이지를 찾아보거나 다음을 사용하여 이름을 알아보세요.
concept /인페인팅에서 사용 가능한 모델을 확인할 수 있습니다.
/outpaint fireflies at night <sdxl-inpainting>
아웃페인트에는 추가 매개변수가 있습니다. 위쪽, 오른쪽, 아래쪽, 왼쪽을 사용하여 캔버스가 확장될 방향을 control 지정합니다. 측면을 빼면 네 방향 모두 균등하게 펼쳐집니다. 배경 blur 보케(1-100), zoom 계수(1-12) 및 원래 영역의 축소(0-256)를 추가할 수도 있습니다. 힘을 더하여 다스리세요.
/outpaint /side:top /blur:10 /zoom:6 /contract:50 /strength:1 the moon is exploding, fireworks <sdxl-inpainting>
선택적 매개 변수
/side아래/위/왼쪽/오른쪽 - 이 명령을 추가하지 않으면 사진을 펼칠 방향을 지정하거나 네 개를 한 번에 모두 펼칠 수 있습니다.
/blur:1-100 - 원래 영역과 새로 추가된 영역 사이의 가장자리를 흐리게 처리합니다.
/zoom:1-12 - 전체 사진의 배율에 영향을 주며, 기본적으로 4로 설정되어 있습니다.
/contract0-256 - 원본 영역을 칠한 영역에 비해 더 작게 만듭니다. 기본값은 64로 설정되어 있습니다.
팁: 더 나은 결과를 얻으려면 아웃페인트를 사용할 때마다 프롬프트를 변경하고 새로 확장된 영역에 표시할 항목만 포함하세요. 원본 프롬프트를 복사해도 항상 의도한 대로 작동하지 않을 수 있습니다.
BG 도구 제거
초고속 백그라운드 재핑
배경 제거 도구는 피사체 뒤에 있는 모든 것을 한 단계로 쉽게 제거할 수 있는 솔루션입니다. Images 800×800 정도가 가장 적합합니다. 인페인팅 도구 (위)를 사용하여 배경을 마스킹하고 새 배경을 제자리에 배치할 수도 있습니다.
배경 제거 명령
사실적인 배경을 제거하려면 다음과 같이 답장하면 됩니다. /bg
/bg
모든 종류의 일러스트레이션의 경우 이 anime 매개 변수를 추가하면 제거가 더 선명해집니다.
/bg /anime
압축되지 않은 이미지 download 에 PNG 매개변수를 추가할 수도 있습니다. 기본적으로 고해상도 JPG를 반환합니다.
/bg /format:png
16진수 색상 값을 사용하여 배경 색상을 지정할 수도 있습니다.
/bg /anime /format:png /color:FF4433
마스크를 별도로 download
/bg /마스크
팁: 마스크로 무엇을 할 수 있나요? 배경만 표시하려면! 하지만 한 번에 할 수는 없습니다. 먼저 /showprompt 으로 마스크에 답장하여 인페인팅을 위한 이미지 코드를 가져오거나 최근 인페인팅한 마스크에서 선택하세요. render 을 만들 때 전경 대신 배경에 /maskinvert를 추가합니다.
control /new :침실(또는 어떤 방/공간이든 상관없음)으로 배경 사진에 댓글 달기
저장된 배경을 받을 두 번째 이미지인 대상 이미지를 업로드하거나 render .
/bg /replace:침실 /blur:10으로 대상에게 답장하세요.
blur 매개변수는 0~255 사이로, 피사체와 배경 사이의 페더링을 제어합니다. 배경 바꾸기는 피사체 전체가 보이는 경우, 즉 신체나 물체의 일부가 다른 물체에 의해 가려지지 않을 때 가장 잘 작동합니다. 이렇게 하면 이미지가 떠다니거나 배경이 비현실적으로 감싸지는 것을 방지할 수 있습니다.
개체 회전
모든 이미지를 마치 3D 개체처럼 회전할 수 있습니다. 먼저 다음을 사용하여 배경을 제거한 후 훨씬 더 잘 작동합니다. /bg
/spin
스핀은 배경을 제거한 후 가장 잘 작동합니다. 스핀 명령은 /guidance 을 지원합니다. 시스템은 guidance 2 - 10을 무작위로 선택합니다. 자세한 내용은 /steps:100도 추가하세요.
사진 설명
업데이트되었습니다! 이제 두 가지 설명 모드가 있습니다: 클립과 플로렌스2
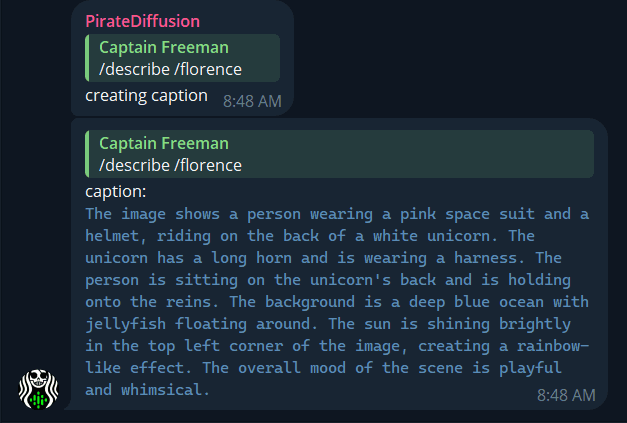
컴퓨터 비전이 있는 이미지에서 설명하기를 사용하여 프롬프트를 생성하세요! "답장" 명령이므로 이미지와 대화하듯 마우스 오른쪽 버튼을 클릭하고 다음과 같이 작성합니다.
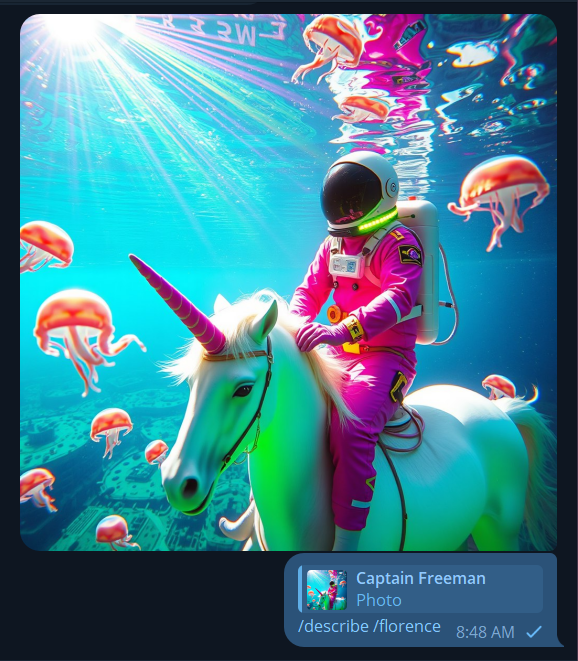
/describe /florence
Florence 매개변수를 추가하면 훨씬 더 자세한 프롬프트가 표시됩니다. 새로운 플로렌스2 컴퓨터 비전 모델을 사용합니다. /describe 자체적으로 CLIP 모델을 사용합니다.
예
내에서 위젯 실행 PirateDiffusion
코딩 방법을 배우지 않고도 사전 설정 버튼을 만들어 손쉽게 푸시 버튼을 만들 수 있습니다. 이는 위젯 시스템을 통해 가능합니다. 스프레드시트에 프롬프트 템플릿을 작성하고 봇에 연결하기만 하면 됩니다. 예를 들어, 캐릭터 제작용 템플릿은 widget 을 제공합니다:
위젯은 텔레그램과 WebUI 을 동시에 생성하여, 두 가지를 모두 즐길 수 있습니다! 위젯에 대한 위젯에 대한 영상 와 download 템플릿 을 참고하여 제작을 시작하세요. 코딩이 필요 없습니다!
파일 및 대기열 관리
취소
렌더링 중인 내용을 중단하려면 /cancel 을 사용하세요.
/cancel
DOWNLOAD
텔레그램에 보이는 images 은 텔레그램에 내장된 이미지 압축기를 사용하고 있습니다. 파일 크기가 제한됩니다. 텔레그램을 우회하려면, /download 으로 이미지에 답장하여 압축되지 않은 RAW 이미지를 받으세요.
/download
download 에서 password 을 요청하는 경우 이 치트 시트의 비공개 갤러리 공유 및 비밀번호 섹션을 참조하세요.
삭제
images 을 삭제하는 방법은 두 가지가 있습니다. 장치에서 로컬로 삭제하거나 클라우드 드라이브에서 영구 삭제하는 것입니다.
images 을 로컬 기기에서 삭제하고 클라우드 드라이브에 보관하려면, 텔레그램에 내장된 삭제 기능을 사용하세요. 이미지를 길게 누르고 (또는 PC에서 마우스 오른쪽 버튼 클릭) 삭제를 선택합니다.
/delete 으로 이미지에 답장하여 클라우드 드라이브에서 이미지를 지웁니다.
/delete
webui 을 입력하고 파일 관리자를 실행한 후 organize 명령을 사용하여 images 을 한꺼번에 일괄 삭제할 수도 있습니다.
역사
해당 텔레그램 채널 내에서 최근에 생성한 images 의 목록을 볼 수 있습니다. 공개 그룹에서 사용할 경우, 해당 공개 채널에서 이미 생성한 images 만 표시되므로, /history 도 개인정보 보호에 민감합니다.
/history
SHOWPROMPT & 비교
이미지의 프롬프트를 보려면 이미지를 마우스 오른쪽 버튼으로 클릭하고 /를 입력합니다.showprompt
/showprompt
이 편리한 명령을 사용하면 이미지가 어떻게 만들어졌는지 확인할 수 있습니다. 이미지에 마지막으로 수행된 작업이 표시됩니다. 전체 기록을 보려면 다음과 같이 작성하세요: /showprompt /history
showprompt 출력에 이미지 비교 도구가 내장되어 있습니다. 해당 링크를 클릭하면 브라우저에서 도구가 열립니다.
설명(클립)
showprompt 명령은 AI 이미지에 대한 정확한 프롬프트를 제공하지만, AI가 아닌 images 은 어떤가요?
/describe 명령은 컴퓨터 비전 기술을 사용하여 업로드한 모든 사진에 대한 안내문을 작성합니다.
/describe
/describe 에서 사용하는 언어가 가끔 궁금할 때가 있습니다. 예를 들어 '아라페드'는 재미있거나 활기찬 사람을 의미합니다.
PNG
기본적으로 PirateDiffusion 은 images 을 무손실에 가까운 JPG로 생성합니다. images 을 JPG 대신 고해상도 PNG로 만들 수도 있습니다. 경고: 이렇게 하면 저장 공간이 5~10배 정도 사용됩니다. 하지만, 문제가 있습니다. 텔레그램은 기본적으로 PNG 파일을 표시하지 않기 때문에, PNG를 생성한 후 /download 명령어(위)를 사용하여 확인을 해야 합니다.
/render a cool cat #everythingbad /format:png
벡터
이미지를 SVG/벡터로! 생성하거나 업로드한 이미지를 trace 으로 보내면 벡터, 특히 SVG로 변환됩니다. 벡터 images 는 일반 images 처럼 래스터화된 픽셀로 렌더링되지 않기 때문에 무한대로 확대할 수 있으므로 가장자리가 선명하고 또렷합니다. 제품 등 인쇄에 적합합니다. 로고나 스티커를 만들 때는 /bg 명령을 사용하세요.
/trace
사용 가능한 모든 옵션이 아래에 나열되어 있습니다. 아직 어떤 옵션이 선택 가능한지 알 수 없으므로 VIP 채팅에서 의견을 공유하여 좋은 기본값을 찾을 수 있도록 도와주세요.
얼룩 - 정수 - 기본값 4 - 범위 1 ... 128 - 크기가 X 픽셀보다 작은 패치 버리기
색상 - 기본값 - 이미지 색상 만들기
bw - 이미지를 흑백으로 만들기
mode - 다각형, 스플라인 또는 없음 - 기본 스플라인 - 커브 피팅 mode
정밀도 - 정수 - 기본값 6 - 범위 1 ... 8 - RGB 채널에서 사용할 유효 비트 수 - 즉, 더 많은 "얼룩"을 희생하여 색 충실도를 높일 수 있습니다.
gradient - 정수 - 기본값 16 - 범위 1 ...128 - gradient 레이어 간의 색상 차이
corner - 정수 - 기본값 60 - 범위 1 ~ 180 - A로 간주할 최소 순간 각도(도) corner
length - 부동 소수점 숫자 - 기본값 4 - 범위 3.5 .. 10 - 모든 세그먼트가 이보다 짧아질 때까지 반복적으로 세분화 부드럽게 수행합니다. length
예: trace (선택 사항으로 미세 조정된 매개변수 포함):
/trace /color /gradient:32 /corner:1
웹 UI 파일 관리자
브라우저에서 파일을 관리하고 시각적인 모델 목록을 빠르게 확인할 때 편리합니다.
/webui
이 페이지 상단의 계정 섹션에서 password 명령어 등을 확인하세요.
RENDER 진행 상황 MONITOR
불가피하게, 텔레그램은 때때로 연결 문제가 발생합니다. 저희 서버가 images 을 만들고 있지만, 텔레그램으로 연결이 되지 않는지 알고 싶으시다면, 다음 명령을 사용하세요. render 으로 이동하여, 클라우드 드라이브에서 images 을 불러올 수 있습니다.
/monitor
monitor 이 작동하지 않으면 /시작을 입력하세요. 이렇게 하면 봇에 넛지를 줄 수 있습니다.
PING
"우리가 다운된 건가, 텔레그램이 다운된 건가, 아니면 대기열에서 나를 잊은 건가?" /ping 에서 이 모든 질문에 대한 답을 한 눈에 볼 수 있습니다.
/ping
ping 이 작동하지 않으면 /시작을 입력하세요. 이렇게 하면 봇에 넛지를 줄 수 있습니다.
SETTINGS
봇의 기본 구성을 재정의할 수 있습니다(예: 특정 sampler, steps, 그리고 매우 유용한 기능인 Stable Diffusion 1.5 대신 선호하는 기본 모델을 설정하는 것).
/settings
사용 가능 settings: /settings /concept:none /settings /guidance:random /settings /style:none /settings /sampler:random /settings /steps:default /settings /silent:off 설정 변경 시 상태 메시지에 변경 사항을 롤백하는 방법이 나와 있으므로 주의 깊게 살펴보시기 바랍니다. 때때로 되돌리려면 매개변수를 off, none 또는 default로 설정해야 합니다 기본값을 변경하기 전에 아래에 설명된 대로 기본값을 로드아웃으로 save 설정하여 구성이 마음에 들지 않아 다시 시작하고 싶을 때 롤백할 수 있도록 할 수 있습니다.
로드아웃
settings 명령은 응답 하단에 로드아웃도 표시합니다.
로드아웃을 저장하여 워크플로를 쉽게 전환할 수 있습니다. 예를 들어, 선호하는 기본 모델과 anime 에 대해 sampler 을, 사실감을 위해 다른 모델을, 특정 프로젝트나 클라이언트에 대해 다른 settings 을 설정할 수 있습니다. 로드아웃을 사용하면 모든 settings 을 순식간에 교체할 수 있습니다.
예를 들어, 내 settings 을 그대로 save 하고 싶다면 'Morgan's Presets Feb 14'와 같은 이름을 만들 수 있습니다:
/settings /save:morgans-presets-feb14
로드아웃 관리: Save 현재 settings: /settings /save:coolset1 현재 표시 settings: /settings /show:coolset1 설정을 검색합니다: /settings /load:coolset1
SILENT MODE
프롬프트 반복 확인과 같은 디버깅 메시지가 너무 장황한가요? 이 기능을 사용하면 봇을 완전히 silent 만들 수 있습니다. 이 기능을 켜지 않으면 봇이 사용자를 무시한다고 생각할 수 있으므로 render 또는 확인 메시지도 표시되지 않습니다!
/settings /silent:on
다시 켜려면 켜짐을 꺼짐으로 변경하면 됩니다.
사용 중단 및 실험 중
이것은 실험 모음이며 이전 명령어는 여전히 지원되지만 최신 기술로 대체되었습니다. 프로덕션용으로 추천하기는 어렵지만 여전히 재미있게 사용할 수 있습니다.
미학 점수
미학은 렌더링 프로세스의 일부로 렌더링된 이미지에서 미학 평가 모델을 사용할 수 있는 실험적인 옵션입니다. 이 옵션은 이제 Graydient API에서도 사용할 수 있습니다.
이러한 머신 러닝 모델은 이미지의 시각적 품질/미용을 수치로 평가합니다.
/render a cool cat <sdxl> /aesthetics
미학("아름다움") 점수는 1~10점, 아티팩트 점수는 1~5점(낮을수록 좋음)을 반환합니다. 무엇이 좋은지 나쁜지 확인하려면 데이터 집합을 참조하세요. 점수는 /에서 볼 수도 있습니다.showprompt
BREW
Brew 로 대체되었습니다 /polly. (무작위 효과를 추가하는 데 사용되었습니다).
/brew 멋진 개 = /polly 멋진 개
이렇게 하면 동일한 결과가 반환됩니다.
MEME
농담으로 추가한 것이지만 여전히 효과가 있고 꽤 재미있습니다. 이미지의 상단과 하단에 한 번에 한 섹션씩 인터넷 거대한 IMPACT 글꼴 밈 텍스트를 추가할 수 있습니다.
/메모 /탑:하나는 단순히
(다음 턴)
/메모 /하단:모르도르에 들어가기
지침 PIX 2 PIX
로 대체됩니다: Inpaint, 아웃페인트 및 Remix
이것은 당시 가장 핫한 기술인 /편집 명령어인 인스트럭트 픽스2픽스라는 기술이었습니다. 이렇게 사진에 댓글을 달 수 있습니다:
/편집 하늘에 불꽃놀이 추가하기
풍경과 자연의 images 에 대해 자연어로 "만약"이라는 style 질문을 하여 변화를 확인합니다. 이 기술은 멋지지만 Instruct Pix2Pix는 저해상도 결과를 생성하므로 추천하기 어렵습니다. 또한 자체 아트 style 에 잠겨 있으므로 concepts, 로라, 임베딩 등과 호환되지 않습니다. 512×512 해상도로 잠겨 있습니다. 음란물이나 anime 을 작업하는 경우 이 도구는 작업에 적합하지 않습니다. 대신 /remix 을 사용하세요. control 강도 매개변수로 효과를 적용할 수도 있습니다.
/편집 /strength:0.5 건물에 불이 나면 어떻게 하나요?
스타일
스타일은 더 강력한 레시피 시스템으로 대체되었습니다. 스타일은 공유용이 아닌 개인용 프롬프트 바로가기를 만드는 데 사용됩니다. 복사 명령을 사용하여 다른 사람과 스타일을 교환할 수는 있지만, 해당 코드를 모르면 작동하지 않습니다. 사용자들이 이 점을 혼란스러워한다는 의견을 수렴하여 레시피를 글로벌화했습니다. 이 기능을 살펴보려면 다음과 같이 입력하세요: