概要 Pirate Diffusion by Graydient AI is the most powerful bot on Telegram. It is a multi-modal bot, meaning that it handles large language models like DeepSeek and Llama 3.3, tens of thousands of image models like HiDream, Chroma, FLUX, Stable Diffusion 3.5, AuraFlow, Pony, and SDXL and also video models like Wan, Hunyuan and LightTricks (LTX).
信じられないほどの価値
他のジェネレーティブAIサービスとは異なり、「トークン」や「クレジット」は必要ありません。PirateDiffusion は無制限に使用できるように設計されており、ロイヤリティフリーで、Graydient'webUI にバンドルされています。
なぜボットを使うのか?
モバイルでは非常に高速かつ軽量で、ソロでも、見知らぬ人や友人とのグループでも使用できます。私たちのcommunity Powerfuly ComfyUIワークフロー用のチャットマクロを作っているので、シンプルなチャットボットからデスクトップレンダリングの結果を完全に得ることができます。正気とは思えません。
他に何ができる?
Imagesビデオ、LLM チャット。何でもできる。
GUIなしで数回のキー操作で4Kimages 作成できます。主要なStable Diffusionはすべてチャットで使用できます。ビジュアルインターフェイスが必要な機能もあり、その場合はウェブページをポップアップ表示します(UnifiedWebUI インテグレーション)。
プライベートボットを使って一人で作成することも、グループに参加して他の人が作っているものを見ることもできます。また、PollyGPTのLLMとStableDiffusionのモデルをつなぐ/animebotのようなテーマ別のbots 、彼らとチャットをしながら制作を進めることもできます!ロードアウト、recipe (マクロ)ウィジェット(ビジュアルGUIビルダー)、カスタムbots を使って、あなただけのworkflow 。たくさんのことができます!
オリジン・ストーリー
Pirate Diffusion という名前は、2022年10月にリークされた Stable Diffusion 1.5 モデルに由来する。 オープンソース Pirate Diffusion が大好きです。 楽しく、面白い人々を惹きつけます。
Plus会員には無制限のビデオ・ジェネレーションが用意されている!
Graydientビデオプランのメンバーであれば、使用できる様々なビデオワークフローがあります。ビデオワークフローには、プロンプトをビデオに変換する方法と、既存の写真をビデオに変換する方法の2種類があります。 (将来的には、ビデオからビデオへの変換を追加する予定です。 これはまだ利用できません)。
Text to music – two modes! AUTOMATIC LYRICS
/makesong Write a song about being in the face by a California Rattlesnake. Incorporate "dirty sanchez" and "Roosevelt Hoover"
MANUAL LYRICS
We plan to offer multiple music workflows. The first is called “music-ace” and it works like this:
/workflow /run:music-ace [verse] gonna make some songs [bridge] gonna make em [chorus] with pirate diffusion yeah! テキストからビデオへ まず、ワークフローのページを見て、テキストからビデオへのショートネームを見つけてください。 よく使われるのは
WAN 2.1 - 現在のオープンソースのトップビデオモデル!WANは、HunYuanよりもプロンプトの粘着性とアニメーションが優れているように見えるが、解剖学的には悪い。Boringvideo - iPhoneから送られてきたような、本物そっくりの普通のビデオを作成します。HunYuan - 3つのタイプ、workflow 一番下を見てください。Hunyuanは最もリアルなビデオを作成します。Q "の数字が高いほど品質は高くなりますが、動画は短くなります。ビデオ - 単にビデオと呼ばれるものは、3Dアニメに最適なLTX Lighttricksを使用しています。
/wf /run:video-hunylora-q8 cinematic low angle video of a ronald mcdonald clown eating a square hamburger, the restaurant ((sign text says "Wendys")), ronald mcdonald's clown costume has red afro hair and a red nose with white face paint, the restaurant is brown, the burger is pointy and square, the background has blur bokeh and people are walking around
PirateDiffusion HunyuanとLightTricks / LTXのビデオとロラをサポートしています! 複数のビデオモデルを追加しており、無制限の画像と無制限のロラトレーニングとともに、サービスの一環として無制限に使用することができます。
LTXでは、プロンプトの構造は非常に重要である。プロンプトが短いと静止画になる。アクションや指示が多すぎるプロンプトは、映像がさまざまなランダムな部屋やキャラクターにパンしてしまう。
ベストプラクティスimages にまとまった動きをさせるには?
このようなプロンプトパターンをお勧めする:
まず、カメラが何をしているのか、誰を追っているのかを説明する。例えば、ローアングルのカメラzoom 、俯瞰カメラ、スローパン、ズームアウト、または遠ざかる、など。 次に、被写体と、その被写体が何に対して、あるいは誰に対して行っているアクションをひとつ説明する。この部分は練習が必要だ! 上の例では、ハンバーガーを食べるロナルドがカメラとシーンのセットアップの後に来ていることに注目してください シーンを描写する。 これは、AIがあなたが見たいものを「セグメント化」するのに役立ちます。この例では、ピエロの衣装と背景を描写します。 参考資料を示す。 例えば、"これは映画かテレビ番組のワンシーンのようだ "と言う。 You can specify a lora to control the art direction or character likeness. Add this to the end of the prompt like <move-enhancer-huny>
画像からビデオへ
写真をアップロードしてビデオにすることができます。コマンドはひとつだけではありません。"animate "workflow シリーズを見て、さまざまな種類のAIモデルを使いましょう。また、PirateDiffusion PLAYROOMチャンネルで、他の人がAIモデルを使って作った作品を見ることもできます。
動画の縦横比はアップロードする画像によって決まりますので、それに合わせてトリミングしてください。
そのためには、まず写真をチャットに貼り付け、写真に話しかけるように「返信」をクリックし、次のようなコマンドを与えます:
/wf /run:animate-wan21 a woman makes silly faces towards the camera または、スカイリールなどの他のワークフローを試してみてください:
/wf /run:animate-skyreels camera video that slightly changes the angle, focused on a lovely girl smiling and looking at the camera, she looks curious and confident while maintaining eyes on the viewer, her hair is parted, she sits in front of a bookshelf and peeping gremlin eyes behind her, she is relaxing vibe 私たちは、画像からビデオへのオープンソースのAIモデルをホストしています。 最もポピュラーなものは以下の2つです:
animate-skyreels = HunYuanのリアルな動画を使って画像を動画に変換する。
animate-ltx90 = LightTricksモデルを使用。3Dアニメやシネマティックビデオに最適。
特別なパラメータ:
/slot1 = ビデオのlength (フレーム数)。 安全なsettings は 89, 97, 105, 113, 121, 137, 153, 185, 201, 225, 241, 257。 それ以上も可能ですが、不安定です。
/スロット2=1秒あたりのフレーム数。 24を推奨。 ターボワークフローは18fpsで動作しますが、変更可能です。24以上は映画的で、30fpsはよりリアルに見えます。 60fpsは低フレームで可能ですが、シマリスのスピードのように見えます。
制限:
動画を作成するにはGraydient Plusの会員である必要があります。 本日、VIPとプレイルーム・チャンネルで多くのビデオ・サンプルをご覧いただけます。 私たちがビデオの仕上げをしている間、ぜひ遊びに来て、あなたの迅速なアイデアを送ってください。
前へ / 変更履歴:
Wan2.1とSkyreelsを追加。ワークworkflow /show: を使用して、両方のパラメータを検査する。 ur4(ウルトラリアリスティック4)やbento-flux (弁当TWOモデル)などの新しいFlux ワークフローを追加。 loraに対応したHunyuanとLightTricks / LTXのビデオを追加
Llama 3.3およびその他多数のLLMを追加、//lmコマンドを入力してブラウズする。
現在、特定のFlux ワークフローで、最大 6 台のFlux ロラを使用できます。
HDAnime イラストリアスworkflow を追加。クリスプ!
Flux Redux、Flux Controlnet Depth、そして非常に多くの新しいワークフローが利用可能になりました。
より良いアウトペインティング! 写真に /zoomout- で返信してみてください。flux
より良いLoRamakerの統合。 makeloraを使って ウェブブラウザでプライベートLoraを作成し、数分でTelegramで使用できます。
新しいLLM* コマンド。 llm の後に任意の 質問を 入力してください。 現在、パラメータ700億のラマ3モデルを搭載しており、高速です! 私たちはあなたのプロンプトを検閲しませんが、モデル自体にはそれなりのレールガードがあるかもしれません。*LLM は "Large Language Model "の略で、ChatGPTに似たチャットモデルです。
FLUX 多くの チェックポイントが ここにある。workflowsと入力すると、それらのチェックポイントを検索し、コマンドを取得できます。ワークフローのショートカットは /wf です。 ビデオチュートリアル モデル数は10,000以上! 新しいJuggernaut 9 Lightningをお試しください。Juggernaut Xよりも高速です。このハッシュタグをつけるだけでもご利用いただけます:#jugg9
Florence コンピュータビジョンモデルの追加 - 任意の写真をアップロードし、/describe /florence と入力すると、ワークフローで使用する詳細で鮮やかなプロンプトの説明が表示されます。 カスタムbots 、メモリを保持できるようになりました。PollyGPTチュートリアルの "memories "を参照してください。
render !monitor と 入力すると、小さなウェブページが表示されます。あなたの街のTelegramサーバーがビジーまたはオフラインの場合、images 、私たちのクラウドドライブからより速くピックアップすることができます!
新しいBots !試してみてください:/xtralargebot /animebot /lightningbot と /kimmybot /angelinabot /nicolebot /senseibot のようなおしゃべりなbots をお試しください。
プラス・プランの会員は、Llama3 700億パラメータを選択できるようになった。bots
新しいレシピ:高速HDの#quickimages 、ポートレートの#quickp、ワイドの#quickwをお試しください。
Polly 更新しました!- ボットとチャットするには/polly を使用します。
Polly また、マイモデルで お気に入りマークを付けたモデルのみを使用するようになりました。
新しい/unified コマンドは、ウェブ編集用にStable2goにimages 。
新しい/bots コマンド -Polly を自分好みにカスタマイズ、LLM + イメージモデル!
次は?
機能を提案する
次のロードマップを見る ロードマップ チェンジログ
プリメイド&カスタムbots
基本:LLM コマンド
/llm who would win a fight between a pacifist tiger with a shotgun or a thousand angry penguins parachuting above with forks and knives?
タイプ /llm (LLM のような、大規模な言語モデル)、ChatGPTに似た質問をする。 700億のパラメータを持つLlama3モデルを使用しています。
独自のLLM エージェントを作成する
別のモデルに切り替えて、別のチャットボットキャラクターをパーソナライズするには、my.graydient.aiに ログインし、チャットボットをクリックして、MixtralやWizardのような他のLLMを選択します。
紹介 "POLLY"
Polly は、PirateDiffusion の中で話し、images を作成するキャラクターの一人である。試してみてください:
piratediffusion_botに入れば、Polly のように話すことができる:
/polly a silly policeman investigates a donut factorymy.graydient.ai にログインし、チャットBots アイコンをクリックすると、ウェブブラウザからも使用できます。
カスタム入門BOTS
Polly は、私たちのcommunity によって作成された数多くのキャラクターのひとつにすぎません。他の公開キャラクターのリストを見るには、次のようにタイプしてください:
/bots
新しいものを作成するには、次のようにタイプする。
/bots /new
piratediffusionこれにより、ウェブブラウザでPollyGPTが起動し、あなた自身のキャラクターをトレーニングすることができます。
カスタムBOTS
AIcommunity には、興味深いクリエイターがたくさんいる。大規模な言語モデル(ChatGPTの代替)や画像モデル(DALLEやMJの代替)をオープンソースで公開しているものもあります。私たちのオリジナルソフトは、この2つをテレグラム内やウェブ上で使いやすい「ボット」メーカーに橋渡しします。Polly GPT docs - now with memories! のページで、より詳しい情報と、あなた自身のbots を作成するためのテンプレートをご覧ください。
ボットの起動
PirateDiffusion を使用するには、Graydient アカウントと Telegram アカウント(無料)が必要です。 設定方法
ボットでお困りですか?フリーmode?お問い合わせ
口座の基本 新規ユーザー
/start 始め方
my.graydient.aiに ログインし、ダッシュボードでSetupアイコンを見つけ、指示に従ってください。
サポートが必要な場合は、サポート・チャンネルに ご連絡ください。
電子メール
/email [email protected] Patreonでアカウントをアップグレード した場合、EメールとPatreonのEメールが一致している必要があります。 すべての機能を有効にしてアンロックできない場合は、/debugと入力してその番号を送信してください。
USERNAME
/username Tiny Dancer ボットはあなたのTelegram名を公開名として使用しますcommunity username (レシピのような場所に表示されます、特集images )。username WEBUI とPASSWORD には、ファイルの整理やインペイントのような難しい操作のためのウェブサイトコンパニオンが付属しています。 アーカイブにアクセスするには、次のようにタイプする: PirateDiffusion
/webui デフォルトではプライベートになっている。password を設定するには、次のようなコマンドを使用する。
/community /password:My-Super-Secure-Password123@#$%@#$ password を無効にするには、次のようにタイプする。
/community /password:none
良いプロンプトとは?
プロンプトとは 、AIにどのような画像を生成するかを指示する完全な記述である:
リアルであるべき?アートワークの一種? 時間帯、視点、照明を描写する 被写体とその行動をよく描写する 最後に場所とその他の詳細を記述する 基本的な例:
25歳の金髪女性、インスタグラムのインフルエンサー。
迅速なプロンプトのヒント
1.常に全体像を描写する
プロンプトはチャットメッセージではない 。各プロンプトは、前のターンに入力されたすべてを忘れて、システムでまったく新しいターンを行う。例えば 、"a dog in a costume"(着ぐるみを着た犬)とプロンプトを出せば、必ずそれが返ってくる。 このプロンプトは完全に写真を描写している。 もし「赤くして」とだけ指示すれば(不完全なアイデア)、「それ」が持ち越されていないため、犬がまったく見えなくなり、プロンプトが誤解される。常に完全な指示を提示しましょう。
2.語順の問題
最も重要な言葉をプロンプトの最初に置きます。肖像画を作成する場合は、人物の外見と着ているものを最初に置き、次にその人物がどこにいるのかを最も重要でない詳細として置きます。
3.Length も重要である。
冒頭の単語が最も重要で、末尾に向かうにつれて各単語の注目度は低くなっていきます。しかし、私たちのシステム内の各AIconcept は異なる主題について訓練されているため、適切なconcept を選択することが、あなたの理解度に影響することを知っておく必要があります。 物事は要点を押さえて、システムを学ぶのが一番だ。 concepts システム を学習するのがベストです。
ポジティブなプロンプト
ポジティブ・プロンプトとネガティブ・プロンプトは、私たちが見たいものと見たくないものをAIに伝える言葉だ。人間は通常、このような二項対立の形ではコミュニケーションをとらないが、非常に騒がしい環境では、"これはダメだけど、あれはダメ!"と言うかもしれない。
ポジティブ 澄んだ青い砂浜、ヤシの木がある昼間のビーチシーン否定的: 人、ボート、ビキニ、NSFW
Stable2goエディターの2つのボックスにこのように入力します:
肯定的なプロンプトには、画像の主題とそれを支える詳細が含まれる。芸術style 、周囲の環境、美学への期待などを説明するのに役立ちます。 例
最高品質のリアルな子犬の写真 ひまわりの傑作デッサン、ボケの背景 車道のスクーターのローアングル写真、水彩画 ビールと亀
重要 :
イメージ作成コマンドは 、/render や /polly のように、 ポジティ ブ・プロンプトの前に来る必要があります:
ポジティブをより強力にする
特定の単語をより強調するには、入れ子になった括弧を加える。これにより、その倍率は1.1倍になる。
上の例では、"turtle "はプロンプトの最初に出てくるので、主語は "turtle "だと言っているが、"beer "はプロンプトの後半に出てくるが、同じように重要である。 ありそうもないシチュエーションを作るときには、特別な強調が役立ちます。
その他の例
ネガティブプロンプト ネガ 画像に写って欲しくないものを描写する。
シーモンスターが欲しいが海は嫌だ、という人にはモンスターがお似合いだ。 ポジティブ で、海は ネガティブ .
ネガはまた、余分な手足や解像度の低さなどを抑制することで、写真の質を高めることもできる。
ネガを強くする
括弧は1.1倍の強調になる。否定の場合は角括弧を使用する。
(でも、こういうのはダメだ。
(かわいい猫)最高品質[[[醜い猫、低解像度、低画質]]。
犬1匹(テリア、子犬)、ただし[猫、子猫、毛玉、ガーフィールド]は不可
you can also call a negative concept [[<fastnegative-xl>]]
トラブルシューティング guidance が 7 に設定されている場合、ネガが強く設定されすぎている可能性があります。 強度を下げてみてください。
かつてはポジティブとネガティブが、AIを思い通りに操る唯一の方法だったが、これはもう必要ない。代わりにconcepts (下記)を使う。
その他の例
プロのコマンド これらのパラメーターを使用して、安定した拡散のプロのようにimages :
RENDER もし、Polly やあなたのカスタムbots からのプロンプト作成ヘルプを望まない場合は、/render コマンドに切り替えて完全マニュアルにしてください。 簡単なレッスンを試して みよう。
/render a close-up photo of a gorilla jogging in the park <sdxl> The trigger word <sdxl> refers to a concept
インライン ポジティブ、ネガティブ
ポジティブは AIに何を強調すべきかを指示する。これは(丸括弧)で表される。それぞれの括弧のペアは、正の強化の1.1倍の倍数を表します。ネガティブは その逆で、[角]括弧を使います。
/render <sdxl>
((high quality, masterpiece, masterwork)) [[low resolution, worst quality, blurry, mediocre, bad art, deformed, disfigured, elongated, disproportionate, anatomically incorrect, unrealistic proportions, mutant, mutated, melted, abstract, surrealism, sloppy, crooked]]
Takoyaki on a plate もし画像に不具合がある場合は、括弧の数や反転の数を減らしてみてください。
ヒント:プロンプトをすばやく編集する方法:
トランスレート 別の言語でプロンプトを表示したいですか? このように、50以上の言語でrender images :
/render /translate un perro muy guapo <sdxl> 言語を指定する必要はなく、ただ知っているだけでいい。翻訳を使うときは、俗語を使わないようにしましょう。AIがあなたのプロンプトを理解できなかった場合は、よりわかりやすい言葉で言い換えてみてください。
翻訳の限界
地域によっては誤解されやすい俗語もありますので、翻訳機能を使用する際は、できるだけ文字通りに、本に従ってください。例えば、"cubito de hielo "は、地域や文脈のニュアンスによって、スペイン語で小さな角氷を意味したり、小さなペール缶のバケツの氷を意味したりします。
公平を期すため、AIが物事を文字通りに捉えすぎることがあるため、これは英語でも起こりうる。例えば、あるユーザーがシロクマの狩りをリクエストしたところ、 スナイパーライフルを与えた 。悪意のあるコンプライアンス!
このような事態を避けるために、肯定的・否定的なプロンプトには複数の単語を使うこと。
RECIPE マクロス レシピはプロンプトのテンプレートである。recipe には、トークン、サンプラー、モデル、テキストの反転などを含めることができる。これは時間の節約になり、プロンプトの中で何度も同じことを繰り返しているようなら、学ぶ価値がある。
私たちがネガティブ反転を導入したとき、多くの人が「なぜデフォルトでオンになっていないのか」と質問しました。その答えはcontrol - 誰もが微妙に異なるsettings を好みます。これに対する私たちの解決策は、プロンプト・テンプレートを呼び出すハッシュタグというレシピでした。
テンプレートをご覧になるには、/recipes と入力するか、当ウェブサイトのプロンプトテンプレートのマスターリストを ご覧ください。
/recipes ほとんどのレシピはcommunity によって作成され、それぞれの所有者によって管理されているため、いつでも変更される可能性があります。プロンプトは1つのrecipe 、または物事が奇妙になる可能性があります。
recipe 。 「quick」recipe のように、ハッシュタグを使ってその名前を呼ぶことができる:
/render a cool dog #quick 人気のレシピは、#nfix、#eggs、#boost、#everythingbad、#sdxlreal。
recipe 重要:recipe を作成する場合、$prompt をポジティブ・プロンプト・エリアのどこかに追加する必要があります。プロンプトはどこに入れてもかまいません。
その他のコマンド "フィールドでは、以下の他の品質向上パラメータをスタックできる。
COMPOSE Compose マルチプロンプト、マルチリージョンの作成が可能です。使用可能なゾーンは、background、bottom、bottomcenter、bottomleft、bottomright、center、left、right、top、topcenter、topleft、toprightです。 各ゾーンのフォーマットは x1, y1, x2, y2 です。
/compose /size:2000x700 /left:The tower of Thai food /center:Jungles of Thailand, tropical rainforest [blurry] /right: Castle made of stone, castle in the jungle, tropical vegetation 別の例
/compose /seed:1 /images:2/size:384×960 /top:ゼルダキングダムGloomyCumulonimbus /bottom:1983トヨタHave a Cookie /guidance:5
ヒント: ブレンドを良くするには、guidance を 5 程度にします。Guidance は画像全体に適用されます。私たちは、地域guidance の追加に取り組んでいます。
/compose /size:1000x2000 /top: Lion roaring, lion on top of building /center: Apartment building, front of building, entrance /bottom: Dirty city streets, New York city streets [[ugly]] [[blurry] /images:1 /guidance:7 BLEND (IPアダプター)
前提条件 ControlNet 。
Blend を使用すると、ControlNet ライブラリからimages 保存されている複数のimages を融合することができます。これはIPアダプタと呼ばれる技術に基づいている。これはほとんどの人にとって恐ろしく紛らわしい名前なので、私たちは単にblend と呼んでいます。
まず、写真をボットに貼り付け、ControlNet のように名前を付けて、プリセットの画像concepts を作成します。 すでにコントロールが保存されている場合は、それも使えます。
/control /new:chicken それを2つ以上用意したら、blend 。
/render /blend:chicken:1 /blend:zelda:-0.4 ヒント:IPアダプタはネガティブimages をサポートしています。より良い画像を得るために、ノイズ画像を差し引くことをお勧めします。
この画像のノイズは/blendnoiseでcontrol 。
デフォルトは0.25。blendnoise:0.0で無効にできます。
IPアダプタの効果の強さは、/blendguidanceで設定することもできます。
ヒント:Blend は、インペイントや SDXL モデルでも使用できます。
アフターディテイラー /render コマンドには多くの強力なパラメータがある。よく使われるのはAfter Detailer、別名 Adetailer
/render /adetailer a close-up photo of a gorilla jogging in the park <sdxl> これは、画像が作成された直後に、悪い手、目、顔をスキャンし、自動的に修正します。24年3月現在、SDXLとSD15で動作します。
制限:
アフターディテイラーが最も効果を発揮するのは、以下に説明するような、肯定的・否定的なプロンプトや逆転の発想とともに使用した場合である:
フリーU FreeU (Free Lunch in Diffusion U-Net)は、render の間、guidance の範囲を4つの異なる間隔で拡大する実験的なディテーラーで ある。
/render <av5> a drunk horse in Rome /freeu:1.1,1.2,0.9,0.2
画像作成コマンド POLLY
Polly は、あなたのイメージ作成アシスタントであり、詳細なプロンプトを書く最速の方法です。でモデルを 'Fave concepts を入力すると、Polly があなたのお気に入りの中からランダムに 1 つを選択します。
テレグラムでPolly 、次のように話しかける:
/polly a silly policeman investigates a donut factory返信にはプロンプトが含まれ、その場でrender 、またはクリップボードにコピーして /render コマンド(以下で説明)で使用することができる。
通常のチャット会話は、/rawから始めることもできます。
/polly /raw explain the cultural significance of japanese randoseru my.graydient.ai にログインし、Polly アイコンをクリックすると、ウェブブラウザからも使用できます。
BOTS
Polly をカスタマイズすることができます。アシスタントをトレーニング できる
/bots Bots を実行すると、あなたが作成したアシスタントのリストが表示されます。例えば、私のアシスタントがアリスなら、/alicebot go make me a sandwichのように使えます。 piratediffusion _botはあなたと同じチャンネルでなければなりません。
新しいものを作成するには、次のようにタイプする。
/bots /new RENDER もし、Polly やあなたのカスタムbots からのプロンプト作成ヘルプを望まない場合は、/render コマンドに切り替えて完全マニュアルにしてください。 簡単なレッスンを試して みよう。
/render a close-up photo of a gorilla jogging in the park <sdxl> The trigger word <sdxl> refers to a concept
インライン ポジティブ、ネガティブ
ポジティブは AIに何を強調すべきかを指示する。これは(丸括弧)で表される。それぞれの括弧のペアは、正の強化の1.1倍の倍数を表します。ネガティブは その逆で、[角]括弧を使います。
/render <sdxl>
((high quality, masterpiece, masterwork)) [[low resolution, worst quality, blurry, mediocre, bad art, deformed, disfigured, elongated, disproportionate, anatomically incorrect, unrealistic proportions, mutant, mutated, melted, abstract, surrealism, sloppy, crooked]]
Takoyaki on a plate もし画像に不具合がある場合は、括弧の数や反転の数を減らしてみてください。
ヒント:プロンプトをすばやく編集する方法:
トランスレート 別の言語でプロンプトを表示したいですか? このように、50以上の言語でrender images :
/render /translate un perro muy guapo <sdxl> 言語を指定する必要はなく、ただ知っているだけでいい。翻訳を使うときは、俗語を使わないようにしましょう。AIがあなたのプロンプトを理解できなかった場合は、よりわかりやすい言葉で言い換えてみてください。
翻訳の限界
地域によっては誤解されやすい俗語もありますので、翻訳機能を使用する際は、できるだけ文字通りに、本に従ってください。例えば、"cubito de hielo "は、地域や文脈のニュアンスによって、スペイン語で小さな角氷を意味したり、小さなペール缶のバケツの氷を意味したりします。
公平を期すため、AIが物事を文字通りに捉えすぎることがあるため、これは英語でも起こりうる。例えば、あるユーザーがシロクマの狩りをリクエストしたところ、 スナイパーライフルを与えた 。悪意のあるコンプライアンス!
このような事態を避けるために、肯定的・否定的なプロンプトには複数の単語を使うこと。
RECIPE マクロス レシピはプロンプトのテンプレートである。recipe には、トークン、サンプラー、モデル、テキストの反転などを含めることができる。これは時間の節約になり、プロンプトの中で何度も同じことを繰り返しているようなら、学ぶ価値がある。
私たちがネガティブ反転を導入したとき、多くの人が「なぜデフォルトでオンになっていないのか」と質問しました。その答えはcontrol - 誰もが微妙に異なるsettings を好みます。これに対する私たちの解決策は、プロンプト・テンプレートを呼び出すハッシュタグというレシピでした。
テンプレートをご覧になるには、/recipes と入力するか、当ウェブサイトのプロンプトテンプレートのマスターリストを ご覧ください。
/recipes ほとんどのレシピはcommunity によって作成され、それぞれの所有者によって管理されているため、いつでも変更される可能性があります。プロンプトは1つのrecipe 、または物事が奇妙になる可能性があります。
recipe 。 「quick」recipe のように、ハッシュタグを使ってその名前を呼ぶことができる:
/render a cool dog #quick 人気のレシピは、#nfix、#eggs、#boost、#everythingbad、#sdxlreal。
recipe 重要:recipe を作成する場合、$prompt をポジティブ・プロンプト・エリアのどこかに追加する必要があります。プロンプトはどこに入れてもかまいません。
その他のコマンド "フィールドでは、以下の他の品質向上パラメータをスタックできる。
COMPOSE Compose マルチプロンプト、マルチリージョンの作成が可能です。使用可能なゾーンは、background、bottom、bottomcenter、bottomleft、bottomright、center、left、right、top、topcenter、topleft、toprightです。 各ゾーンのフォーマットは x1, y1, x2, y2 です。
/compose /size:2000x700 /left:The tower of Thai food /center:Jungles of Thailand, tropical rainforest [blurry] /right: Castle made of stone, castle in the jungle, tropical vegetation 別の例
/compose /seed:1 /images:2/size:384×960 /top:ゼルダキングダムGloomyCumulonimbus /bottom:1983トヨタHave a Cookie /guidance:5
ヒント: ブレンドを良くするには、guidance を 5 程度にします。Guidance は画像全体に適用されます。私たちは、地域guidance の追加に取り組んでいます。
/compose /size:1000x2000 /top: Lion roaring, lion on top of building /center: Apartment building, front of building, entrance /bottom: Dirty city streets, New York city streets [[ugly]] [[blurry] /images:1 /guidance:7 BLEND (IPアダプター)
前提条件 ControlNet 。
Blend を使用すると、ControlNet ライブラリからimages 保存されている複数のimages を融合することができます。これはIPアダプタと呼ばれる技術に基づいている。これはほとんどの人にとって恐ろしく紛らわしい名前なので、私たちは単にblend と呼んでいます。
まず、写真をボットに貼り付け、ControlNet のように名前を付けて、プリセットの画像concepts を作成します。 すでにコントロールが保存されている場合は、それも使えます。
/control /new:chicken それを2つ以上用意したら、blend 。
/render /blend:chicken:1 /blend:zelda:-0.4 ヒント:IPアダプタはネガティブimages をサポートしています。より良い画像を得るために、ノイズ画像を差し引くことをお勧めします。
この画像のノイズは/blendnoiseでcontrol 。
デフォルトは0.25。blendnoise:0.0で無効にできます。
IPアダプタの効果の強さは、/blendguidanceで設定することもできます。
ヒント:Blend は、インペイントや SDXL モデルでも使用できます。
アフターディテイラー /render コマンドには多くの強力なパラメータがある。よく使われるのはAfter Detailer、別名 Adetailer
/render /adetailer a close-up photo of a gorilla jogging in the park <sdxl> これは、画像が作成された直後に、悪い手、目、顔をスキャンし、自動的に修正します。24年3月現在、SDXLとSD15で動作します。
制限:
アフターディテイラーが最も効果を発揮するのは、以下に説明するような、肯定的・否定的なプロンプトや逆転の発想とともに使用した場合である:
フリーU FreeU (Free Lunch in Diffusion U-Net)は、render の間、guidance の範囲を4つの異なる間隔で拡大する実験的なディテーラーで ある。
/render <av5> a drunk horse in Rome /freeu:1.1,1.2,0.9,0.2
Concepts 概要 Concepts は、プロンプトだけではよく理解できない特定の事柄を生成する特殊なAIモデルである。複数のconcepts :通常、1つのベースモデルと1~3つのLoRasまたはInversionsを使用するのが一般的です。
また、トレーニング・ウェブ・インターフェースを起動すれば、自分でトレーニングすることもできる:
/makelora 特注ロラとプライバシーについての注意点:
プライベートロラス piratediffusion_botとのプライベートな会話から、常に/makelora コマンドを使用して、あなただけが見ることのできるロラを作成してください。プライベートサブドメイン内でも使用できますが、Stable2goの共有インスタンスやMyGraydientのクイッククリエイトには表示されません。公開ロラス: communitygraydient にログインし、LoRaMakerアイコンをクリックしてください。このロラは、あなたのテレグラムボットを含むすべての人に表示されます。
モデルファミリー 当社のソフトウェアは、現在2つのStable Diffusionファミリーをサポートしています:SD15(古いモデルで、512×512でトレーニングされています)とStable Diffusion XL(ネイティブで1024×1024です)です。 これらの解像度に近づけることで、最良の結果を得ることができます。
最も注意しなければならないのは、ファミリーは互いに互換性がないという ことだ。 SDXLベースはSD15ローラには使用できませんし、その逆も同様です。
構文:
モデル一覧
The term AI model can also mean chat models, so we call image models “concepts”. A concept can be a person, pose, effect, or art style. To bring those things into your creation, we call their “trigger word” which appear in angled brackets like this: <sdxl>
/concepts /concepts コマンドの目的は、モデルのトリガーとなる単語をテレグラムのリストとして素早く検索することです。そのリストの最後には、 私たちのウェブサイトで concepts を視覚的に閲覧するためのリンクもあります。
使用concepts
画像を作成するには、conceptのトリガー・ワードとrender コマンド(以下で説明)をペアにして、写真を描写する。
To use one, use it’s trigger name anywhere in the prompt. For example, one of the most popular concepts of the moment is called Realistic Vision 5 SDXL, a realistic “base model” — the basis of the overall image style. The trigger name for Realistic Vision 5 SDXL is <realvis5-xl> so we would then prompt.
/render a dog <realvis4-xl> ヒント1つのベースモデル(realvis4-xlのような)、1つか3つのロラ、そしてバランスの取れたイメージを作るためにいくつかのネガティブな反転を選びます。concepts (2ポーズなど)多すぎたり、相反するものを加えたりすると、アーティファクトが発生する可能性があります。レッスンを受けるか 、自分で作ってみましょう。
検索モデル
テレグラムからすぐに検索できる。
/concept /search:emma 最近のモデル
最後に試したものを素早く思い出してください:
/concept /recent お気に入りモデル
fave コマンドを使用して、お気に入りのモデルを追跡し、個人的なリストに保存する。
/concept /fave:concept-name 私のデフォルトモデル
Stable Diffusion 1.5がデフォルトのモデルですが、代わりにあなたの絶対的なゴーイングモデルに置き換えてみてはいかがでしょうか?
This will impact both your Telegram and Stable2go account. After you do this command, you don’t have to write that <concept-name> every time in your prompts. Of course, you can override it with a different model in a /render.
/concept /default:concept-name
種類Concepts
ベースモデルは「フルモデル」とも呼ばれ、画像のstyle を最も強く決定します。LoRasとTextualInversionsは 、微調整用の小さなモデルです。これらは1つの被写体、通常は人物やポーズに特化した小さなファイルです。インペイントモデルは、Inpaint と Outpaint ツールでのみ使用され、レンダリングやその他の目的には使用しないでください。
スペシャルconcept タグ
concepts システムはタグによって構成され、動物からポーズまで幅広いトピックがある。
Typeと呼ばれる特別なタグがあり、モデルがどのように振る舞うかを教えてくれます。また、PositivesとNegative Promptsの代わりに、DetailersとNegativeと呼ばれるものがあります。ネガティブconcept タイプを使用するときは、ウェイトもネガティブに設定することを忘れないでください。
逆転 モデル・システムには、ネガティブ・インバージョンと呼ばれる特別なモデルがあり、ネガティブ・エンベッディングとも呼ばれる。これらのモデルは、AIが何をやってはいけないかを導くために、わざとひどいimages 。したがって、これらのモデルを否定として呼び出すことで、品質を大幅に高めることができる。これらのモデルの重みは、-0.01から-2の間の二重[[負の括弧]]でなければなりません。
/render <sdxl> [[<fastnegative-xl:-2>]]
Takoyaki on a plate
Hyper」や「Turbo」のような速そうな名前のモデルは、render images 。 Guidance / CFG .
モデル名以外の数字は "ウェイト"
ウェイトを調整することで、モデルが画像に与える影響力をcontrol 。ウェイトが必要なのは、モデルは意見を持つため、画像を自分のトレーニング方向に引っ張るからです。複数のモデルが追加された場合、意見が一致しないとピクセル化や歪みの原因になります。これを解決するには、各モデルのウェイトを下げたり上げたりすることで、思い通りの結果が得られます。
ウェイトのルール
フルモデルは調整できない。 また チェックポイントやベースモデルとも呼ばれ、全体的なアートstyle を決定する大きなファイルです。ベースモデルのアートの影響を変更するには、単純に別のベースモデルに切り替える必要があります。そのため、システムにはたくさんのベースモデルがあります。
LoRasとTextual Inversionsには柔軟なウェイトがある。
ポジティブな方にウェイトを置くことで、これらのモデルはより大胆になる。平たく言えば、LoRasはTextual Inversionsのより詳細なバージョンである。
ベスト・プラクティス
常に1つのベースモデルを使い、ロラと反転を加える。
複数のベースモデルをロードしても、blend 、ロードされるのは1つだけです。しかし、ロードした他のモデルは「トークン化」されます。つまり、それらの名前を入力するだけで、render (メモリ内のモデル数が少ない=高速化される)速度を落とすことなく、同じことが起こります。
LoRasとInversionsについては、両方使うこともできるし、同時にいくつも使うこともできる。
SDXLユーザーにとって、システムには"-type "と呼ばれるタグがたくさんあります。 これは、一緒にロードしたときに最もよく機能するモデルのサブファミリーです。このガイドの時点では、最も人気のあるタイプはポニー(文字通りのポニーではない)で、特にセクシーなものには、より良いプロンプトのまとまりがあります。ポニー・ロラスはポニーのベース・モデルと最も相性が良い、といった具合だ。
正のモデル重み
ウェイトの限界は-2(マイナス)と2(最大)。通常、0.4~0.7のウェイトが最も効果的です。0.1以上の数値は、((正のプロンプト))と同様の効果があります。小数点以下の精度は10桁以上ありますが、ほとんどの人は1桁にこだわります。
負のモデル重み (上記の負の反転を参照)
正味のプラス効果を得るために、イメージにマイナスの影響を与えることは可能だ。
例えば、ある人が不格好なAIの手のコレクションを訓練し、それをネガとして読み込むと美しい手ができる。この解決策は非常に独創的でした。私たちのシステムには、このような質の高いハックがたくさんあります。 save 何度も[[品質が悪い]]などと入力する手間が省けます。 ネガティブモデルを使うときは、ウェイトをマイナス、通常は-1か-2にスライドさせます。 これは[[ネガティブプロンプト]]と同じような効果があります。
トラブルシューティング
多くのモデルを使用することは、同時に多くの曲を演奏するようなものである。それらがすべて同じ音量(重さ)であれば、何かを選ぶことは難しい。
images が過度にブロック化されていたり、ピクセル化されているように見える場合は、ベース・モデルを使用し、guidance を 7 以下に設定し、ポジとネガが強すぎないようにしてください。ウェイトを調整して、最適なバランスを見つけましょう。Guidance とパラメータについては、以下のガイドを参照してください。
パラメータ
解像度幅と高さ
AIモデルの写真は特定のサイズで "訓練 "されているため、images 、そのサイズに近いものを作成するのが最良の結果を生む。あまり早く大きくしようとすると、不具合(双子、余分な手足)が生じる可能性がある。
ガイドライン
安定した拡散XLモデル:1,024×1,024からスタートし、通常は1,400×1,400以下が安全。 Stable Diffusion 1.5は512×512でトレーニングされているため、上限は768×768となる。Photonのようないくつかの高度なモデルは、960×576で実行されます。その他のSD15サイズのヒント 4Kに近い2段階目のアップスケーリングはいつでも可能です。下記のFacelift アップスケーラー 情報をご覧ください。 構文
以下の省略形コマンドを使えば、画像の形を簡単に変えることができる:/portrait /tall /landscape/wide
/render /portrait a gorilla jogging in the park <sdxl> 解像度は/size で手動設定することもできます。デフォルトでは、ドラフトimages は512×512で作成されます。これらは少しぼやけた感じに見えることがあるので、sizeコマンドを使うとより鮮明に見えます。
/render /size: 768x768 a gorilla jogging in the park <sdxl> 制限事項Stable Diffusion 1.5は512×512で学習されるため、サイズを大きくしすぎるとダブルヘッドやその他の突然変異が発生する。SDXLは1,024×1,024で学習されるため、SD1.5モデルよりもSDXLモデルの方が繰り返しが少なく、1,200×800のようなサイズの方がうまくいきます。/size 、重複した被写体が得られる場合は、1人の女性/男性からプロンプトを開始し、プロンプトの最後に背景を詳しく記述してみてください。アップスケーリングを使用します 。
Seed
画像生成処理を初期化するための任意の番号。これは特定の画像ではなく(データベースの写真IDのようなものではない)、どちらかというと一般的な目印である。seed の目的は、画像プロンプトを繰り返すのを助けることです。Seed はもともと永続的な文字を維持 するための最良の方法でしたが、Concepts システムに取って代わられました。
画像を繰り返すには、Seed 、Guidance 、Sampler 、Concepts 、プロンプトを同じにする。これらにずれがあると画像が変わってしまう。
SYNTAX
/render /seed: 123456 cats in space
Steps
AIが画像をrefine 、一般的にsteps 、より高い品質につながる反復回数。もちろん、ステップ数が多いほど処理は遅くなる。
/render /steps:25 (((cool))) cats in space, heavens steps を25に設定するのが平均的。steps を指定しない場合、デフォルトで50に設定されるが、これは高い。手動で設定した場合はsteps 1から100まで、プリセットと併用した場合はsteps 200まで。プリセットは以下の通り:
waymore - 200steps, twoimages - 品質は最高。 more -100steps, 3images 以下 - 25steps, 6images wayless - 15steps, 9images ! - ドラフトに最適 /render /steps:waymore (((cool))) cats in space, heavens render のたびに /steps:waymore を設定したくなるかもしれないが、計算時間が長くなるため、workflow の速度が遅くなるだけだ。最良のプロンプトを作成したら、steps 。あるいは、LCM sampler の使い方を学んで、steps の数を最小限に抑えて最高品質のimages を得るようにしましょう。 steps の数が多すぎても画像が劣化してしまいます 。
例外
昔のアドバイスでは、高画質を得るためには35steps 以上で作業するようにと言われていたが、最近の高効率モデルは わずか4steps で見事な画像を作成できるため、必ずしもそうではなくなってきている!
Guidance (CFG)。
Classifier-FreeGuidance スケールは、AIがプロンプトにどれだけ忠実に従うかを制御するパラメータで、値が大きいほどプロンプトにより忠実であることを意味する。
この値を高く設定すると、画像はよりシャープに見えますが、AIがスペースを埋める「創造性」が少なくなるため、ピクセル化やグリッチが発生する可能性があります。
最も一般的なベースモデルの場合、安全なデフォルトは7である。しかし、guidance 、異なるスケールを使用する特別な高効率モデルがある。
SYNTAX
/render <sdxl> [[<fastnegative-xl:-2>]]
/guidance:7
/size:1024x1024
Takoyaki on a plate guidance の高さや低さは、使用するsampler によって異なる。サンプラーについては後述する。画像を「解く」ために許されるsteps の量も、重要な役割を果たすことがある。
例外規定
一般的なモデルは、このguidance とステップパターンに従うが、最近の高効率モデルは、同じように機能するのに必要なguidance の数がはるかに少なく、1.5~2.5である。 これについては以下で説明する:
高効率モデル 低Steps, 低Guidance
ほとんどのconcepts 、素晴らしい画像を生成するにはguidance 7と35以上steps 。これは、より高効率のモデルが登場するにつれて変化している。
これらのモデルは、images を1/4の時間で作成することができ、4-12steps 、より低いguidance 。これらの モデルには ターボ、ハイパー、LCM 、ライトニング concepts とタグ付けされており、クラシックモデルと互換性があります。同じモデルファミリーのLorasやInversionsと一緒に使うことができます。SDXLファミリーが最も選択肢が多い(右端のプルダウンメニューを使用)。ジャガーノート9ライトニングが人気。
Some of our other favorite Lightning models are <boltning-xl> and <realvis4light-xl> which look great with a guidance of 2, steps between 4-12, and Refiner (no fix) turned off. Polish it off with a good negative like [[<fastnegative-xl:-2>]]. Follow it up with an upscale, and the effects are stunning!
エーテルバース-XL(下の写真)のように、guidance 2.5、steps 8 、これらの特別なモデルタイプの使用方法の詳細については、そのノートを調べてください。
VASS(SDXLのみ)
VassはSDXL用のHDRmode で、構図を改善し、彩度を下げることができる。これを好む人もいれば、好まない人もいるでしょう。画像がカラフルに見えすぎる場合は、Refiner (NoFix) なしで試してみてください。
この名前はティモシー・アレクシス・ヴァスに由来しており、SDXLの潜在的な空間を探求している独立研究者である。 興味深い見解を発表しました。 .彼の目的は色補正であり、images の内容を改善することです。私たちは彼の公開したコードをPirateDiffusion で実行できるように適応させました。
/render a cool cat <sdxl> /vass 使う理由とタイミングSDXLimages 、黄色すぎたり、中心から外れていたり、色の範囲が狭いと感じたりする場合にお試しください。鮮やかさが増し、背景がきれいになるはずです。
制限事項これはSDXLでのみ動作します。
パーサー&ウェイト プロンプトを取り込むソフトウェアの一部はパーサーと呼ばれる。 パーサーは、プロンプトのまとまり(あなたが表現しようとしていることと、何を最も優先させるべきかをAIがどれだけ理解できるか)に最も大きな影響を与える。
PirateDiffusion デフォルト、LPW、Weights(パーサー "new")の3つのパーサーモードがある。これらにはそれぞれ長所と短所があるので、プロンプトstyle 、syntaxtをどう感じるかによる。
MODE 1 - デフォルトのパーサー(最も簡単)
デフォルトのパーサーは最も高い互換性と機能を提供しますが、Stable Diffusionが長いプロンプトに注意を払わなくなるまでに、77個のトークン(論理的なアイデアや単語部分)しか渡すことができません。重要なことを伝えるために、上のセクションで説明したように、(ポジティブ)と[ネガティブ]強化を追加することができます(ポジティブを参照)。これはSD 1.5とSDXLで機能します。
ロング・プロンプト・ウェイト(実験的) オンにすると、肯定的および否定的なプロンプトを長く書くことができます。デモビデオを見る
例
((high quality, masterpiece, masterwork)) A wizard browsing through a magical marketplace with a mystical air around him. He has pointy ears, spectacles perched precariously on his nose, and a wand twirling in hsi hand. His robes are adorned with intricate patterns and patterns of magic dust. There is a bubbling magical cauldron, and mythical creatures peeking around from behind him.
これは、プロンプトの理解度を77のトークンよりもはるかに高めることができ、プロンプトの理解度を全体的に向上させる、プロンプトのバランス調整ユーティリティである。 もちろん、いくつかの不運なトレードオフがなければ、これを標準に設定するだろう:
制限事項
最良の結果を得るには、 guidance 、7 以下が 必要。 LPWは、非常に強い肯定的または否定的なプロンプトと組み合わせてはならない。(((((;゚Д゚)))))))))))) [[[これもそうだろう]]]。 ロラスやインバージョンとは相性が悪い。 concepts LPW はRemix ツールと 100% 互換性があるわけではありません。 では動作しない。LCM sampler PROMPTLENGTH
/render /lpw my spoon is too big, ((((big spoon)))) [small spoon], super big, massively big, you would not believe the size, and I've seen many spoons and let me tell you, this spoon in my hand, right here, is yuuuuge, the biggest spoon you'll ever see, and if anyone's said they've seen a bigger spoon, they're cheating, Big spoon, gigantic ladle, extra large serving bowl, oversized utensil, huge portion size, bulky kitchenware, impressive cooking tools, rustic table setting, hearty meals, heavyweight handle, strong grip, stylish design, handcrafted wooden piece, <coma2> ワード・ウェイト パーサー「NEW」、別名プロンプト・ウェイト
プロンプトのまとまりを良くするもう一つの方法は、各単語に「重み」をつけることである。 重みの範囲はLoRasと同様、小数を使った0~2である。構文は少々トリッキーだが、正負両方のウェイトがサポートされているので、驚くほどの精度が得られる。
/render /parser:new (blue cat:0.1) (green bird:0.2) [(blue cat:2), (red dog:0.1)] 特に、[( )]の組み合わせで否定を表す否定文に注意しましょう。上の例では、blue cat と red dog が否定です。この機能は/lpw(上記)と混用することはできません。
クリップ・スキップ
この機能は非常に主観的で、モデルによって効果が大きく異なるため、議論の余地がある。
AIモデルはレイヤーで構成されており、最初のレイヤーでは一般的な情報(ジャンクとも言える)が多すぎるため、退屈な構成や繰り返しの構成になると言われている。
クリップスキップのアイデアは、これらのレイヤーで発生するノイズを無視し、肉に直行することだ。
/render /images:1 /guidance:8 /seed:123 /size:1024x1024 /sampler:dpm2m /karras <sdxl> huge diet coke /clipskip:2 理論的には、レイヤーをクリッピングすることで、まとまりと迅速な意図が生まれる。しかし実際には、あまりに多くのレイヤーをクリッピングすると、画像が悪くなることがある。この点についてはまだ判断がつかないが、よく使われる「安全な」設定はclipskip 2。
リファイナー(SDXLのみ)
リファイナーはノイズを除去し、滑らかにするテクニックで、絵画やイラストにおすすめです。よりきれいな色でより滑らかなimages 。しかし、時にはあなたが望むものとは正反対になることもあります。リアルなimages 、リファイナーをオフにすると、下図のように色とディテールが増します。その後、画像をアップスケールしてノイズを減らし、解像度を上げることができます。
SYNTAX
/render a cool cat <sdxl> /nofix 使う理由とタイミング画像が洗礼されすぎていたり、肌の色がくすんで見えたりする場合。highdef や /facelift のような返信コマンド(下記)を使って後処理を加え、画像をより仕上げる。
サンプラー
sampler (スケジューラーとも呼ばれる)は、AIが与えられたパラメータでどのようにプロンプトを解くべきかを決定するアルゴリズムである。最高の」sampler は非常に主観的なものです。
詳細と比較images
唯一の例外は LCM sampler で、これは特に低guidance と低steps でのレンダリングに使用されます。
SAMPLER コマンドと構文
利用可能なサンプラーのリストを見るには、次のようにタイプするだけです。 /サンプラー
サンプラーは、AIマニアに人気のある調整機能であり、ここではその機能を紹介する。 ノイズスケジューラーとも呼ばれる。steps の量とsampler の選択によって、画像に大きな影響を与えることができる。steps が低くても、DPM 2++のようなsampler とオプションのmode "Karras" を使えば、素晴らしい画像が得られます。 比較はサンプラーのページをご覧ください。
これを使うには、プロンプトに次のように追加する。
/render /sampler:dpm2m /karras a beautiful woman <sdxl> Karras は、4つのサンプラーで動作するオプションのmode 。私たちのテストでは、より満足のいく結果が得られます。
LCM の「Stable Diffusion」は「Latent Consistency Models」の略である。 より低いsteps やguidance と積み重ねることで、images をより速く取り戻すために使用する。トレードオフは、品質よりもスピードだが、大きなバッチでは、驚くようなimages を非常に素早く作り出すことができる。
/render /sampler:lcm /guidance:1.5 /steps:6 /images:9 /size:1024x1024 <realvis2-xl> /seed:469498 /nofix Oil painting, oil on board, painted picture Retro fantasy art by Brom by Gerald Brom ((high quality, masterpiece,masterwork)) [[low resolution,m worst quality, blurry, mediocre, bad art, deformed, disfigured, elongated, disproportionate, anatomically incorrect, unrealistic proportions, melted, abstract, surrealism, sloppy, crooked, skull, skulls]] Closeup Portrait A wizard stands in an alien landscape desert wearing wizards robes and a magic hat ヒント SDXLを使用する場合、リファイナーを無効にするために /nofix を追加してください。/more
SD 1.5およびSDXLモデルで動作します。guidance 、2-4の間、steps 、8-12の間でお試しください。 実験を行い、その結果をPatreonのメンバーシップセクションにあるVIPプロンプトエンジニアリングディスカッショングループで共有してください。
モデルによって異なりますが、/guidance:1.5 /steps:6 /images:9でも、10秒以内にSDXLの良好な結果を返します!
/render
/size:1024x1024
<airtist-xl> [[<fastnegative-xl:-2>]]
/sampler:lcm
/guidance:1.5
/steps:6
/nofix
/vae:madebyollin__sdxl-vae-fp16-fix
((high quality, masterpiece,masterwork)) [[low resolution, worst quality, blurry, mediocre, bad art, deformed, disfigured, elongated, disproportionate, anatomically incorrect, unrealistic proportions, mutant, mutated, melted, abstract, surrealism, sloppy, crooked]]
Takoyaki on a plate 上記の例では、作成者は特別なLCM sampler を使用している。これは、非常に低いguidance と低いsteps を可能にし、なおかつ非常に高品質のimages を作成するものである。このプロンプトを次のようなものと比較してください:/sampler:dpm2m /karras /guidance:7 /steps:35
VAE オーバーライド VAE はVariational AutoEncoderの略で、画像のカラフルさに大きな影響を与えるソフトウェアの一部である。SDXLには、現時点で素晴らしいVAE 。
VAE は、コントラスト、画質、彩度を変更するために使用できる特別なタイプのモデルです。画像が過度に曇って見え、guidance が 10 以上に設定されている場合、VAE が原因かもしれません。VAE は "variational autoencoder" の略で、images を再分類する技術です。zip ファイルが画像を圧縮して復元するのと似ています。VAE は、離散的な値ではなく、それにさらされたデータに基づいて画像を「再水和」します。すべてのレンダリングimages 、彩度が落ちていたり、ぼやけていたり、紫色の斑点があったりする場合は、VAE を変更するのが最善の解決策です。(また、デフォルトで正しいものを設定できるよう、私たちにお知らせください)。16 bitVAE が最も速く動作します。
構文
/render #sdxlreal a hamster singing in the subway /vae:GraydientPlatformAPI__bright-vae-xl
利用可能なプリセットVAE オプション:
/vae:GraydientPlatformAPI__bright-vae-xl
/vae:GraydientPlatformAPI__sd-vae-ft-ema
/vae:GraydientPlatformAPI__vae-klf8anime2
/vae:GraydientPlatformAPI__vae-blessed2
/vae:GraydientPlatformAPI__vae-anything45
/vae:GraydientPlatformAPI__vae-orange
/vae:GraydientPlatformAPI__vae-pastel
サードパーティVAE :
アップロードするか、Huggingfaceのウェブサイトでこのフォルダディレクトリを設定したものを見つけてください:
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix
次に、次のようにスラッシュを置き換えてURLの前の部分を削除する:
/render whatever /vae:madebyollin__sdxl-vae-fp16-fix
vae フォルダーには以下の特徴が必要です:
上記のように、Huggingfaceプロファイルの最上位フォルダに、フォルダごとにVAE 。
このフォルダには config.json が含まれていなければなりません。
ファイルは .bin 形式でなければなりません。
ファイル名は "diffusion_pytorch_model.bin "です。
他にもあります:HuggingfaceやCivitaiにもあるかもしれませんが、上記のフォーマットに変換する必要があります。
SD15については、多くのオプションを用意している。その違いについて、ある人の非科学的な意見を紹介しよう:
kofi2 - とてもカラフルで彩度が高い。
blessed2 - コフィ2より飽和度が低い
anything45 - blessed2より飽和度が低い。
オレンジ - 中彩度、パンチのあるグリーン
パステル - オランダの巨匠のような鮮やかな色彩
ft-mse-840000-ema-pruned - リアリズムに最適。
トラブルシューティング VAE 、一部のベースモデルには互換性がありません。その結果、2つの不具合が発生します:ネオン
グリーンの光が漏れる (または)黒い四角が表示されます。そのような場合は、別のVAE 。
プロジェクト
UnifiedWebUI PirateDiffusion Telegramのプロジェクトフォルダに直接images render ことができます。
テレグラムとAPIメソッド:
/render my cool prompt /project: xyz ウェブ方式:
まず、piratediffusion_botでプロジェクトを開始するための画像をrender 。
マイ・Graydient > マイ・Imagesを選択する。images
整理をクリック
プロジェクトのプルダウンをクリックします。
プロジェクトに名前をつける
最初の移動images
プロジェクト関連のコマンドについては、このガイドの一番下までお進みください。
ControlNet 経由PirateDiffusion
ControlNetsは、最終的な画像を誘導するための画像間のステンシルである。信じられないかもしれませんが、ブラウザを使わなくても、Telegram内でControlnet 。
ステンシルとして開始画像を提供し、mode を選択し、正負のプロンプトでソース画像の外観を変更できます。ウェイトスライダーでcontrol 効果を与えることができます。入力images 768×768または1400×1400の間が最適です。
現時点でサポートされているモードは、輪郭、深度、エッジ、ハンド、ポーズ、リファレンス、セグメント、スケルトン、facepush 、それぞれに子パラメータがあります。その他の例
controlnet 保存したプリセットの表示
/control
ControlNet プリセットを作る
まず、画像をアップロードする。次に、このコマンドでその画像に "返信 "し、"myfavoriteguy2 "のような名前をつける。
/control /new:myfavoriteguy2
コントロールネットは解像度に敏感なので、画像の解像度を名前の一部として応答します。つまり、私がウィル・スミスの写真をアップロードすると、ボットはwill-smith-1000×1000または私の画像サイズが何であれ応答します。これは、後でターゲットにするサイズを覚えておくのに便利です。
ControlNet プリセットを呼び出す
プリセットの機能を忘れてしまった場合は、showコマンドで確認してください:/control または、特定のプリセットを表示する:
/control /show:myfavoriteguy2
ControlNet モードの使用
control guidance の(新しい)省略記法パラメータは /cg:0.1-2 -render がcontrolnet mode の指定された範囲にどの程度張り付くかを制御する。スイートスポットは0.1-0.5だ。 旧来の長い書き方で /controlguidance:1 と書くこともできます。
顔の交換 フェイススワップは返信コマンドとしても利用できます。この便利なフェイススワップ (roop, insightface)を使って、アップロードされた画像の顔を入れ替えることもできる。 まず画像のcontrol を作成し、顔を入れ替えるために2枚目の画像を追加します。
返信コマンドとして(どのモデルからでも、完成した画像を右クリックする)
/faceswap myfavoriteguy2facelift も/strength パラメーターに対応しているが、その動作は期待するものとは異なる:
/faceswap /strength:0.5 myfavoriteguy2
/strength を 1 より小さくすると、"処理前画像 "と "処理後画像 "が *blend* になります - フォトショップで不透明度を 50% にしたときのように (強度が 0.5 の場合)、文字通りblend になります。 この理由は 基礎となるアルゴリズムには、期待されるような "強さ "の設定がないので、これが唯一の選択肢でした。
顔を押す フェイススワップ(上記で説明)だが、render-timeコマンドとしては、"フェイスプッシュ "と呼ばれる。
ある意味(LoRaに似た)FaceSwapテクノロジーを使うこともできますが、それはフェイススワップを作成する時間を節約する方法です。ウェイトや多くの柔軟性はありません。新しいrender 、すべてのリアルな顔を見つけ、images 、1つの顔にスワップします。同じControlNet プリセット名を使用してください。
/render a man eating a sandwich /facepush: myfavoriteguy2
Facepush 制限事項
Facepush のようなStable Diffusion 1.5モデルでのみ動作し、チェックポイントは現実的でなければなりません。SDXLモデルでは動作せず、/more コマンドや一部の高解像度では動作しない場合があります。この機能は実験的なものです。facepush で問題がある場合は、プロンプトをレンダリングしてから、その画像に対して/faceswap を実行してみてください。画像が十分にリアルでないかどうかがわかります。これは /facelift を適用してターゲットをシャープにすることで修正できる場合があります。/more と /remix は期待通りに動作しない場合があります(まだ)。
高級ツール(各種)
画素数とディテールを高める
スマートフォンのカメラに搭載されている「ビューティー」mode のように、画像のディテールを4倍にしたり、写真から線やシミを除去することができます。リアルな写真やアートワークのためのモード。 詳細
ハイデフ
HighDef (ハイレゾ修正としても知られている)コマンドは、迅速なピクセル倍増です。 画像にリプライするだけで、その画像をブーストすることができます。
/highdef
highdef コマンドにはパラメータがありません。/more コマンドは、HighDef と同じことができ、それ以上のこともできるからです。これは単にあなたの便宜のためです。もっとcontrol 、/more のチュートリアルビデオをご覧になりたい方は、上にスクロールして戻ってください。
highdef または/more コマンドを使用した後、以下の説明に従ってもう一度アップスケールすることができます。
アップスケーラー
Facelift は、リアルなポートレート写真向けだ。
control 、0.1~1の間で/strength 。指定がない場合、デフォルトは1です。
/facelift
また、/facelift コマンドを使用すると、アップスケーラーのライブラリにアクセスできます。 これらのパラメータを追加して、control :
Facelift はフェーズ2のアップスケーラです。Facelift を使う前に、まずHighDef を使うべきです。これは一般的なアップスケーリングコマンドで、2つのことを行う:顔のディテールをブーストし、ピクセルを4倍にする。これはスマートフォンのbeautymode と同じような働きをします。つまり、顔、特にイラストにサンドブラストをかけることがあります。 幸いなことに、これは他の動作モードを持っています:
/facelift /photo
これは顔のレタッチをオフにし、風景や自然なポートレートに適しています。
/facelift /anime
その名前とは裏腹に、anime - どんなイラストでもブーストするために使う。
/facelift /size:2000x2000
制限:Facelift は、画像を最大4000×4000の4倍にしようとします。Telegramは通常このサイズを許可しておらず、画像がすでにHDである場合、4倍にしようとするとメモリ不足になる可能性が高いです。 画像が大きすぎて戻ってこない場合、Telegramにはファイルサイズの制限があるため、/history と入力してウェブUIから画像を取得してみてください。あるいは、上に示したようにsizeパラメータを使用すると、アップスケール時に使用するメモリが少なくて済みます。
REFINE
Refine は、Telegramの外やウェブブラウザでテキストを編集したいときのためのものだ。クオリティ・オブ・ライフ的なものだ。
サブスクリプションには、Telegram と Stable2goWebUI の両方が付属しています。 refine コマンドを使うと、Telegram とウェブインターフェースを切り替えることができます。これは、コピー&ペーストの代わりに、ウェブブラウザで素早くテキストを変更するのに便利です。
/refine
WebUI はデフォルトでBrew mode で起動します。Render に切り替えるには「Advanced」をクリックしてください。
Remix 工具
画像から画像への変換
remix ツールは魔法のようだ。アップロードまたはレンダリングされた画像は、Remix ツールを使って、concept のアートstyle の中で変身させることができる。また、入力された写真を参考写真として使用し、劇的に異なる主題の変更に踏み込むこともできる。
SYNTAX
Remix はイメージ間style 転送コマンドで、再促進コマンドとしても知られている。
Remix は入力として画像を必要とし、画像のすべてのピクセルを破壊してまったく新しい画像を作成します。これは/more コマンドに似ていますが、別のモデル名と、画像のアートstyle を変更するプロンプトを渡すことができます。
Remix は2番目によく使われる「返信」コマンドだ。 文字通り、写真に話しかけるように返信し、コマンドを入力する。 この例では、style 、レベル4というベースモデルに切り替わります。
/remix a portrait <level4> アップロードした写真を /remix で使用すると、完全に変更されます。ピクセルを保持する(顔を変えないなど)には、代わりに Inpaint でマスクを描くことを 検討してください。
用途Style 移籍とクリエイティブ "高級"
また、remix ツールを使って、解像度の低いimages を新しいものに再解釈することもできます。たとえば、解像度の低いビデオゲームの写真を現代的でリアルなimages に変えたり、自分自身を風刺画やanime イラストに変えたりできます。このビデオではその方法を紹介します:
その他のツール(返信コマンド)
Moreツールは、同じ画像のバリエーションを作成します。
同じ被写体を少しずつ違うバリエーションで見るには、moreツールを使う。
フードの下で何が起こっているのか:元のプロンプトを保持したまま、seed の値が増加し、guidance がランダムになります。 制限事項: 効率的なモデルを 使用する場合、guidance 。
さらに使いたい場合は、右クリックで画像に返信してください。返信コマンドは、IMG2IMGや元のプロンプトを調べるなど、images の操作や情報の検査に使用します。
その他の構文
moreは最も一般的な返信コマンドである。すでにプロンプトで生成された画像に返信する場合、images 。/more コマンドはアップロードされた画像には使えません。
/more moreコマンドは見た目以上に強力だ。Strength、Guidance 、Sizeも使えるので、2段階目のアップスケーラーとしても使え、特にStable Diffusion 1.5モデルには便利です。特にStable Diffusion 1.5のモデルには便利です。このビデオチュートリアルでマスターしてください。
インペイントツール
別名ジェネレイティブ・フィル
インペインティングはマスキングツールで、ある領域の周囲にマスクを描き、そこに新しい何かを促したり、マジックイレーサーのようにオブジェクトを削除したりすることができる。inpaint ツールには、プラスとマイナスのプロンプトボックスがあり、以下のトリガーコードも受け付けます。 concepts .
注:このビデオ以降、私たちのソフトウェアは更新されましたが、同じ原則が適用されます。
VIDEO
生成的塗りつぶし、別名インペインティング Inpaint は、写真のスポット領域を変更するのに便利です。After Detailerとは異なり、inpaint ツールでは、変更したい領域を選択してマスクすることができます。
このツールにはGUIがあり、Stable2goと 統合されています。Inpaint 、ウェブブラウザが開き、そこで文字通り写真にペイントし、プロンプトを表示できるマスク領域を作成します。インペインティングは、アップロードされた非AI写真(手、空、髪型、服などを変更)だけでなく、AIimages にも可能です。
/inpaint ホタルが飛び交う夜
GUIでは、このツールのプルダウンに特別な特定のアートスタイル(inpaint モデル)が用意されていますので、忘れずに選択してください。.strengthとguidance を使って、control 。Strengthは、inpaint プロンプトのみを参照しています。
/inpaint /size:512x768 /strength:1 /guidance:7 fireflies at (night)
ヒント:サイズは元画像から引き継がれ、512×768が推奨されます。サイズを指定しない場合、デフォルトの512×512になり、画像がつぶれてしまう可能性があります。画像内の人物が遠くにいる場合、より忠実度の高い画像でない限り、顔が変わってしまう可能性があります。
また、inpaint を逆手にとって、/bg コマンドで画像から背景を自動的に削除し、次に背景を変更するプロンプトを表示することもできます。 これを実現するには、/bg の結果からマスクIDをコピーします。 次に /maskinvert プロパティを使います。
/inpaint /mask :IAKdybW /maskinvert 惑星や彗星が飛び交う荘厳な夜空の眺め。
OUTPAINT 別名:キャンバスZOOM AND PANNING
最新バージョン (FLUX)
inpaint と同じルールで任意の絵を展開するが、GUI がないため、どのようなアートstyle を使用するかのトリガーワードを指定する必要がある。 スロットの値でその方向を指定することができる。
/workflow /run:zoomout-flux fireflies at night
ディレクションCONTROL
パディングを追加するには、スロットの値を反時計回りに使用します。つまり、slot1 = TOP
/workflow /run:zoomout-flux fireflies at night /slot1 :200 /slot2:50 /slot3:100 /slot4:300
旧バージョン(SDXL)
inpaint と同じルールでどんな絵でも展開するが、GUIはないため、どんな絵style を使うかのトリガーワードを指定しなければならない。アウトペインティングには、まったく同じinpaint モデルが使われる。モデルのページを見るか、または
concept ・インペインティングが可能なモデルをご確認いただけます。
/outpaint fireflies at night <sdxl-inpainting>
アウトペイントには追加のパラメータがあります。top、right、bottom、leftを使い、control 、キャンバスを広げる方向を指定します。sideを省略すると、4方向に均等に広がります。また、背景blur ボケ(1-100)、zoom 係数(1-12)、元の領域の縮小(0-256)を追加できます。強弱をつけると治まります。
/outpaint /side:top /blur:10 /zoom:6 /contract:50 /strength:1 the moon is exploding, fireworks <sdxl-inpainting>
オプションのパラメータ
/side:bottom/top/left/right - このコマンドを追加しない場合は、画像を拡大する方向を指定するか、4つすべてを一度に移動することができます。
/blur:1-100 - 元の領域と新しく追加された領域の間のエッジをぼかします。
/zoom:1-12 - 画像全体のスケールに影響します。デフォルトでは4に設定されています。
/contract0-256 - 元の領域を、塗り潰した領域に比べて小さくします。デフォルトでは64に設定されている。
ヒント:より良い結果を得るには、アウトペイントを使うたびにプロンプトを変更し、新しく拡張された領域に表示したいものだけを含めるようにします。元のプロンプトをコピーしても、意図したとおりに動作するとは限りません。
BGツールを取り外す
高速バックグラウンド・ザッピング
背景除去ツールは、被写体の背後にあるものをすべて除去する簡単なワンステップソリューションです。Images 800×800あたりが最適です。また、インペイントツール (上)を使って、新しい背景をマスクしてプロンプトで配置することもできます。
バックグラウンド削除コマンド リアルな背景を削除するには、次のように返信するだけです。/bg
/bg どのような種類のイラストでも、このanime パラメータを追加すると、除去がよりシャープになります。
/bg /anime また、PNGパラメータを追加して、download 非圧縮画像を指定することもできます。デフォルトでは高解像度のJPGを返します。
/bg /format:png 16進数のカラー値を使って背景の色を指定することもできます。
/bg /anime /format:png /color:FF4433 download マスクを別に用意することもできる。
/bg /マスク
ヒント:マスクで何ができるか?背景だけをプロンプトにする!しかし、それは1つのステップで行うことはできません。まず /showprompt でマスクに返信して、インペイント用の画像コードを取得するか、最近のインペイント用マスクから選んでください。render を作るときに、前景の代わりに背景に /maskinvert を追加してください。
バックグラウンド置換
ControlNet style コマンドを使って 、プリセットから背景を入れ替えることもできる:
背景をアップロードするか、render 背景の写真に返信する /control /new :ベッドルーム(または任意の部屋/エリア) ターゲット画像をアップロードするか、render 。 /bg /replace:Bedroom /blur:10でターゲットに返信する。 blur パラメータは 0-255 の間で、被写体と背景の間のフェザリングを制御します。 背景の置き換えは、被写体全体が見えているとき、つまり体やオブジェクトの一部が他のオブジェクトに遮られていないときに最も効果的に機能します。 これにより、画像が浮いたり、非現実的な背景の折り返しができるのを防ぎます。
オブジェクトをスピンさせる どんな画像でも、まるで3Dオブジェクトのように回転させることができる。背景を/bg
/spin スピンは背景が取り除かれた後が最も効果的です。スピンコマンドは /guidance をサポートしています。私たちのシステムはguidance 2 - 10 をランダムに選択します。詳細については、/steps:100 も追加してください。
写真を説明する 更新されました! 現在、2つの記述モードがあります:CLIPとFLORENCE2
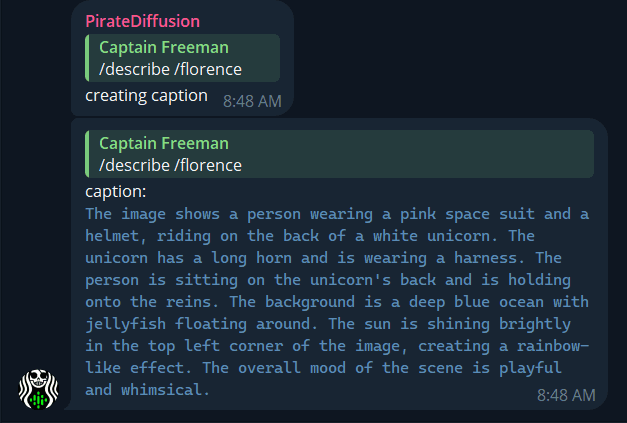
Describeを使えば、コンピュータ・ビジョンを使ってどんな画像からでもプロンプトを生成できる! これは "返信 "コマンドなので、画像に話しかけるように画像を右クリックし、次のように書きます。
/describe /florence
Florence パラメータを追加すると、より詳細なプロンプトが表示されます。これは新しいFlorence2コンピュータビジョンモデルを使用します。/describe 自体はCLIPモデルを使用します。
例
ウィジェットを起動するPirateDiffusion
コードを覚えなくても、簡単にプッシュボタンを作成できるプリセットボタンを作成できます。これはウィジェットシステムによって可能になりました。プロンプトのテンプレートをスプレッドシートに記入し、ボットに接続するだけです。 例えば、widget を作成するキャラクターのテンプレートが用意されています:
ウィジェットはテレグラムとWebUI を同時に作成するので、両方を楽しむことができます! ウィジェットについて ウィジェットについてのビデオ そしてdownload テンプレート をご覧ください。コーディングは不要です!
ファイル&キュー管理 キャンセル /cancel 、レンダリングを中止する。
/cancel DOWNLOAD テレグラムで表示されるimages は、テレグラム内蔵の画像圧縮機能を使用しています。これはファイルサイズを制限します。
/download download がpassword を要求した場合、このチートシートの「プライベートギャラリーの共有とパスワード」のセクションを参照してください。
削除 images を削除するには2つの方法があります:デバイスからローカルに削除する方法と、クラウドドライブから永久に削除する方法です。
images をローカル・デバイスから削除し、クラウド・ドライブに残すには、Telegramに内蔵されている削除機能を使います。画像を長押し(またはPCから右クリック)し、削除を選択します。
クラウドドライブから画像を消去するには、/delete 。
/delete また、/webui と入力してファイルマネージャーを起動し、organize コマンドを使ってimages を一括削除することもできます。
歴史 最近作成したimages のリストを表示します。 公開グループで使用する場合は、その公開チャンネルでのみ作成済みのimages のみが表示されるため、/history はプライバシーにも配慮しています。
/history SHOWPROMPT 比較 画像のプロンプトを表示するには、その画像を右クリックして「/」と入力する。showprompt
/showprompt この便利なコマンドを使うと、画像がどのように作られたかを調べることができます。画像に対して最後に行われたアクションが表示されます。完全な履歴を見るには、次のように書きます: /showprompt /history
showprompt の出力には画像比較ツールが組み込まれている。 そのリンクをクリックすると、ツールがブラウザで開きます。
クリップ /showprompt コマンドはAI画像の正確なプロンプトを表示しますが、非AIimages についてはどうですか?
私たちの/describe コマンドは、あなたがアップロードした写真についてのプロンプトを書くためにコンピュータビジョンの技術を使用します。
/describe /describe が使っている言葉は時に不思議なことがある。例えば "arafed "は楽しい人、活発な人を意味する。
PNG デフォルトでは、PirateDiffusion はimages をロスレスに近い JPG で作成します。JPGではなく、より高解像度のPNGでimages 。警告この場合、ストレージ容量が5倍から10倍になります。ただし、キャッチがあります。TelegramはPNGファイルをネイティブに表示しないので、PNGが作成された後、それを見るには /download コマンド(上記)を使う。
/render a cool cat #everythingbad /format:png ベクトル 画像を SVG / ベクターに変換する!生成またはアップロードされた画像に返信して、trace ベクター、特にSVGとして。ベクターimages は、通常のimages のようにラスタライズされたピクセルでレンダリングされないため、無限にズームすることができる。印刷や製品などに最適。ロゴやステッカーを作成する場合は、/bg コマンドを使用してください。
/trace 利用可能なオプションはすべて以下にリストアップされている。私たちはまだオプションのことを知らないので、VIPチャットであなたの発見を共有することによって、私たちが良いデフォルトに到達するのを助けてください。
speckle - 整数 - デフォルト 4 - 範囲 1 ... 128 - X px より小さいパッチを破棄します. color - デフォルト - 画像の色を指定します。 bw - 画像を白黒にする mode - ポリゴン、スプライン、またはなし - デフォルトスプライン - カーバーフィッティングmode precision - 整数 - デフォルト 6 - 範囲 1 ... 8 - RGB チャンネルで使用する有効ビット数。 gradient - 整数値 - デフォルト 16 - 範囲 1 ..128 -gradient レイヤー間の色差 corner - 整数 - デフォルト 60 - 範囲 1 ... 180 - 瞬間角の最小値(度).corner length - 浮動小数点数 - デフォルト 4 - 範囲 3.5 ... 10 - すべてのセグメントがこの値より短くなるまで、繰り返し細分割を実行します。length 例trace オプションで微調整されたパラメータを持つ:
/trace /color /gradient:32 /corner:1 ウェブUIファイルマネージャ ブラウザーでファイルを管理したり、モデルの視覚的なリストを素早く見たりするのに便利です。
/webui password コマンドなどについては、このページの上部にあるアカウントのセクションをチェックしてください。
RENDER 進行状況MONITOR 必然的に、Telegramは時々接続の問題を起こします。私たちのサーバーがimages 、Telegramに届いていないかどうかを知りたい場合は、このコマンドを使ってください。render 、Cloud Driveからimages 。
/monitor monitor が機能しない場合は、/start を試してください。これでボットが動き出します。 PING 「私たちがダウンしているのか、テレグラムがダウンしているのか、それともキューが私を忘れたのか? /ping は、これらすべての質問に一目で答えようとしている。
/ping ping が機能しない場合は、/start を試してください。これでボットが動き出します。
SETTINGS ボットのデフォルト設定を上書きすることができます。例えば、特定のsampler 、steps 、そしてとても便利なのが、Stable Diffusion 1.5の代わりにお好きなベースモデルを設定することです。
/settings 利用可能settings:
ロードゥ また、/settings コマンドは、レスポンスの下部にロードアウトを表示します。
ロードアウトを保存することで、ワークフローを簡単に切り替えることができます。例えば、anime には好みのベースモデルとsampler を、リアリズムには別のものを、あるいは特定のプロジェクトやクライアントには他のsettings を使用することができます。 ロードアウトを使えば、settings のすべてを瞬時に置き換えることができます。
例えば、僕のsettings 、そのままsave 、Morgan's Presets Feb 14のような名前を作ることができる:
/settings /save:morgans-presets-feb14 ロードアウトの管理:
SILENT MODE プロンプト・リピートの確認など、デバッグ・メッセージが多すぎませんか? この機能を使えば、ボットを完全にsilent 。 ただ、この機能をオンにしたことを忘れないようにしてください。そうしないと、ボットがあなたを無視していると思われ、render の予想時刻や確認事項すら教えてくれません!
/settings /silent:on ONに戻すには、ONをOFFにするだけです。
非推奨&実験的 これは実験のコレクションであり、古いコマンドもまだサポートされているが、新しいテクニックに置き換えられている。これらは本番用にはお勧めしにくいが、それでも使うのは楽しい。
美学採点
Aestheticsは、レンダリングプロセスの一部として、レンダリング画像の美観評価モデルを有効にする実験的なオプションです。これは現在、Graydient APIでも利用可能です。
これらの機械学習モデルは、画像の視覚的品質/美しさを数値で評価しようとするものである。
/render a cool cat <sdxl> /aesthetics これは1~10の美学("美しさ")スコアと1~5のアーティファクト・スコア(低い方が良い)を返す。何が良いか悪いかを見るには、ここにデータセットがある 。 このスコアは、/で見ることもできる。showprompt
BREW
Brew を /polly に置き換えた。
/brew クールな犬 = /polly クールな犬
これは同じ結果を返す。
ミーム
これは冗談で追加したものですが、今でも使えますし、とても愉快です。あなたは、一度に1つのセクションで、あなたの画像の上部と下部にインターネット巨大なIMPACTフォントミームテキストを追加することができます。
/meme/top:人は単純には生きられない。
(次のターン)
/モルドールへの道
インストラクター PIX 2 PIX
で置き換えられた:InpaintアウトペイントRemix
これは当時話題になっていた、Pix2Pixの/editコマンドのインストラクターと呼ばれる技術だ。こんな風に写真に返信する:
/空に花火を追加
風景や自然のimages 、自然言語で「もしも」style の質問をして変化を見る。 このテクノロジーはクールだが、Pix2Pixのインストラクターは解像度の低い結果を出すので、お勧めしにくい。また、独自のアートstyle にロックされているため、私たちのconcepts 、ローラ、エンベッディングなどとは互換性がありません。 512×512の解像度でロックされています。もしあなたがlewdsやanime 、それは仕事に間違ったツールです。代わりに /remix を使用してください。また、control 強度パラメータで効果を与えることもできます。
/edit/strength:0.5 ビルが火事になったら?
スタイル
スタイルはより強力なレシピシステムに取って代わられた。 スタイルは個人的なプロンプトショートカットを作成するために使用され、共有するためのものではありません。コピーコマンドを使って他の人とスタイルを交換することはできますが、そのコードを知らなければ機能しません。このため、レシピはグローバルなものになりました。この機能を使用するには、次のように入力します:
/スタイル
このページは役に立ちましたか?