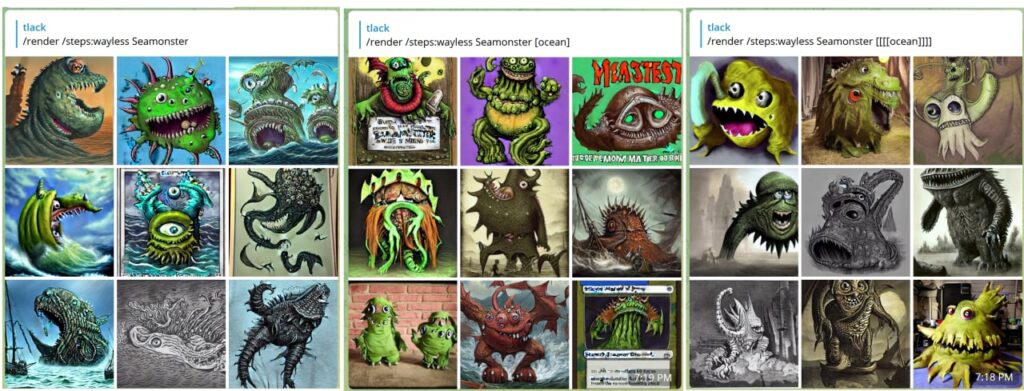
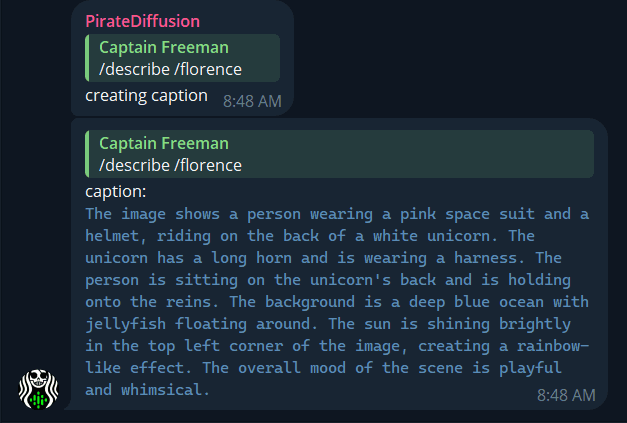
Bitte pausieren Sie vorübergehend oder tragen Sie uns in die Whitelist ein, um ein Konto zu erstellen
Wenn Sie unseren Link von einer App aus geöffnet haben, achten Sie auf die 3 Punkte oben rechts, um unsere Seite in Ihrem Browser zu öffnen. Wir zeigen weder Werbung an noch verkaufen/teilen wir Ihre Daten, aber unsere Website benötigt Javascript, um richtig zu funktionieren. Vielen Dank! -Team Graydient
PirateDiffusion Leitfaden
Pirate Diffusion
Is there a Checkpoint, Embedding, LoRA, or other model that you want preloaded? Request a model install
Pirate Diffusionby Graydient AI is the most powerful bot on Telegram. It is a multi-modal bot, meaning that it handles large language models like DeepSeek and Llama 3.3, tens of thousands of image models like HiDream, Chroma, FLUX, Stable Diffusion 3.5, AuraFlow, Pony, and SDXL and also video models like Wan, Hunyuan and LightTricks (LTX).
Unglaublicher Wert
Im Gegensatz zu anderen generativen KI-Diensten sind keine "Token" oder "Credits" erforderlich. PirateDiffusion ist für die unbegrenzte Nutzung konzipiert, lizenzfrei und wird mit Graydient's webUI gebündelt.
Warum einen Bot verwenden?
Es ist extrem schnell und leichtgewichtig auf dem Handy, und Sie können es allein oder in Gruppen von Fremden oder mit Freunden verwenden. Unser community erstellt Chat-Makros für leistungsstarke ComfyUI-Workflows, so dass Sie den vollen Nutzen eines Desktop-Rendering-Ergebnisses von einem einfachen Chat-Bot erhalten. Das ist der Wahnsinn.
Was kann sie sonst noch tun?
Images, Video, und LLM chats. Es kann so ziemlich alles.
Sie können images mit ein paar Tastenanschlägen ohne GUI erstellen. Sie können alle wichtigen Funktionen von Stable Diffusion per Chat nutzen. Einige Funktionen erfordern eine visuelle Schnittstelle, für die eine Webseite angezeigt wird (Unified WebUI Integration)
Erstellen Sie Ihren privaten Bot oder treten Sie Gruppen bei, um zu sehen, was andere Leute erstellen. Sie können auch thematische bots wie /animebot erstellen, die unsere PollyGPT LLMs mit StableDiffusion-Modellen verbinden, und mit ihnen chatten, um Ihnen beim Erstellen zu helfen! Erstellen Sie eine workflow , die völlig einzigartig für Sie ist, indem Sie Loadouts, recipe (Makros) Widgets (visueller Gui Builder) und benutzerdefinierte bots verwenden. Das macht eine Menge aus!
Die Entstehungsgeschichte
Der Name Pirate Diffusion stammt von dem im Oktober 2022 durchgesickerten Modell Stable Diffusion 1.5, das quelloffen. Wir bauten den ersten Stable Diffusion-Bot auf Telegram und tausende von Leuten kamen dazu, und so haben wir angefangen. Aber um es ganz klar zu sagen: Es geht hier nicht um Piraterie, wir mochten nur den Namen. Trotzdem sagten genug Leute (und unsere Bank), dass der Name ein bisschen viel sei, also haben wir unser Unternehmen in "Graydient" umbenannt, aber wir lieben Pirate Diffusion. Es zieht lustige, interessante Leute an.
Unbegrenzte Video-Generation ist hier für Plus-Mitglieder!
Wenn du Mitglied des Video-Plans von Graydientbist, stehen dir verschiedene Video-Workflows zur Verfügung. Es gibt zwei allgemeine Kategorien von Video-Workflows: die Umwandlung eines Prompts in ein Video und die Umwandlung eines vorhandenen Fotos in ein Video. (In Zukunft wollen wir Video-zu-Video hinzufügen, aber das ist noch nicht verfügbar).
Text to music – two modes!
AUTOMATIC LYRICS
/makesong Write a song about being in the face by a California Rattlesnake. Incorporate "dirty sanchez" and "Roosevelt Hoover"
MANUAL LYRICS
We plan to offer multiple music workflows. The first is called “music-ace” and it works like this:
/workflow /run:music-ace [verse] gonna make some songs [bridge] gonna make em [chorus] with pirate diffusion yeah!
Stöbern Sie zunächst auf unserer Seite mit den Arbeitsabläufen und suchen Sie nach den Text-zu-Video-Kurznamen. Die beliebtesten sind:
WAN 2.1 - das derzeit beste Open-Source-Videomodell, schreibe einen einfachen Prompt und es passiert! WAN scheint eine bessere Prompt-Haftung und -Animation zu haben als HunYuan, aber eine schlechtere Anatomie
Boringvideo - erstellt lebensechte, gewöhnliche Videos, die aussehen, als kämen sie von einem iPhone
HunYuan - drei Arten, siehe unten auf der workflow , um sie zu finden. Hunyuan erstellt die realistischsten Videos. Je höher die "Q"-Zahl, desto höher ist die Qualität, aber desto kürzer sind die Videos.
Video - die, die einfach Video genannt werden, verwenden LTX Lighttricks, ideal für 3D-Cartoons
/wf /run:video-hunylora-q8 cinematic low angle video of a ronald mcdonald clown eating a square hamburger, the restaurant ((sign text says "Wendys")), ronald mcdonald's clown costume has red afro hair and a red nose with white face paint, the restaurant is brown, the burger is pointy and square, the background has blur bokeh and people are walking around
PirateDiffusion unterstützt Hunyuan und LightTricks / LTX Videos und Loras! Wir fügen mehrere Video-Modelle und Sie können sie unbegrenzt als Teil unseres Service, zusammen mit unbegrenzten Bild und unbegrenzte lora Ausbildung verwenden.
In LTX spielt die Struktur der Eingabeaufforderung eine große Rolle. Ein kurzer Prompt führt zu einem statischen Bild. Ein Prompt mit zu vielen Aktionen und Anweisungen führt dazu, dass das Video in verschiedene zufällige Räume oder Figuren schwenkt.
Bewährte Praktiken: Wie Sie Ihre images kohärent bewegen können
Wir empfehlen ein Promptmuster wie dieses:
Beschreiben Sie zunächst, was die Kamera tut oder wen sie verfolgt. Zum Beispiel eine Niedrigwinkelkamera zoom, eine Überkopfkamera, ein langsamer Schwenk, Heraus- oder Wegzoomen usw.
Beschreiben Sie dann die Person und eine Handlung, die sie auf was oder wen ausübt. Dieser Teil erfordert Übung! Im obigen Beispiel kommt Ronald, der den Burger isst, erst nach der Kamera- und Szeneneinstellung
Beschreiben Sie die Szene. Dies hilft der KI, die Dinge zu "segmentieren", die Sie sehen wollen. In unserem Beispiel beschreiben wir also das Clownskostüm und den Hintergrund.
Geben Sie unterstützendes Referenzmaterial an. Sagen Sie zum Beispiel: "Das sieht aus wie eine Szene aus einem Film oder einer Fernsehsendung".
You can specify a lora to control the art direction or character likeness. Add this to the end of the prompt like <move-enhancer-huny>
Bild zu Video
Sie können ein Foto hochladen und es in ein Video verwandeln. Es gibt nicht nur einen Befehl - sehen Sie sich die workflow "Animieren" an, um verschiedene Arten von KI-Modellen zu verwenden. Probieren Sie verschiedene Modelle und Prompt-Strategien aus, um diejenige zu finden, die für Ihr Projekt am besten geeignet ist, oder schauen Sie sich im PLAYROOM-Kanal in PirateDiffusion an, was andere mit ihnen erstellt haben.
Das Seitenverhältnis des Videos wird durch das von Ihnen hochgeladene Bild bestimmt, also schneiden Sie es bitte entsprechend zu.
Fügen Sie dazu zunächst das Foto in den Chat ein und klicken Sie auf "Antworten", als ob Sie mit dem Foto sprechen wollten:
/wf /run:animate-wan21 a woman makes silly faces towards the camera
oder versuchen Sie einen der anderen Workflows wie SkyReels:
/wf /run:animate-skyreels camera video that slightly changes the angle, focused on a lovely girl smiling and looking at the camera, she looks curious and confident while maintaining eyes on the viewer, her hair is parted, she sits in front of a bookshelf and peeping gremlin eyes behind her, she is relaxing vibe
Wir hosten Open-Source-KI-Modelle für Bild-zu-Video. Die beiden beliebtesten sind:
animate-skyreels = Konvertierung eines Bildes in ein Video mit realistischen Videos von HunYuan
animate-ltx90 = verwendet das LightTricks-Modell. Am besten geeignet für 3D-Cartoons und Cinematic Video
Besondere Parameter:
/slot1 = length des Videos in Bildern. Sichere settings sind 89, 97, 105, 113, 121, 137, 153, 185, 201, 225, 241, 257. Mehr ist möglich, aber unstabil
/slot2 = Bilder pro Sekunde. 24 wird empfohlen. Turbo-Workflows laufen mit 18 fps, können aber geändert werden. Mehr als 24 ist filmisch, 30fps sieht realistischer aus. 60 fps sind bei niedrigen Bildern möglich, aber es sieht aus wie Streifenhörnchengeschwindigkeit.
Beschränkungen:
Sie müssen ein Mitglied von Graydient Plus sein, um Videos zu erstellen
Viele Videobeispiele sind heute im VIP- und Playroom-Kanal verfügbar. Kommen Sie vorbei und senden Sie uns Ihre Ideen, während wir dem Video den letzten Schliff geben.
Zurück / Changelog:
Wan 2.1 und Skyreels hinzugefügt. Verwenden Sie workflow /show:, um die Parameter der beiden
Neue Flux wie ur4 (ultra realistic 4) und flux (Bento TWO model) hinzugefügt
Hunyuan und LightTricks / LTX Videos mit Lora-Unterstützung hinzugefügt
Llama 3.3 und viele weitere LLMs hinzugefügt, geben Sie den Befehl //lm ein, um sie zu durchsuchen
Sie können jetzt bis zu sechs Flux loras mit bestimmten Flux Arbeitsabläufen verwenden
Eine HD Anime Illustrious workflow wurde hinzugefügt. Knackig!
Flux Redux, Flux Controlnet Depth, und viele neue Workflows sind jetzt verfügbar
Besser übermalen! Versuchen Sie, auf ein Bild mit /zoomout- zu antworten.flux
Bessere LoRamaker-Integration. Verwenden Sie /makelora, um eine private Lora in Ihrem Webbrowser zu erstellen, und verwenden Sie sie dann in Telegram innerhalb weniger Minuten
Neuer Befehl LLM*. Geben Sie /llm gefolgt von einer beliebigen Frage ein. Es wird derzeit von dem 70-Milliarden-Parameter-Modell Llama 3 angetrieben, und es ist schnell! Wir zensieren Ihre Eingabeaufforderungen nicht, aber das Modell selbst kann einige seiner eigenen Schutzmechanismen haben. *LLM ist die Abkürzung für "Large Language Model", wie bei Chatmodellen ähnlich ChatGPT.
Viele FLUX Kontrollpunkte befinden sich hier. Geben Sie /workflows ein, um sie zu erkunden und ihre Befehle zu erhalten. Ebenfalls neu: eine Abkürzung für Workflows ist /wf. Video-Tutorial
Mehr Modelle, über 10.000! Probieren Sie den neuen Juggernaut 9 Lightning aus, er ist schneller als Juggernaut X. Sie können ihn auch verwenden, indem Sie einfach diesen Hashtag hinzufügen: #jugg9
Benutzerdefinierte bots können jetzt Erinnerungen behalten. Siehe "Erinnerungen" in der PollyGPT-Anleitung
Bessere Überwachung von render ! Tippe /monitor ein, um eine kleine Webseite aufzurufen. Wenn die Telegram-Server Ihrer Stadt beschäftigt oder offline sind, kann die images viel schneller von unserem Cloud Drive abgeholt werden!
Neu Bots! Versuchen Sie es: /xtralargebot /animebot /lightningbot und gesprächige bots wie /kimmybot /angelinabot /nicolebot /senseibot
Mitglieder des Plus-Plans können jetzt Llama3 70 Milliarden Parameter für ihre bots
Neue Rezepte: Probieren Sie #quick für schnelles HD images, oder #quickp für Porträts, #quickw für breite
Polly Aktualisiert! - Verwenden Sie /polly, um mit dem Bot zu chatten, und klicken Sie mit der rechten Maustaste auf die Antwort, um sich zu unterhalten
Polly verwendet jetzt auch nur noch die Modelle, die Sie unter Meine Modelle als Favoriten markiert haben
Der neue /unified-Befehl sendet images an Stable2go zur Web-Bearbeitung
Der neue /bots Befehl - passen Sie Polly nach Ihrem Geschmack an, LLM + Bildmodelle!
Sehen Sie, was als Nächstes ansteht unserer Roadmap und was gerade angekommen ist in unserem Changelog.
Probieren Sie eine neue recipe! Tippen Sie /render #quick und Ihre Eingabeaufforderung
Vorgefertigt & individuell bots
GRUNDLAGEN: Der Befehl LLM
/llm who would win a fight between a pacifist tiger with a shotgun or a thousand angry penguins parachuting above with forks and knives?
Tippen Sie /llm (wie LLM, großes Sprachmodell) und stellen Sie eine Frage, ähnlich wie bei ChatGPT. Es wird durch das Llama3-Modell mit 70 Milliarden Parametern unterstützt.
ERSTELLEN SIE IHREN EIGENEN LLM AGENT
Um zu einem anderen Modell zu wechseln und einen alternativen Chatbot-Charakter zu personalisieren, melden Sie sich bei my.graydient.ai an und klicken Sie auf Chatbots, um andere LLMs wie Mixtral und Wizard auszuwählen.
Wir stellen vor: "POLLY"
Polly ist eine der Figuren in PirateDiffusion , die sprechen und images erstellen. Probieren Sie es aus:
Wenn du im @piratediffusion_bot bist, kannst du mit Polly wie folgt sprechen:
/polly a silly policeman investigates a donut factory
Sie können ihn auch über Ihren Webbrowser nutzen, indem Sie sich bei my.graydient.ai anmelden und auf das Symbol Chat Bots klicken.
EINFÜHRUNG IN DEN BRAUCH BOTS
Polly ist nur eines der vielen Zeichen, die von unserem community erstellt wurden. Um eine Liste anderer öffentlicher Zeichen zu sehen, geben Sie ein:
/bots
Um einen neuen zu erstellen, geben Sie ein
/bots /new
Dadurch wird PollyGPT in Ihrem Webbrowser gestartet, um Ihren eigenen Charakter zu trainieren, der später als Charakter in Ihrem @piratediffusion_bot aufgerufen werden kann.
ERFORSCHUNG DES ZOLLS BOTS
Die AI community ist voll von vielen interessanten Entwicklern. Einige stellen große Sprachmodelle (Alternativen zu ChatGPT) und Open-Source-Bildmodelle (Alternativen zu DALLE und MJ) zur Verfügung. Unsere Original-Software verbindet diese beiden Dinge zu einem einfach zu bedienenden "Bot"-Ersteller in Telegram oder über das Web. Besuchen Sie unsere Polly GPTdocs - now with memories! Seite für weitere Informationen und Vorlagen zum Erstellen Ihrer eigenen bots.
Aktivieren Sie Ihren Bot
Für die Nutzung von PirateDiffusion sind ein Graydient Konto und ein (kostenloses) Telegram-Konto erforderlich. Einrichten
Brauchen Sie Hilfe mit Ihrem Bot? Hängen Sie in mode fest? Kontaktieren Sie uns
Grundlagen des Kontos
NEUER BENUTZER
/start
WIE MAN ANFÄNGT
Melden Sie sich bei my.graydient.ai an, suchen Sie im Dashboard das Symbol Setup und folgen Sie den Anweisungen.
Wenn Sie Ihr Konto auf Patreon aktualisiert haben, müssen Ihre E-Mail und Patreon-E-Mails übereinstimmen. Wenn Sie nicht alle Funktionen aktivieren und freischalten können, geben Sie bitte /debug ein und senden Sie diese Nummer
USERNAME
/username Tiny Dancer
Der Bot verwendet Ihren Telegram-Namen als Ihren öffentlichen community username (wird an Stellen wie Rezepten und images angezeigt). Sie können dies jederzeit mit dem Befehl /username ändern, z. B. so:WEBUI und PASSWORDPirateDiffusion wird mit einem Website-Begleiter für schwierige Vorgänge wie das Organisieren Ihrer Dateien und das Einfügen von Bildern geliefert. Um auf Ihr Archiv zuzugreifen, geben Sie ein:
/webui
Sie ist standardmäßig privat. Um Ihre password einzustellen, verwenden Sie einen Befehl wie diesen
Ein Prompt ist eine vollständige Beschreibung, die der KI sagt, welches Bild sie erzeugen soll:
Sollte es realistisch sein? Eine Art von Kunstwerk?
Beschreiben Sie die Tageszeit, den Blickwinkel und die Beleuchtung
Beschreiben Sie die Person und ihre Handlungen gut
Beschreiben Sie zuletzt den Ort und andere Details
Grundlegendes Beispiel:
eine 25-jährige blonde Frau, Instagram-Influencerin, die den Reisewagen-Lifestyle lebt
Tipp: Verwenden Sie /render #quick - ein Makro, um diese Qualität zu erreichen, ohne Negative zu tippen
Tipps zur Schnellabfrage
1. Beschreiben Sie immer das ganze Bild, jedes Mal
Eine Eingabeaufforderung ist keine Chat-Nachricht, d. h. es handelt sich nicht um eine Unterhaltung mit mehreren Runden. Jede Eingabeaufforderung ist ein ganz neuer Zug am System, der alles vergisst, was in der vorherigen Runde eingegeben wurde. Wenn wir zum Beispiel "ein Hund in einem Kostüm" eingeben, werden wir es mit Sicherheit bekommen. Diese Aufforderung beschreibt vollständig ein Foto. Wenn wir nur die Aufforderung "mach ihn rot" (unvollständige Idee) geben, werden wir den Hund gar nicht sehen, weil "er" nicht übertragen wurde, so dass die Aufforderung missverstanden wird. Geben Sie immer die vollständige Anweisung.
2. Die Wortfolge ist wichtig
Setzen Sie die wichtigsten Wörter an den Anfang der Aufforderung. Wenn Sie ein Porträt erstellen, stellen Sie das Aussehen der Person an den Anfang und was sie trägt, gefolgt von dem, was und wo sie ist, als unwichtigste Details.
3. Length ist ebenfalls von Bedeutung.
Die Wörter am Anfang sind am wichtigsten, und jedes Wort gegen Ende wird immer weniger beachtet - bis zu etwa 77 "Token" oder Anweisungen. Sie sollten jedoch wissen, dass jede KI concept in unserem System auf unterschiedliche Themen trainiert ist, so dass die Wahl der richtigen concept einen Einfluss darauf hat, wie gut Sie verstanden werden. Am besten ist es, wenn Sie sich auf das Wesentliche beschränken und das concepts System (siehe unten), anstatt lange Aufforderungen zu schreiben, um die besten Ergebnisse zu erzielen.
Positive Aufforderungen
Positive Prompts und Negative Prompts sind Worte, die der KI mitteilen, was wir sehen wollen und was nicht. Menschen kommunizieren normalerweise nicht in solch binärer Form, aber in einer sehr lauten Umgebung sagen wir vielleicht "dies, aber das!
Positiv: Eine Strandszene bei Tag mit klarem, blauem Sand, Palmen Negativ: Menschen, Boote, Bikinis, NSFW
Dies wird in den beiden Feldern des Stable2go-Editors wie folgt eingegeben:
Positive Aufforderungen enthalten das Thema und unterstützende Details des Bildes. Es hilft, die Kunst style und die Umgebung zu beschreiben, sowie Ihre Erwartungen an die Ästhetik. Beispiele:
realistisches Foto eines Welpen in bester Qualität
Meisterwerk Zeichnung einer Sonnenblume, Bokeh Hintergrund
Foto eines Motorrollers in einer Einfahrt, Aquarelle
eine Schildkröte mit einem ((Bier))
Wichtig: Ein Befehl zur Erstellung eines Abbilds muss vor der positiven Eingabeaufforderung stehen, z. B. /render und /polly. Siehe Syntax unten:
Positives noch stärker machen
Um bestimmte Wörter stärker zu betonen, fügen Sie verschachtelte Klammern hinzu. Dadurch wird ihr Faktor um das 1,1-fache erhöht.
Im obigen Beispiel sagen wir, dass "Schildkröte" das Thema ist, weil es am Anfang der Aufforderung steht, aber das Bier ist genauso wichtig, auch wenn es später in der Aufforderung steht. Wenn Sie unwahrscheinliche Situationen schaffen, hilft eine zusätzliche Betonung.
FehlersucheWenn das Bild überstrahlt aussieht und guidance auf 7 eingestellt ist, sind die Negative möglicherweise zu stark eingestellt. Versuchen Sie, ihre Intensität zu verringern.
Positiv und Negativ waren früher die einzige Möglichkeit, die KI so zu steuern, dass sie das bekommt, was wir wollten, aber das ist nicht mehr nötig. Verwenden Sie stattdessen concepts (siehe unten) weitere Beispiele
Profi-Befehle
Erstellen Sie images wie ein stabiler Diffusionsprofi mit diesen Parametern:
RENDER
Wenn Sie keine Eingabeaufforderung von Polly oder Ihrer benutzerdefinierten bots wünschen, können Sie den Befehl /render verwenden, um vollständig manuell zu arbeiten. Versuchen Sie eine kurze Lektion.
/render a close-up photo of a gorilla jogging in the park <sdxl>
Positives sagt der KI, was sie betonen soll. Dies wird mit (runden Klammern) ausgedrückt. Jedes Klammerpaar steht für ein 1,1-faches der positiven Verstärkung. Negative Werte bewirken das Gegenteil und werden mit [eckigen] Klammern ausgedrückt.
Wenn Sie zu viele Klammern hinzufügen, kann dies die Möglichkeiten der KI einschränken. Wenn Sie also Störungen in Ihrem Bild feststellen, sollten Sie versuchen, die Anzahl der Klammern und Umkehrungen zu reduzieren.
Tipp: So können Sie eine Eingabeaufforderung schnell bearbeiten: Nachdem eine Eingabeaufforderung abgeschickt wurde, können Sie sie schnell wieder aufrufen, indem Sie auf dem Telegramm-Desktop den Pfeil nach oben drücken. Oder tippen Sie einfach auf die Eingabeaufforderungsbestätigung, die in alter Schrift erscheint. Die Wortreihenfolge ist wichtig. Setzen Sie die wichtigsten Wörter an den Anfang Ihres Prompts, um beste Ergebnisse zu erzielen: Kamerawinkel, Wer, Was, Wo.
TRANSLATE
Möchten Sie lieber in einer anderen Sprache antworten? Sie können render images in über 50 Sprachen aufrufen, z. B. so:
/render /translate un perro muy guapo <sdxl>
Es muss nicht angegeben werden, welche Sprache es ist, es weiß es einfach. Wenn Sie übersetzen, vermeiden Sie Slang. Wenn die KI Ihre Eingabeaufforderung nicht verstanden hat, versuchen Sie, sie mit klareren Worten zu formulieren.
Einschränkungen bei der Übersetzung
Einige regionale Ausdrücke können missverstanden werden, daher sollten Sie bei der Verwendung der Übersetzungsfunktion so wörtlich und genau wie möglich vorgehen. Zum Beispiel könnte "cubito de hielo" auf Spanisch "kleiner Eiswürfel" oder "kleiner Eimer mit Eis" bedeuten, je nach Region und kontextueller Nuance.
Fairerweise muss man sagen, dass dies auch im Englischen passieren kann, da die KI Dinge zu wörtlich nehmen kann. Ein Nutzer wollte zum Beispiel einen Eisbären jagen , und die KI gab ihm ein Scharfschützengewehr. Böswillige Erfüllung!
Um dies zu vermeiden, sollten Sie in Ihrer positiven und negativen Aufforderung mehrere Wörter verwenden.
RECIPE MACROS
Rezepte sind Vorlagen für Eingabeaufforderungen. Eine recipe kann Token, Sampler, Modelle, Textumkehrungen und mehr enthalten. Dies ist eine echte Zeitersparnis und es lohnt sich, es zu lernen, wenn Sie sich dabei ertappen, dass Sie immer wieder dieselben Dinge in Ihrem Prompt wiederholen.
Als wir negative Umkehrungen einführten, fragten viele: "Warum sind diese nicht standardmäßig aktiviert?", und die Antwort lautet control - jeder mag etwas anderes settings. Unsere Lösung für dieses Problem waren Rezepte: Hashtags, die Prompt-Vorlagen aufrufen.
Um eine Liste dieser Vorlagen zu sehen, geben Sie /recipes ein oder durchsuchen Sie sie auf unserer Website: die Hauptliste der Prompt-Vorlagen
/recipes
Die meisten Rezepte wurden von community erstellt und können sich jederzeit ändern, da sie von ihren jeweiligen Eigentümern verwaltet werden. Eine Eingabeaufforderung sollte nur 1 recipe haben, sonst kann es unübersichtlich werden.
Es gibt zwei Möglichkeiten, ein recipe zu verwenden: Sie können es mit einem Hashtag beim Namen nennen, wie das "quick" recipe:
/render a cool dog #quick
Einige beliebte Rezepte sind #nfix und #eggs und #boost und #everythingbad und #sdxlreal.
Wichtig: Wenn Sie eine recipe erstellen, müssen Sie $prompt irgendwo in den positiven Prompt-Bereich einfügen, sonst kann recipe Ihre Texteingabe nicht akzeptieren. Sie können das irgendwo einfügen, es ist flexibel.
Im Feld "Andere Befehle" können Sie weitere qualitätssteigernde Parameter stapeln.
COMPOSE
Compose ermöglicht die Erstellung mehrerer Prompts und Regionen. Die verfügbaren Zonen sind: background, bottom, bottomcenter, bottomleft, bottomright, center, left, right, top, topcenter, topleft, topright. Das Format für jede Zone ist x1, y1, x2, y2
/compose /size:2000x700 /left:The tower of Thai food /center:Jungles of Thailand, tropical rainforest [blurry] /right: Castle made of stone, castle in the jungle, tropical vegetation
Ein weiteres Beispiel
/compose /seed:1 /images:2 /size:384×960 /top:ZeldaKingdom GloomyCumulonimbus /bottom:1983Toyota Have a Cookie /guidance:5
Tipp: Verwenden Sie für eine bessere Überblendung eine guidance von etwa 5. Sie können auch das Modell angeben. Guidance gilt für das gesamte Bild. Wir arbeiten daran, regionale guidance hinzuzufügen.
/compose /size:1000x2000 /top: Lion roaring, lion on top of building /center: Apartment building, front of building, entrance /bottom: Dirty city streets, New York city streets [[ugly]] [[blurry] /images:1 /guidance:7
Blend ermöglicht es Ihnen, mehrere images zu verschmelzen, die images in Ihrer ControlNet Bibliothek gespeichert sind. Dies basiert auf einer Technologie namens IP-Adapter. Dieser Name ist für die meisten Leute furchtbar verwirrend, deshalb nennen wir ihn einfach blend.
Erstellen Sie zunächst einige voreingestellte Bilder concepts , indem Sie ein Foto in Ihren Bot einfügen und ihm einen Namen geben, genau wie Sie es für ControlNet tun würden. Wenn Sie bereits Steuerelemente gespeichert haben, funktionieren auch diese.
/control /new:chicken
Wenn Sie zwei oder mehr davon haben, können Sie sie unter blend zusammenfassen.
/render /blend:chicken:1 /blend:zelda:-0.4
Tipp: IP-Adapter unterstützt negative images. Es wird empfohlen, ein Rauschbild zu subtrahieren, um bessere Bilder zu erhalten.
Sie können control das Rauschen des Bildes mit /blendnoise
Die Voreinstellung ist 0,25. Sie können es mit /blendnoise:0.0 deaktivieren.
Sie können auch die Stärke des IP-Adapter-Effekts mit /blendguidance einstellen - der Standardwert ist 0,7
Tipp: Blend kann auch beim Inpainting und bei SDXL-Modellen verwendet werden.
/render /adetailer a close-up photo of a gorilla jogging in the park <sdxl>
Damit wird Ihr Bild sofort nach der Erstellung auf fehlerhafte Hände, Augen und Gesichter untersucht und automatisch korrigiert. Es funktioniert mit SDXL und SD15 ab März '24
Einschränkungen: Es kann sein, dass Gesichter, die um ~15 Grad gedreht sind, übersehen werden oder dass in diesem Fall zwei Gesichter erstellt werden.
After Detailer funktioniert am besten, wenn es zusammen mit guten positiven und negativen Aufforderungen und Umkehrungen verwendet wird (siehe unten):
FREE U
FreeU (Free Lunch in Diffusion U-Net) ist ein experimenteller Detaillierer, der den Bereich guidance in vier verschiedenen Intervallen während der render erweitert. Es gibt 4 mögliche Werte, jeder zwischen 0-2. b1: Backbone-Faktor der ersten Stufe b2: Backbone-Faktor der zweiten Stufe s1: Skip-Faktor der ersten Stufe s2: Skip-Faktor der zweiten Stufe
/render <av5> a drunk horse in Rome /freeu:1.1,1.2,0.9,0.2
Befehle zur Bilderstellung
POLLY
Polly ist Ihr Assistent für die Bilderstellung und der schnellste Weg, um detaillierte Eingabeaufforderungen zu schreiben. Wenn Sie 'Fave ein Modell in conceptseingeben, wählt Polly einen Ihrer Favoriten nach dem Zufallsprinzip aus.
Um Polly in Telegram zu verwenden, sprechen Sie wie folgt mit ihm:
/polly a silly policeman investigates a donut factory
Die Antwort enthält eine Eingabeaufforderung, die Sie unter render abrufen oder in die Zwischenablage kopieren können, um sie mit dem Befehl /render (siehe unten) zu verwenden.
Sie können auch ein normales Chat-Gespräch führen, indem Sie mit /raw beginnen
/polly /raw explain the cultural significance of japanese randoseru
Sie können es auch über Ihren Webbrowser verwenden, indem Sie sich bei my.graydient.ai anmelden und auf das Symbol Polly klicken.
Bots zeigt eine Liste der Assistenten an, die Sie erstellt haben. Wenn meine Assistentin zum Beispiel Alice heißt, kann ich sie wie folgt benutzen: /alicebot go make me a sandwich. Das @piratediffusion_bot muss sich im selben Kanal wie Sie befinden.
Um einen neuen zu erstellen, geben Sie ein
/bots /new
RENDER
Wenn Sie keine Eingabeaufforderung von Polly oder Ihrer benutzerdefinierten bots wünschen, können Sie den Befehl /render verwenden, um vollständig manuell zu arbeiten. Versuchen Sie eine kurze Lektion.
/render a close-up photo of a gorilla jogging in the park <sdxl>
Positives sagt der KI, was sie betonen soll. Dies wird mit (runden Klammern) ausgedrückt. Jedes Klammerpaar steht für ein 1,1-faches der positiven Verstärkung. Negative Werte bewirken das Gegenteil und werden mit [eckigen] Klammern ausgedrückt.
Wenn Sie zu viele Klammern hinzufügen, kann dies die Möglichkeiten der KI einschränken. Wenn Sie also Störungen in Ihrem Bild feststellen, sollten Sie versuchen, die Anzahl der Klammern und Umkehrungen zu reduzieren.
Tipp: So können Sie eine Eingabeaufforderung schnell bearbeiten: Nachdem eine Eingabeaufforderung abgeschickt wurde, können Sie sie schnell wieder aufrufen, indem Sie auf dem Telegramm-Desktop den Pfeil nach oben drücken. Oder tippen Sie einfach auf die Eingabeaufforderungsbestätigung, die in alter Schrift erscheint. Die Wortreihenfolge ist wichtig. Setzen Sie die wichtigsten Wörter an den Anfang Ihres Prompts, um beste Ergebnisse zu erzielen: Kamerawinkel, Wer, Was, Wo.
TRANSLATE
Möchten Sie lieber in einer anderen Sprache antworten? Sie können render images in über 50 Sprachen aufrufen, z. B. so:
/render /translate un perro muy guapo <sdxl>
Es muss nicht angegeben werden, welche Sprache es ist, es weiß es einfach. Wenn Sie übersetzen, vermeiden Sie Slang. Wenn die KI Ihre Eingabeaufforderung nicht verstanden hat, versuchen Sie, sie mit klareren Worten zu formulieren.
Einschränkungen bei der Übersetzung
Einige regionale Ausdrücke können missverstanden werden, daher sollten Sie bei der Verwendung der Übersetzungsfunktion so wörtlich und genau wie möglich vorgehen. Zum Beispiel könnte "cubito de hielo" auf Spanisch "kleiner Eiswürfel" oder "kleiner Eimer mit Eis" bedeuten, je nach Region und kontextueller Nuance.
Fairerweise muss man sagen, dass dies auch im Englischen passieren kann, da die KI Dinge zu wörtlich nehmen kann. Ein Nutzer wollte zum Beispiel einen Eisbären jagen , und die KI gab ihm ein Scharfschützengewehr. Böswillige Erfüllung!
Um dies zu vermeiden, sollten Sie in Ihrer positiven und negativen Aufforderung mehrere Wörter verwenden.
RECIPE MACROS
Rezepte sind Vorlagen für Eingabeaufforderungen. Eine recipe kann Token, Sampler, Modelle, Textumkehrungen und mehr enthalten. Dies ist eine echte Zeitersparnis und es lohnt sich, es zu lernen, wenn Sie sich dabei ertappen, dass Sie immer wieder dieselben Dinge in Ihrem Prompt wiederholen.
Als wir negative Umkehrungen einführten, fragten viele: "Warum sind diese nicht standardmäßig aktiviert?", und die Antwort lautet control - jeder mag etwas anderes settings. Unsere Lösung für dieses Problem waren Rezepte: Hashtags, die Prompt-Vorlagen aufrufen.
Um eine Liste dieser Vorlagen zu sehen, geben Sie /recipes ein oder durchsuchen Sie sie auf unserer Website: die Hauptliste der Prompt-Vorlagen
/recipes
Die meisten Rezepte wurden von community erstellt und können sich jederzeit ändern, da sie von ihren jeweiligen Eigentümern verwaltet werden. Eine Eingabeaufforderung sollte nur 1 recipe haben, sonst kann es unübersichtlich werden.
Es gibt zwei Möglichkeiten, ein recipe zu verwenden: Sie können es mit einem Hashtag beim Namen nennen, wie das "quick" recipe:
/render a cool dog #quick
Einige beliebte Rezepte sind #nfix und #eggs und #boost und #everythingbad und #sdxlreal.
Wichtig: Wenn Sie eine recipe erstellen, müssen Sie $prompt irgendwo in den positiven Prompt-Bereich einfügen, sonst kann recipe Ihre Texteingabe nicht akzeptieren. Sie können das irgendwo einfügen, es ist flexibel.
Im Feld "Andere Befehle" können Sie weitere qualitätssteigernde Parameter stapeln.
COMPOSE
Compose ermöglicht die Erstellung mehrerer Prompts und Regionen. Die verfügbaren Zonen sind: background, bottom, bottomcenter, bottomleft, bottomright, center, left, right, top, topcenter, topleft, topright. Das Format für jede Zone ist x1, y1, x2, y2
/compose /size:2000x700 /left:The tower of Thai food /center:Jungles of Thailand, tropical rainforest [blurry] /right: Castle made of stone, castle in the jungle, tropical vegetation
Ein weiteres Beispiel
/compose /seed:1 /images:2 /size:384×960 /top:ZeldaKingdom GloomyCumulonimbus /bottom:1983Toyota Have a Cookie /guidance:5
Tipp: Verwenden Sie für eine bessere Überblendung eine guidance von etwa 5. Sie können auch das Modell angeben. Guidance gilt für das gesamte Bild. Wir arbeiten daran, regionale guidance hinzuzufügen.
/compose /size:1000x2000 /top: Lion roaring, lion on top of building /center: Apartment building, front of building, entrance /bottom: Dirty city streets, New York city streets [[ugly]] [[blurry] /images:1 /guidance:7
Blend ermöglicht es Ihnen, mehrere images zu verschmelzen, die images in Ihrer ControlNet Bibliothek gespeichert sind. Dies basiert auf einer Technologie namens IP-Adapter. Dieser Name ist für die meisten Leute furchtbar verwirrend, deshalb nennen wir ihn einfach blend.
Erstellen Sie zunächst einige voreingestellte Bilder concepts , indem Sie ein Foto in Ihren Bot einfügen und ihm einen Namen geben, genau wie Sie es für ControlNet tun würden. Wenn Sie bereits Steuerelemente gespeichert haben, funktionieren auch diese.
/control /new:chicken
Wenn Sie zwei oder mehr davon haben, können Sie sie unter blend zusammenfassen.
/render /blend:chicken:1 /blend:zelda:-0.4
Tipp: IP-Adapter unterstützt negative images. Es wird empfohlen, ein Rauschbild zu subtrahieren, um bessere Bilder zu erhalten.
Sie können control das Rauschen des Bildes mit /blendnoise
Die Voreinstellung ist 0,25. Sie können es mit /blendnoise:0.0 deaktivieren.
Sie können auch die Stärke des IP-Adapter-Effekts mit /blendguidance einstellen - der Standardwert ist 0,7
Tipp: Blend kann auch beim Inpainting und bei SDXL-Modellen verwendet werden.
/render /adetailer a close-up photo of a gorilla jogging in the park <sdxl>
Damit wird Ihr Bild sofort nach der Erstellung auf fehlerhafte Hände, Augen und Gesichter untersucht und automatisch korrigiert. Es funktioniert mit SDXL und SD15 ab März '24
Einschränkungen: Es kann sein, dass Gesichter, die um ~15 Grad gedreht sind, übersehen werden oder dass in diesem Fall zwei Gesichter erstellt werden.
After Detailer funktioniert am besten, wenn es zusammen mit guten positiven und negativen Aufforderungen und Umkehrungen verwendet wird (siehe unten):
FREE U
FreeU (Free Lunch in Diffusion U-Net) ist ein experimenteller Detaillierer, der den Bereich guidance in vier verschiedenen Intervallen während der render erweitert. Es gibt 4 mögliche Werte, jeder zwischen 0-2. b1: Backbone-Faktor der ersten Stufe b2: Backbone-Faktor der zweiten Stufe s1: Skip-Faktor der ersten Stufe s2: Skip-Faktor der zweiten Stufe
/render <av5> a drunk horse in Rome /freeu:1.1,1.2,0.9,0.2
Concepts Übersicht
Concepts sind spezialisierte KI-Modelle, die bestimmte Dinge generieren, die mit Prompting allein nicht gut verstanden werden können. Mehrere concepts können zusammen verwendet werden: In der Regel werden ein Basismodell und 1-3 LoRas oder Inversionen am häufigsten verwendet.
Sie können auch Ihr eigenes Training durchführen, indem Sie die Trainingsweboberfläche aufrufen:
/makelora
Ein Hinweis zu maßgeschneiderten Loras und Privatsphäre:
Private Loras: Benutze immer den Befehl /makelora aus deiner privaten Konversation mit @piratediffusion_bot, um einen Lora zu erstellen, den nur du sehen kannst. Sie können dies auch innerhalb Ihrer privaten Subdomain verwenden, aber es wird NICHT auf der gemeinsamen Instanz von Stable2go oder Quick Create in MyGraydient erscheinen.
Öffentlicher Loras: Um Ihr LoRa zu trainieren und mit der ganzen community zu teilen, loggen Sie sich in my.graydient.ai ein und klicken Sie auf das LoRaMaker-Symbol. Diese Loras werden für alle erscheinen, auch für Ihren Telegrammbot.
Modellfamilie Unsere Software unterstützt zur Zeit zwei Stable Diffusion-Familien: SD15 (älter, trainiert mit 512×512) und Stable Diffusion XL, das von Haus aus 1024×1024 ist. Wenn Sie sich an diese Auflösungen halten, erzielen Sie die besten Ergebnisse (und vermeiden doppelte Gliedmaßen usw.)
Der wichtigste Punkt ist, dass die Familien nicht miteinander kompatibel sind. Eine SDXL-Basis kann nicht mit einer SD15-Lora verwendet werden und umgekehrt.
Syntax:
LISTE DER MODELLE
The term AI model can also mean chat models, so we call image models “concepts”. A concept can be a person, pose, effect, or art style. To bring those things into your creation, we call their “trigger word” which appear in angled brackets like this: <sdxl> Our platform has over 8 terabytes of AI concepts preloaded. PirateDiffusion is never stuck in one style, we add new ones daily.
/concepts
Der Zweck des Befehls /concepts ist es, schnell Auslösewörter für Modelle als Liste in Telegram nachzuschlagen. Am Ende dieser Liste finden Sie auch einen Link, um concepts visuell auf unserer Website zu durchsuchen.
Verwendung von concepts
Um ein Bild zu erstellen, koppeln Sie das Auslösewort von conceptmit dem Befehl render (siehe unten) und beschreiben das Foto.
To use one, use it’s trigger name anywhere in the prompt. For example, one of the most popular concepts of the moment is called Realistic Vision 5 SDXL, a realistic “base model” — the basis of the overall image style. The trigger name for Realistic Vision 5 SDXL is <realvis5-xl> so we would then prompt.
/render a dog <realvis4-xl>
Tipp: Wählen Sie 1 Basismodell (z. B. realvis4-xl), einen oder drei Loras und einige negative Umkehrungen, um ein ausgewogenes Bild zu erhalten. Das Hinzufügen von zu vielen oder widersprüchlichen concepts (z. B. 2 Posen) kann Artefakte verursachen. Probieren Sie eine Lektion aus oder erstellen Sie selbst eine
MODELLE SUCHEN
Sie können direkt von Telegram aus suchen.
/concept /search:emma
NEUE MODELLE
Erinnern Sie sich schnell an die letzten, die Sie ausprobiert haben:
/concept /recent
LIEBLINGSMODELLE
Verwenden Sie den Befehl fave , um Ihre Lieblingsmodelle in einer persönlichen Liste zu erfassen und zu speichern.
/concept /fave:concept-name
MEIN STANDARDMODELL
Stable Diffusion 1.5 ist das Standardmodell, aber warum ersetzen Sie es nicht durch Ihr bevorzugtes Modell?
This will impact both your Telegram and Stable2go account. After you do this command, you don’t have to write that <concept-name> every time in your prompts. Of course, you can override it with a different model in a /render.
/concept /default:concept-name
Arten von Concepts
Basismodelle werden auch "Vollmodelle" genannt, die am stärksten die style des Bildes bestimmen. LoRas und Textual Inversions sind kleinere Modelle für Feinkontrollen. Dabei handelt es sich um kleine Dateien, die sich auf ein bestimmtes Motiv beziehen, in der Regel eine Person oder eine Pose. Inpainting-Modelle werden nur von den Werkzeugen Inpaint und Outpaint verwendet und sollten nicht für Rendering oder andere Zwecke eingesetzt werden.
Besondere concept Tags
Das System concepts ist nach Schlagwörtern geordnet und bietet eine breite Palette von Themen, von Tieren bis zu Posen.
Es gibt einige spezielle Tags, die Typen genannt werden, die Ihnen sagen, wie sich das Modell verhält. Es gibt auch Ersatztypen für positive und negative Prompts, die Detailer und Negative genannt werden. Wenn Sie den Typ Negativ concept verwenden, denken Sie daran, auch die Gewichtung als negativ einzustellen.
NEGATIVE INVERSIONEN
Das Modellsystem verfügt über spezielle Modelle, die als negative Invertierungen oder auch negative Einbettungen bezeichnet werden. Diese Modelle wurden absichtlich auf schrecklich aussehende images trainiert, um der KI zu zeigen, was sie nicht tun soll. Indem diese Modelle als Negative aufgerufen werden, erhöhen sie die Qualität erheblich. Die Gewichtung dieser Modelle muss in doppelten [[negativen Klammern]] liegen, zwischen -0,01 und -2.
/render <sdxl> [[<fastnegative-xl:-2>]]
Takoyaki on a plate
Modelle mit schnell klingenden Namen wie "Hyper" und "Turbo" können render images schnell mit niedrigen Parametern, die unten in Guidance / CFG.
Diese Zahlen neben den Modellnamen sind "Gewichte".
Unter control können Sie den Einfluss eines Modells auf Ihr Bild bestimmen, indem Sie seine Gewichtung anpassen. Wir brauchen Gewichtungen, weil Modelle eine eigene Meinung haben und das Bild in ihre eigene Trainingsrichtung ziehen. Wenn mehrere Modelle hinzugefügt werden, kann dies zu Verpixelung und Verzerrung führen, wenn sie nicht übereinstimmen. Um dieses Problem zu lösen, können wir die Gewichtung jedes Modells verringern oder erhöhen, um das Gewünschte zu erreichen.
Die Regeln der Gewichte
Vollständige Modelle sind nicht einstellbar. Auch bekannt als Kontrollpunkte oder Basismodelle genannt, sind dies große Dateien, die das Gesamtbild style bestimmen. Um den künstlerischen Einfluss des Basismodells zu ändern, müssen wir es einfach gegen ein anderes Basismodell austauschen. Das ist der Grund, warum wir so viele davon im System haben.
LoRas und Textual Inversions haben flexible Gewichte.
Wenn man die Gewichtung zum Positiven hin verschiebt, werden diese Modelle mutiger. Laienhaft ausgedrückt sind LoRas detailliertere Versionen von Textumkehrungen.
BESTE PRAXIS
Verwenden Sie immer 1 Basismodell, und fügen Sie Loras und Inversionen hinzu.
Wenn Sie mehrere Basismodelle laden, werden diese nicht blend , sondern nur eines geladen, aber die anderen, die Sie geladen haben, werden "tokenisiert", d. h. Sie können einfach ihre Namen eingeben, und das Gleiche geschieht, ohne dass Ihr render verlangsamt wird (weniger Modelle im Speicher = schneller).
Bei LoRas und Inversionen kann man beides und viele davon gleichzeitig einsetzen, obwohl die meisten Leute bei 1-3 bleiben, da das leichter auszugleichen ist.
SDXL-Nutzer werden im System viele Tags mit der Bezeichnung "-type" finden. Dies ist eine Unterfamilie von Modellen, die am besten funktionieren, wenn sie zusammen geladen werden. Zum Zeitpunkt dieses Leitfadens ist der beliebteste Typ Pony (nicht wörtlich Ponys), die eine bessere Prompt-Kohäsion haben, vor allem für sexy Sachen. Pony-Loras funktionieren am besten mit Pony-Basismodellen, und so weiter.
POSITIVE MODELLGEWICHTE
Die Grenzen für die Gewichtung sind -2 (negativ) und 2 (maximal). Eine Gewichtung zwischen 0,4 und 0,7 funktioniert normalerweise am besten. Zahlen über 0,1 haben eine ähnliche Wirkung wie eine ((positive Eingabeaufforderung)). Es stehen mehr als zehn Stellen für die Dezimalpräzision zur Verfügung, aber die meisten Leute bleiben bei einer einzigen Stelle, und das ist auch unsere Empfehlung.
Es ist möglich, das Bild negativ zu beeinflussen, um einen positiven Nettoeffekt zu erzielen.
Zum Beispiel hat jemand eine Sammlung von knorrig aussehenden KI-Händen trainiert, und wenn man diese als Negativ lädt, entstehen schöne Hände. Die Lösung war ziemlich raffiniert. In unserem System finden Sie viele solcher Qualitätshacks. Sie save uns Zeit von immer wieder Dinge wie [[schlechte Qualität]] zu tippen. Wenn Sie ein negatives Modell verwenden, schieben Sie die Gewichtung ins Negative, typischerweise -1 oder -2. Das hat einen ähnlichen Effekt wie eine [[negative Eingabeaufforderung]].
Fehlersuche
Die Verwendung mehrerer Modelle kann wie das gleichzeitige Abspielen mehrerer Lieder sein: Wenn sie alle gleich laut sind, ist es schwer, etwas herauszuhören.
Wenn images zu blockig oder pixelig erscheint, stellen Sie sicher, dass Sie ein Basismodell haben und guidance auf 7 oder niedriger eingestellt ist und dass Ihre Positiv- und Negativbilder nicht zu stark sind. Versuchen Sie, die Gewichtung anzupassen, um das beste Gleichgewicht zu finden. Weitere Informationen über Guidance und Parameter finden Sie in der folgenden Anleitung.
Parameter
Auflösung: Breite und Höhe
KI-Modellfotos werden auf eine bestimmte Größe "trainiert", so dass die besten Ergebnisse erzielt werden, wenn images in der Nähe dieser Größe erstellt wird. Wenn wir versuchen, zu früh zu groß zu werden, kann dies zu Störungen führen (Zwillinge, zusätzliche Gliedmaßen).
Leitlinien
Stabile Diffusion XL-Modelle: Beginnen Sie bei 1024×1024, und unter 1400×1400 ist es normalerweise sicher.
Stable Diffusion 1.5 wurde mit 512×512 trainiert, die Obergrenze liegt also bei 768×768. Einige fortgeschrittene Modelle wie Photon erreichen 960×576. weitere Tipps zur SD15-Größe
Sie können jederzeit in einem zweiten Schritt auf 4K hochskalieren, siehe die Informationen unter Facelift .
Syntax
Sie können die Form eines Bildes leicht mit diesen Kurzbefehlen ändern: /portrait /Hoch /Landschaft /wide
/render /portrait a gorilla jogging in the park <sdxl>
Sie können die Auflösung auch manuell mit /size einstellen. Standardmäßig werden Entwürfe von images im Format 512×512 erstellt. Diese können etwas unscharf aussehen. Wenn Sie den Befehl size verwenden, erhalten Sie ein klareres Ergebnis.
/render /size:768x768 a gorilla jogging in the park <sdxl>
Beschränkungen: Stable Diffusion 1.5 wird auf 512×512 trainiert, eine zu große Größe führt also zu Doppelköpfen und anderen Mutationen. SDXL wird auf 1024×1024 trainiert, so dass eine Größe wie 1200×800 mit einem SDXL-Modell besser funktioniert als mit einem SD 1.5-Modell, da weniger Wiederholungen zu erwarten sind. Wenn Sie durch die Verwendung von /size doppelte Subjekte erhalten, versuchen Sie, den Prompt mit 1 Frau/Mann zu beginnen und den Hintergrund am Ende des Prompts genauer zu beschreiben. Um 2000×2000 und 4000×4000 zu erreichen, verwenden Sie Upscaling
Seed
Eine beliebige Zahl, die zur Initialisierung des Bilderzeugungsprozesses verwendet wird. Dabei handelt es sich nicht um ein bestimmtes Bild (es ist nicht wie eine Foto-ID in der Datenbank), sondern eher um eine allgemeine Markierung. Der Zweck von seed ist es, die Wiederholung einer Bildaufforderung zu erleichtern. Seed war ursprünglich der beste Weg, um dauerhafte Zeichen zu erhalten, aber das wurde durch das System Concepts ersetzt.
Um ein Bild zu wiederholen: Seed, Guidance, Sampler, Concepts und Prompt sollten gleich sein. Jede Abweichung hiervon verändert das Bild.
SYNTAX
/render /seed:123456 cats in space
Steps
Die Anzahl der Iterationen, die die KI benötigt, um das Bild zu refine , wobei mehr steps im Allgemeinen zu einer höheren Qualität führt. Natürlich führt die höhere Schrittzahl zu einer langsameren Verarbeitung.
/render /steps:25 (((cool))) cats in space, heavens
Die Einstellung steps auf 25 ist der Durchschnitt. Wenn Sie steps nicht angeben, wird der Wert standardmäßig auf 50 gesetzt, was ein hoher Wert ist. Der Bereich von steps reicht von 1 bis 100, wenn er manuell eingestellt wird, und bis zu 200 steps , wenn er mit einer Voreinstellung verwendet wird. Die Voreinstellungen sind:
waymore - 200 steps, zwei images - am besten für Qualität
mehr -100 steps, drei images
weniger - 25 steps, sechs images
weglos - 15 steps, neun images! - am besten für Entwürfe
/render /steps:waymore (((cool))) cats in space, heavens
Es mag zwar verlockend sein, /steps:waymore bei jedem render einzustellen, aber das verlangsamt nur Ihr workflow , da die Berechnungszeit länger dauert. Erhöhen Sie die steps , wenn Sie Ihren besten Prompt erstellt haben. Alternativ können Sie lernen, wie Sie LCM sampler verwenden, um die höchste Qualität images mit der geringsten Anzahl von steps zu erhalten. Zu viele steps können ein Bild auch verderben.
AUSNAHMEN
Früher wurde empfohlen, ab 35 steps oder höher zu arbeiten, um eine gute Qualität zu erzielen. Dies ist jedoch nicht mehr immer der Fall, da neuere hocheffiziente Modelle ein beeindruckendes Bild mit nur 4 steps erzeugen können!
Guidance (CFG)
Die Skala Classifier-Free Guidance ist ein Parameter, der steuert, wie genau sich die KI an die Eingabeaufforderung hält; höhere Werte bedeuten, dass sie sich mehr an die Eingabeaufforderung hält.
Wenn dieser Wert höher eingestellt ist, kann das Bild schärfer erscheinen, aber die KI hat weniger "Kreativität", um die Lücken auszufüllen, so dass Pixel und Störungen auftreten können.
Ein sicherer Standardwert ist 7 für die gängigsten Basismodelle. Es gibt jedoch spezielle Modelle mit hohem Wirkungsgrad, die eine andere guidance Skala verwenden, die im Folgenden erläutert wird.
SYNTAX
/render <sdxl> [[<fastnegative-xl:-2>]]
/guidance:7
/size:1024x1024
Takoyaki on a plate
Wie hoch oder niedrig die guidance eingestellt werden sollte, hängt von dem von Ihnen verwendeten sampler ab. Die Sampler werden weiter unten erklärt. Auch die Menge an steps , die zum "Lösen" eines Bildes zugelassen ist, kann eine wichtige Rolle spielen.
Ausnahmen von der Regel
Typische Modelle folgen diesem guidance und Stufenmuster, aber neuere Modelle mit hohem Wirkungsgrad benötigen weit weniger guidance , um auf die gleiche Weise zu funktionieren, zwischen 1,5 - 2,5. Dies wird im Folgenden erklärt:
Hocheffiziente Modelle
Niedrig Steps, Niedrig Guidance
Die meisten concepts benötigen eine guidance von 7 und 35+ steps , um ein gutes Bild zu erzeugen. Dies ändert sich mit der Einführung von Modellen mit höherem Wirkungsgrad.
Diese Modelle können images in 1/4 der Zeit erstellen und benötigen nur 4-12 steps mit niedrigeren guidance. Sie finden sie unter den Bezeichnungen Turbo, Hyper, LCM, und Lightning im concepts System zu finden und sie sind mit den klassischen Modellen kompatibel. Du kannst sie zusammen mit Loras und Inversions der gleichen Modellfamilie verwenden. Die SDXL-Familie bietet die größte Auswahl (verwenden Sie das Pulldown-Menü, ganz rechts). Juggernaut 9 Lightining ist eine beliebte Wahl.
Some of our other favorite Lightning models are <boltning-xl> and <realvis4light-xl> which look great with a guidance of 2, steps between 4-12, and Refiner (no fix) turned off. Polish it off with a good negative like [[<fastnegative-xl:-2>]]. Follow it up with an upscale, and the effects are stunning!
Schauen Sie in die Notizen dieser speziellen Modelltypen, um mehr Details über ihre Verwendung zu erfahren, wie z.B. Aetherverse-XL (unten abgebildet), mit einer guidance von 2,5 und 8 steps , wie unten abgebildet.
VASS (nur SDXL)
Vass ist ein HDR mode für SDXL, das auch die Komposition verbessern und die Farbsättigung reduzieren kann. Manche bevorzugen es, andere vielleicht nicht. Wenn das Bild zu bunt aussieht, versuchen Sie es ohne Refiner (NoFix)
Der Name stammt von Timothy Alexis Vass, einem unabhängigen Forscher, der den latenten Raum des SDXL erforscht hat und interessante Beobachtungen gemacht hat einige interessante Beobachtungen gemacht hat. Sein Ziel ist die Farbkorrektur und die Verbesserung des Inhalts von images. Wir haben seinen veröffentlichten Code angepasst, damit er in PirateDiffusion läuft.
/render a cool cat <sdxl> /vass
Warum und wann Sie es verwenden sollten: Probieren Sie es bei SDXL images aus, die zu gelb oder unscharf sind oder bei denen der Farbbereich eingeschränkt erscheint. Sie sollten eine bessere Lebendigkeit und aufgeräumte Hintergründe sehen.
Beschränkungen: Dies funktioniert nur in SDXL.
PARSER & GEWICHTE
Der Teil der Software, der Ihre Eingabeaufforderung aufnimmt, wird Parser genannt. Der Parser hat den größten Einfluss auf die Kohäsion der Eingabeaufforderung - wie gut die KI versteht, was Sie ausdrücken wollen und was sie am meisten priorisieren soll.
PirateDiffusion hat drei Parser-Modi: Standard, LPW und Gewichte (Parser "neu"). Sie haben alle ihre Stärken und Nachteile, so dass es wirklich auf Ihre Eingabeaufforderung style und Ihre Einstellung zu Syntaxt ankommt.
MODE 1 - STANDARD-PARSER (AM EINFACHSTEN)
Der Standard-Parser bietet die meiste Kompatibilität und die meisten Funktionen, kann aber nur 77 Token (logische Ideen oder Wortteile) durchlassen, bevor Stable Diffusion aufhört, die lange Eingabeaufforderung zu beachten. Um zu vermitteln, was wichtig ist, können Sie (positive) und [negative] Verstärkung hinzufügen, wie im obigen Abschnitt erläutert (siehe Positives). Dies funktioniert mit SD 1.5 und SDXL.
Lange Prompt-Gewichte (experimentell)
Sie können längere positive und negative Aufforderungen schreiben, wenn die Funktion aktiviert ist. Sehen Sie sich ein Demo-Video an.
Beispiel:
((high quality, masterpiece, masterwork)) A wizard browsing through a magical marketplace with a mystical air around him. He has pointy ears, spectacles perched precariously on his nose, and a wand twirling in hsi hand. His robes are adorned with intricate patterns and patterns of magic dust. There is a bubbling magical cauldron, and mythical creatures peeking around from behind him.
Dies ist ein Dienstprogramm zur Neugewichtung von Prompts, das es ermöglicht, dass das Prompt-Verständnis viel weiter geht als 77 Token, was das Prompt-Verständnis insgesamt verbessert. Natürlich würden wir dies als Norm festlegen, wenn es nicht einige unglückliche Kompromisse gäbe:
Beschränkungen
Für beste Ergebnisse ist eine niedrigere guidance erforderlich, etwa 7 oder weniger.
LPW sollte nicht mit sehr starkem positiven oder negativen Prompting kombiniert werden
(((((Dies wird brechen)))))
[[[[so wird dies]]]]
Funktioniert nicht gut mit Loras oder Inversion concepts
/render /lpw my spoon is too big, ((((big spoon)))) [small spoon], super big, massively big, you would not believe the size, and I've seen many spoons and let me tell you, this spoon in my hand, right here, is yuuuuge, the biggest spoon you'll ever see, and if anyone's said they've seen a bigger spoon, they're cheating, Big spoon, gigantic ladle, extra large serving bowl, oversized utensil, huge portion size, bulky kitchenware, impressive cooking tools, rustic table setting, hearty meals, heavyweight handle, strong grip, stylish design, handcrafted wooden piece, <coma2>
WORTGEWICHT
PARSER "NEU" ALIAS PROMPT-GEWICHTE
Eine weitere Strategie für einen besseren Zusammenhalt der Aufforderung besteht darin, jedem Wort eine "Gewichtung" zu geben. Die Gewichtung liegt zwischen 0 und 2, wobei Dezimalzahlen verwendet werden, ähnlich wie bei LoRas. Die Syntax ist ein wenig kompliziert, aber sowohl positive als auch negative Gewichte werden unterstützt, um eine unglaubliche Präzision zu erreichen
Achten Sie besonders auf die Verneinungen, bei denen ein Kombinationspaar [( )] verwendet wird, um die Verneinung auszudrücken. Im obigen Beispiel sind blaue Katze und roter Hund die Verneinungen. Dieses Merkmal kann nicht mit /lpw (oben) gemischt werden.
CLIP SKIP
Diese Funktion ist umstritten, da sie sehr subjektiv ist und die Auswirkungen von Modell zu Modell stark variieren.
KI-Modelle bestehen aus mehreren Schichten, und in den ersten Schichten wird gesagt, dass sie zu viele allgemeine Informationen enthalten (manche würden sagen: Schrott), was zu langweiligen oder sich wiederholenden Kompositionen führt.
Die Idee hinter Clip Skip ist es, das Rauschen, das in diesen Schichten entsteht, zu ignorieren und direkt auf das Wesentliche einzugehen.
Theoretisch wird dadurch der Zusammenhalt gestärkt und die Absicht gefördert. In der Praxis kann das Beschneiden zu vieler Ebenen jedoch zu einem schlechten Bild führen. Eine beliebte "sichere" Einstellung ist clipskip 2, wobei die Entscheidung darüber noch aussteht.
Refiner (nur SDXL)
Der Refiner ist eine Technik zum Entfernen und Glätten von Rauschen, die für Gemälde und Illustrationen empfohlen wird. Es schafft glattere images mit saubereren Farben. Manchmal ist es aber auch das Gegenteil von dem, was Sie wollen. Bei realistischen Bildern images führt das Ausschalten des Verfeinerers zu mehr Farbe und Details, wie unten gezeigt. Sie können das Bild dann hochskalieren, um das Rauschen zu reduzieren und die Auflösung zu erhöhen.
SYNTAX
/render a cool cat <sdxl> /nofix
Warum und wann man es verwenden sollte: Wenn das Bild zu verwaschen aussieht oder die Hautfarben stumpf wirken. Fügen Sie eine Nachbearbeitung mit einem der Antwortbefehle (unten) wie /highdef oder /facelift hinzu, um das Bild zu veredeln.
Probenehmer
Ein sampler (auch Scheduler genannt) ist ein Algorithmus, der festlegt, wie die KI Ihre Frage mit den gegebenen Parametern lösen soll. Die "beste" sampler ist höchst subjektiv. Mehr Infos und Vergleich images
Eine Ausnahme bildet der LCM sampler , der speziell für das Rendering in niedrigen guidance und niedrigen steps verwendet wird.
SAMPLER BEFEHLE UND SYNTAX
Um eine Liste der verfügbaren Sampler anzuzeigen, geben Sie einfach ein /samplers
Sampler sind bei KI-Enthusiasten ein beliebtes Tweaking-Feature, und hier ist, was sie tun. Sie werden auch als "Rauschplaner" bezeichnet. Die Menge an steps und die von Ihnen gewählte sampler können einen großen Einfluss auf ein Bild haben. Selbst mit einem niedrigen steps können Sie mit einem sampler wie DPM 2++ mit dem optionalen mode "Karras" ein hervorragendes Bild erzielen. Siehe Sampler-Seite für Vergleiche.
Um sie zu verwenden, fügen Sie Folgendes zu Ihrer Eingabeaufforderung hinzu
/render /sampler:dpm2m /karras a beautiful woman <sdxl>
Karras ist ein optionales mode , das mit 4 Samplern funktioniert. Unsere Tests haben gezeigt, dass dies zu angenehmeren Ergebnissen führen kann.
LCM in Stable Diffusion steht für Latent Consistency Models. Verwenden Sie es, um images schneller zurückzubekommen, indem Sie es mit niedrigeren steps und guidance stapeln. Der Kompromiss besteht darin, dass die Geschwindigkeit über der Qualität steht, obwohl es in großen Stapeln sehr schnell beeindruckende images erzeugen kann.
/render /sampler:lcm /guidance:1.5 /steps:6 /images:9 /size:1024x1024 <realvis2-xl> /seed:469498 /nofix Oil painting, oil on board, painted picture Retro fantasy art by Brom by Gerald Brom ((high quality, masterpiece,masterwork)) [[low resolution,m worst quality, blurry, mediocre, bad art, deformed, disfigured, elongated, disproportionate, anatomically incorrect, unrealistic proportions, melted, abstract, surrealism, sloppy, crooked, skull, skulls]] Closeup Portrait A wizard stands in an alien landscape desert wearing wizards robes and a magic hat
Tipps: Wenn Sie SDXL verwenden, fügen Sie /nofix hinzu, um den Refiner zu deaktivieren; dies kann die Qualität verbessern, besonders wenn Sie /more
Sie funktioniert mit den Modellen SD 1.5 und SDXL. Probieren Sie es mit guidance zwischen 2-4 und steps zwischen 8-12. Bitte experimentieren Sie und teilen Sie Ihre Ergebnisse in der VIP Prompt-Engineering-Diskussionsgruppe, die Sie in Ihrem Mitgliedsbereich auf Patreon finden.
Es variiert je nach Modell, aber selbst /guidance:1.5 /steps:6 /images:9 liefert gute SDXL-Ergebnisse in weniger als 10 Sekunden!
Im obigen Beispiel verwendet der Ersteller die spezielle LCM sampler , die sehr niedrige guidance und niedrige steps ermöglicht, aber dennoch eine sehr hohe Qualität images erzeugt. Vergleichen Sie diese Eingabeaufforderung mit etwas wie /sampler:dpm2m /karras /guidance:7 /steps:35 Der Befehl VAE steuert die Farben, und /nofix schaltet den SDXL-Verfeinerer aus. Diese Befehle funktionieren gut mit LCM.
VAE OVERRIDE
VAE steht für Variational AutoEncoder, ein Teil der Software, der einen großen Einfluss darauf hat, wie farbig das Bild ist. Für SDXL gibt es zur Zeit nur eine fantastische VAE .
VAE ist eine spezielle Art von Modell, mit dem Kontrast, Qualität und Farbsättigung verändert werden können. Wenn ein Bild übermäßig neblig aussieht und Ihr guidance auf über 10 eingestellt ist, könnte VAE der Schuldige sein. VAE steht für "variational autoencoder" und ist eine Technik, die images neu klassifiziert, ähnlich wie eine Zip-Datei ein Bild komprimieren und wiederherstellen kann. Die VAE "rehydriert" das Bild auf der Grundlage der Daten, denen es ausgesetzt war, und nicht auf der Grundlage diskreter Werte. Wenn alle Ihre Renderings images entsättigt, unscharf oder mit violetten Flecken erscheinen, ist ein Wechsel von VAE die beste Lösung. (Bitte benachrichtigen Sie uns auch, damit wir den richtigen Standardwert einstellen können). 16 Bit VAE laufen am schnellsten.
Syntax
/render #sdxlreal a hamster singing in the subway /vae:GraydientPlatformAPI__bright-vae-xl
Verfügbare voreingestellte Optionen VAE :
/vae:GraydientPlatformAPI__bright-vae-xl
/vae:GraydientPlatformAPI__sd-vae-ft-ema
/vae:GraydientPlatformAPI__vae-klf8anime2
/vae:GraydientPlatformAPI__vae-blessed2
/vae:GraydientPlatformAPI__vae-anything45
/vae:GraydientPlatformAPI__vae-orange
/vae:GraydientPlatformAPI__vae-pastel
Dritte VAE:
Hochladen oder auf der Huggingface-Website mit diesem Ordnerverzeichnis finden:
Ersetzen Sie dann die Schrägstriche und entfernen Sie den vorderen Teil der URL, etwa so:
/render was auch immer /vae:madebyollin__sdxl-vae-fp16-fix
Der Ordner vae muss die folgenden Merkmale aufweisen:
Ein einziger VAE pro Ordner, in einem Ordner der obersten Ebene eines Huggingface-Profils wie oben gezeigt
Der Ordner muss eine config.json enthalten
Die Datei muss im .bin-Format vorliegen
Die bin-Datei muss "diffusion_pytorch_model.bin" heißen.
Wo finde ich weitere? Huggingface und Civitai haben vielleicht andere, aber sie müssen in das obige Format konvertiert werden
Für SD15 haben wir viele Optionen auf Lager. Hier ist die unwissenschaftliche Meinung einer Person, was die Unterschiede sind:
kofi2 - sehr bunt und gesättigt
blessed2 - weniger gesättigt als kofi2
anything45 - weniger gesättigt als blessed2
Orange - mittlere Sättigung, kräftige Grüntöne
Pastell - lebhafte Farben, wie bei alten holländischen Meistern
ft-mse-840000-ema-pruned - ideal für Realismus
Fehlersuche: Einige VAE sind mit einigen Basismodellen nicht kompatibel. Dies führt zu zwei Fehlern: Neongrüne Lichtlecks (oder) ein schwarzes Quadrat, versuchen Sie also eine andere VAE , wenn das Bild, wenn das passiert.
Projekte
Sie könnenimages direkt in Projektordner in Unified WebUI und PirateDiffusion Telegram render .
Telegramm und API-Methode:
/render my cool prompt /project:xyz
Web-Methode:
Zuerst render ein Bild, um Ihr Projekt in Ihrem @piratediffusion_bot zu starten
Fahren Sie am Ende dieses Leitfadens mit den Befehlen zu /project fort
ControlNet über PirateDiffusion
ControlNets sind Bild-zu-Bild-Schablonen für die Steuerung des endgültigen Bildes. Ob Sie es glauben oder nicht, Sie können Controlnet nativ in Telegram ohne den Browser verwenden, obwohl wir beides unterstützen.
Sie können ein Ausgangsbild als Schablone bereitstellen, eine mode wählen und das Aussehen des Ausgangsbildes mit einer positiven und negativen Aufforderung ändern. Sie können control den Effekt mit dem Schieberegler für die Gewichtung einstellen. Eingaben images zwischen 768×768 oder 1400×1400 funktionieren am besten.
Zurzeit werden die Modi Konturen, Tiefe, Kanten, Hände, Pose, Referenz, Segment, Skelett und facepush unterstützt, die jeweils untergeordnete Parameter haben. Mehr Beispiele
Anzeigen der unter controlnet gespeicherten Voreinstellungen
/control
Erstellen Sie eine Voreinstellung ControlNet
Laden Sie zunächst ein Bild hoch. Dann "antworten" Sie auf dieses Bild mit diesem Befehl und geben ihm einen Namen wie "myfavoriteguy2".
/control /new:myfavoriteguy2
Controlnets sind auflösungsempfindlich, d. h. sie antworten mit der Bildauflösung als Teil des Namens. Wenn ich also ein Foto von Will Smith hochlade, antwortet der Bot will-smith-1000×1000 oder wie groß mein Bild auch immer war. Dies ist nützlich, damit Sie sich später daran erinnern können, welche Größe Sie anstreben.
Aufrufen einer ControlNet Voreinstellung
Wenn Sie vergessen haben, was Ihre Voreinstellung bewirkt, verwenden Sie den Befehl show, um sie anzuzeigen: /control oder um eine bestimmte Voreinstellung zu sehen:
/control /show:myfavoriteguy2
Verwendung von ControlNet Modi
Der (neue) Shorthand-Parameter für control guidance ist /cg:0.1-2 - er steuert, wie stark sich render an eine bestimmte controlnet mode halten soll. Ein guter Wert ist 0,1-0,5. Sie können ihn auch auf die alte Weise ausschreiben: /controlguidance:1
Gesichter tauschen
FaceSwapping ist auch als Antwortbefehl verfügbar. Sie können auch diesen praktischen FaceSwap (roop, insightface) verwenden, um die Gesichter eines hochgeladenen Bildes auszutauschen. Erstellen Sie zunächst die control für das Bild und fügen Sie dann ein zweites Bild hinzu, um das Gesicht zu tauschen
Als Antwortbefehl (Rechtsklick auf ein fertiges Bild, von einem beliebigen Modell)
/faceswap myfavoriteguy2
facelift unterstützt auch einen /strength Parameter, aber die Funktionsweise ist nicht so, wie Sie es erwarten:
/faceswap /strength:0.5 myfavoriteguy2
Wenn Sie /strength auf einen Wert kleiner als 1 setzen, wird *blend* das "Vorher-Bild" mit dem "Nachher-Bild" - buchstäblich blend sie, wie in Photoshop mit 50% Deckkraft (wenn Stärke war 0,5). Der Grund dafür ist, dass der zugrundeliegende Algorithmus keine "Stärke"-Einstellung hat, wie man es erwarten würde, also war dies unsere einzige Option.
Gesichter schieben
Faceswapping (oben erklärt), aber als render-time-Befehl wird "Face Pushing" genannt
Sie können auch unsere FaceSwap-Technologie verwenden (ähnlich wie LoRa), aber es ist nur ein zeitsparender Weg, um ein Gesicht zu tauschen. Es hat keine Gewichte oder viel Flexibilität, es findet jedes realistische Gesicht in einem neuen render und tauscht die images mit einem Gesicht. Verwenden Sie dieselben ControlNet Voreinstellungsnamen, um es zu benutzen.
/render a man eating a sandwich /facepush:myfavoriteguy2
Facepush Beschränkungen
Facepush funktioniert nur mit Stable Diffusion 1.5 Modellen und der Kontrollpunkt muss realistisch sein. Sie funktioniert nicht mit SDXL-Modellen und möglicherweise nicht mit dem Befehl /more oder einigen hohen Auflösungen. Diese Funktion ist experimentell. Wenn Sie Probleme mit /facepush haben, versuchen Sie, Ihre Eingabeaufforderung zu rendern und dann /faceswap auf das Bild anzuwenden. Es wird Ihnen sagen, ob das Bild nicht realistisch genug ist. Dies kann manchmal durch die Anwendung von /facelift behoben werden, um das Ziel zu schärfen. /more und /remix funktionieren möglicherweise (noch) nicht wie erwartet.
Aufpreispflichtige Werkzeuge (verschiedene)
Mehr Pixel und Details
Vergrößern Sie die Details eines Bildes um das Vierfache und entfernen Sie Linien und Flecken aus Fotos, ähnlich wie bei der "Schönheit" mode auf Smartphone-Kameras. Modi für realistische Fotos und Kunstwerke. mehr Infos
HIGH DEF
Der Befehl HighDef (auch bekannt als High Res Fix) ist ein schneller Pixelverdoppler. Antworten Sie einfach auf das Bild, um es zu vergrößern.
/highdef
Der Befehl highdef hat keine Parameter, weil der Befehl /more alles kann, was HighDef kann und noch mehr. Dies ist nur zu Ihrer Bequemlichkeit hier. Für Profis, die mehr control wollen, scrollen Sie zurück nach oben und schauen Sie sich das /more Tutorial-Video an.
Nachdem Sie den Befehl /highdef oder /more verwendet haben, können Sie es noch einmal wie unten beschrieben hochskalieren.
UPSCALERS
Facelift ist für realistische Porträtaufnahmen gedacht.
Sie können /strength zwischen 0,1 und 1 verwenden, um den Effekt zu control . Der Standardwert ist 1, wenn nicht angegeben.
/facelift
Mit dem Befehl /facelift haben Sie auch Zugriff auf unsere Bibliothek von Upscalern. Fügen Sie diese Parameter hinzu, um den Effekt control :
Facelift ist ein Phase-2-Upscaler. Sie sollten zuerst HighDef verwenden, bevor Sie Facelift benutzen. Dies ist der allgemeine Upscaling-Befehl, der zwei Dinge tut: Er erhöht die Gesichtsdetails und vervierfacht die Pixel. Er funktioniert ähnlich wie der Beauty-Befehl mode auf Ihrem Smartphone, was bedeutet, dass er manchmal Gesichter, insbesondere Illustrationen, sandstrahlen kann. Zum Glück gibt es noch andere Betriebsmodi:
/facelift /photo
Dies schaltet die Gesichtsretusche aus und eignet sich gut für Landschaften oder natürlich wirkende Porträts.
/facelift /anime
Trotz des Namens ist es nicht nur für anime geeignet - verwenden Sie es, um alle Illustrationen zu verbessern
/facelift /size:2000x2000
Einschränkungen: Facelift wird versuchen, Ihr Bild zu vervierfachen, bis zu 4000×4000. Telegram erlaubt normalerweise nicht diese Größe, und wenn Ihr Bild bereits HD ist, wird der Versuch, es zu vervierfachen, wahrscheinlich den Speicher sprengen. Wenn das Bild zu groß ist und nicht zurückkommt, versuchen Sie, es durch Eingabe von /history aus der Web-UI zu holen, da Telegram Dateigrößenbeschränkungen hat. Alternativ können Sie den Größenparameter wie oben gezeigt verwenden, um beim Hochskalieren weniger Speicherplatz zu verwenden.
REFINE
Refine ist für die Fälle gedacht, in denen du deinen Text außerhalb von Telegram und in deinem Webbrowser bearbeiten möchtest. Eine Sache der Lebensqualität.
Ihr Abonnement enthält sowohl Telegram als auch Stable2go WebUI. Mit dem Befehl refine können Sie zwischen Telegram und der Weboberfläche wechseln. Dies ist praktisch, um schnelle Textänderungen in Ihrem Webbrowser vorzunehmen, anstatt Kopieren/Einfügen zu verwenden.
/refine
Die Website WebUI wird standardmäßig unter Brew mode gestartet. Klicken Sie auf "Erweitert", um zu Render zu wechseln.
Remix Werkzeug
Bild-zu-Bild-Transformationen
Das Werkzeug remix ist magisch. Ein hochgeladenes oder gerendertes Bild kann mit dem Remix Werkzeug in die Kunst style eines concept umgewandelt werden. Sie können auch Eingangsfotos als Referenzbilder verwenden, um dramatisch unterschiedliche Themen zu verändern.
SYNTAX
Remix ist der Befehl zur Bild-zu-Bild-Übertragung style , auch bekannt als der Befehl zur erneuten Eingabeaufforderung.
Remix benötigt ein Bild als Eingabe und zerstört jedes Pixel des Bildes, um ein völlig neues Bild zu erstellen. Er ähnelt dem Befehl /more , aber Sie können ihm einen anderen Modellnamen und eine Eingabeaufforderung zum Ändern der Art style des Bildes übergeben.
Remix ist der zweitbeliebteste "Antwort"-Befehl. Antworten Sie wortwörtlich auf ein Foto, als ob Sie mit ihm sprechen würden, und geben Sie dann den Befehl ein. In diesem Beispiel wird das Basismodell mit der Bezeichnung "Level 4" auf style umgestellt, von dem aus Sie gestartet sind.
/remix a portrait <level4>
Sie können Ihre hochgeladenen Fotos mit /remix verwenden, und sie werden vollständig verändert. Um Pixel zu erhalten (z. B. um das Gesicht nicht zu verändern), sollten Sie stattdessen eine Maske mit Inpaint zeichnen.
Verwendungszwecke: Style Transfer und Kreatives "gehobenes Niveau"
Mit dem Tool remix können Sie auch niedrig aufgelöste Fotos images neu interpretieren, z. B. Fotos von Videospielen mit niedriger Auflösung in ein modernes, realistisches images verwandeln oder sich selbst in eine Karikatur oder anime Illustration verwandeln. Dieses Video zeigt Ihnen wie:
Mehr Werkzeug (Antwortbefehl)
Das Werkzeug "Mehr" erzeugt Variationen desselben Bildes
Um dasselbe Motiv in leicht abgewandelter Form zu sehen, verwenden Sie das Werkzeug "Mehr".
Was unter der Haube passiert: Der Wert von seed wird erhöht und die guidance wird randomisiert, wobei die ursprüngliche Eingabeaufforderung beibehalten wird. Beschränkungen: Bei der Verwendung effizienter Modelle kann es guidance übertreiben.
Um weitere Befehle zu verwenden, klicken Sie mit der rechten Maustaste auf ein Bild, als ob Sie mit einer Person sprechen würden. Antwortbefehle werden verwendet, um images zu bearbeiten und Informationen zu prüfen, z. B. IMG2IMG oder die ursprüngliche Eingabeaufforderung nachzuschlagen.
MEHR SYNTAX
more ist der häufigste Antwortbefehl. Er gibt Ihnen eine ähnliche images zurück, wenn Sie auf ein Bild antworten, das bereits durch eine Eingabeaufforderung erzeugt wurde. Der Befehl /more funktioniert nicht bei einem hochgeladenen Bild.
/more
Der Befehl more ist mächtiger, als es scheint. Er akzeptiert auch Stärke, Guidance und Größe, so dass Sie ihn auch als Upscaler für die zweite Phase verwenden können, was besonders für Stable Diffusion 1.5 Modelle nützlich ist. Sehen Sie sich dieses Video-Tutorial an, um ihn zu beherrschen.
Werkzeug zum Übermalen
AKA Generative Füllung
Beim Übermalen handelt es sich um ein Maskierungswerkzeug, mit dem Sie eine Maske um einen Bereich ziehen und etwas Neues in diesen Bereich einfügen oder das Objekt wie mit einem Radiergummi entfernen können. Das Werkzeug inpaint hat ein eigenes positives und negatives Eingabefeld, das auch Auslösecodes akzeptiert für concepts.
Hinweis: Unsere Software wurde seit diesem Video aktualisiert, aber die gleichen Grundsätze gelten immer noch.
GENERATIVE FÜLLUNG, AUCH BEKANNT ALS INPAINTING
Inpaint ist ein nützliches Werkzeug, um einen bestimmten Bereich auf einem Foto zu ändern. Im Gegensatz zu After Detailer können Sie mit dem Werkzeug inpaint den Bereich, den Sie ändern möchten, auswählen und maskieren.
Dieses Tool verfügt über eine grafische Benutzeroberfläche - es ist in Stable2go integriert. Inpaint öffnet einen Webbrowser, in dem Sie buchstäblich auf das Bild malen und einen maskierten Bereich erstellen, der mit einer Aufforderung versehen werden kann. Das Übermalen ist sowohl bei hochgeladenen Nicht-KI-Fotos (Hände, Himmel, Haarschnitt, Kleidung usw. ändern) als auch bei KI-Fotos images möglich.
/inpaint Glühwürmchen, die nachts herumschwirren
In der grafischen Benutzeroberfläche gibt es spezielle, spezifische Kunststile (inpaint models), die in der Auswahlliste dieses Werkzeugs verfügbar sind, also vergessen Sie nicht, einen auszuwählen. . Verwenden Sie Stärke und guidance für control , wobei sich Stärke nur auf Ihre inpaint Eingabeaufforderung bezieht.
/inpaint /size:512x768 /strength:1 /guidance:7 fireflies at (night)
Tipp: Die Größe wird vom Originalbild übernommen, empfohlen wird 512×768. Es wird empfohlen, eine Größe anzugeben, da sonst standardmäßig 512×512 verwendet wird, was Ihr Bild möglicherweise zerdrückt. Wenn eine Person auf dem Bild weit entfernt ist, kann sich ihr Gesicht verändern, es sei denn, das Bild hat eine höhere Auflösung.
Sie können inpaint auch umkehren, indem Sie z. B. zuerst den Befehl /bg verwenden, um automatisch den Hintergrund aus einem Bild zu entfernen, und dann auffordern, den Hintergrund zu ändern. Dazu kopieren Sie die Masken-ID aus den Ergebnissen von /bg . Verwenden Sie dann die Eigenschaft /maskinvert
/inpaint /mask :IAKdybW /maskinvert einen majestätischen Blick auf den Nachthimmel mit vorbeiziehenden Planeten und Kometen
OUTPAINT AKA LEINWAND ZOOM UND PANNING
NEUESTE VERSION (FLUX)
Erweitern Sie ein beliebiges Bild nach denselben Regeln wie inpaint, aber ohne grafische Benutzeroberfläche, d. h. wir müssen ein Auslösewort für die zu verwendende Art von Kunst style angeben. Sie können die Richtung mit einem Slot-Wert angeben
/workflow /run:zoomout-flux fireflies at night
DIRECTIONAL CONTROL
Sie können Auffüllungen hinzufügen, indem Sie die Slot-Werte entgegen dem Uhrzeigersinn verwenden. Also Schlitz1 = TOP
/workflow /run:zoomout-flux fireflies at night /slot1:200 /slot2:50 /slot3:100 /slot4:300
ÄLTERE VERSIONEN (SDXL)
Erweitern Sie ein beliebiges Bild nach denselben Regeln wie inpaint, aber ohne grafische Benutzeroberfläche, so dass wir ein Auslösewort für die zu verwendende Art von Kunst style angeben müssen. Für das Ausmalen werden genau dieselben inpaint Modelle verwendet. Lernen Sie die Namen kennen, indem Sie die Seite Modelle durchblättern oder indem Sie
Sie können überprüfen, welche Modelle verfügbar sind mit /concept /inpainting
/outpaint fireflies at night <sdxl-inpainting>
Outpaint hat zusätzliche Parameter. Verwenden Sie oben, rechts, unten und links, um control die Richtung anzugeben, in die sich die Leinwand ausdehnen soll. Wenn Sie "Seite" weglassen, wird das Bild gleichmäßig in alle vier Richtungen ausgedehnt. Sie können auch das Bokeh des Hintergrunds blur (1-100), den Faktor zoom (1-12) und die Verkleinerung des ursprünglichen Bereichs (0-256) hinzufügen. Fügen Sie Stärke hinzu, um es zu bändigen.
/outpaint /side:top /blur:10 /zoom:6 /contract:50 /strength:1 the moon is exploding, fireworks <sdxl-inpainting>
Optionale Parameter
/side:bottom/top/left/right - Sie können eine Richtung angeben, um Ihr Bild zu erweitern oder in alle vier Richtungen auf einmal gehen, wenn Sie diesen Befehl nicht hinzufügen.
/blur:1-100 - verwischt die Kante zwischen dem ursprünglichen und dem neu hinzugefügten Bereich.
/zoom:1-12 - beeinflusst den Maßstab des gesamten Bildes, standardmäßig ist er auf 4 eingestellt.
/contract:0-256 - Verkleinert die ursprüngliche Fläche im Vergleich zur übermalten Fläche. Standardmäßig ist der Wert auf 64 eingestellt.
TIPP: Bessere Ergebnisse erzielen Sie, wenn Sie die Eingabeaufforderungen bei jeder Verwendung von outpaint ändern und nur die Dinge einbeziehen, die Sie in dem neu erweiterten Bereich sehen möchten. Das Kopieren der ursprünglichen Eingabeaufforderungen funktioniert nicht immer wie gewünscht.
BG-Werkzeug entfernen
Blitzschnelles Zappen im Hintergrund
Das Werkzeug zum Entfernen des Hintergrunds ist eine einfache, einstufige Lösung, um alles hinter dem Motiv zu eliminieren. Images bei oder um 800×800 funktioniert am besten. Sie können auch das Untermalungswerkzeug (oben) verwenden, um einen neuen Hintergrund zu maskieren und zu platzieren.
BEFEHLE ZUM ENTFERNEN IM HINTERGRUND
Um einen realistischen Hintergrund zu entfernen, antworten Sie ihm einfach mit /bg
/bg
Fügen Sie bei Illustrationen jeglicher Art diesen Parameter anime hinzu, und die Entfernung wird schärfer
/bg /anime
Sie können auch den Parameter PNG hinzufügen, um download ein unkomprimiertes Bild zu übergeben. Es wird standardmäßig ein hochauflösendes JPG zurückgegeben.
/bg /format:png
Sie können auch einen Hex-Farbwert verwenden, um die Farbe des Hintergrunds anzugeben
/bg /anime /format:png /color:FF4433
Sie können die Maske auch separat download
/bg /Masken
Tipp: Was kann ich mit der Maske machen? Nur den Hintergrund auffordern! Das kann man aber nicht in einem Schritt machen. Reagieren Sie zunächst auf die Maske mit /showprompt , um den Bildcode für die Übermalung zu erhalten, oder wählen Sie ihn aus den aktuellen Übermalungsmasken aus. Fügen Sie /maskinvert für den Hintergrund statt für den Vordergrund hinzu, wenn Sie eine render erstellen.
Laden Sie einen Hintergrund hoch oder render einen
Antworten Sie auf das Hintergrundfoto mit /control /new :Schlafzimmer (oder welcher Raum/Bereich auch immer)
Hochladen oder render des Zielbildes, des zweiten Bildes, das den gespeicherten Hintergrund erhalten soll
Antworten Sie auf das Ziel mit /bg /replace:Bedroom /blur:10
Der Parameter blur liegt zwischen 0 und 255 und steuert die Übergänge zwischen dem Motiv und dem Hintergrund. Das Ersetzen des Hintergrunds funktioniert am besten, wenn das gesamte Motiv zu sehen ist, d. h. wenn Teile des Körpers oder des Objekts nicht durch ein anderes Objekt verdeckt werden. Dadurch wird verhindert, dass das Bild schwebt oder einen unrealistischen Hintergrundumbruch erzeugt.
EIN OBJEKT SPINNEN
Sie können jedes Bild drehen, als ob es ein 3D-Objekt wäre. Es funktioniert viel besser, wenn Sie zuerst den Hintergrund mit /bg
/spin
Spin funktioniert am besten, nachdem der Hintergrund entfernt wurde. Der Spin-Befehl unterstützt /guidance. Unser System wählt zufällig eine guidance 2 - 10. Für mehr Details, fügen Sie auch /steps:100
EIN FOTO BESCHREIBEN
Aktualisiert! Es gibt jetzt zwei Arten der Beschreibung: CLIP und FLORENCE2
Erzeugen Sie eine Eingabeaufforderung aus einem beliebigen Bild mit Computer Vision mit Describe! Es ist ein "Antwort"-Befehl, also klicken Sie mit der rechten Maustaste auf das Bild, als ob Sie mit ihm sprechen wollten, und schreiben Sie
/describe /florence
Mit dem zusätzlichen Parameter Florence erhalten Sie eine wesentlich detailliertere Eingabeaufforderung. Er verwendet das neue Florence2-Computersichtmodell. /describe selbst verwendet das CLIP-Modell
Beispiel
Widgets starten innerhalb PirateDiffusion
Sie können voreingestellte Schaltflächen für die einfache Erstellung von Drucktasten erstellen, ohne Code lernen zu müssen. Dies wird durch unser Widgets-System ermöglicht. Füllen Sie einfach eine Tabelle mit den Vorlagen für Ihre Eingabeaufforderungen aus und verbinden Sie sie mit Ihrem Bot. Wir bieten zum Beispiel eine Vorlage für einen Charakter, der widget macht:
Widgets erstellen gleichzeitig ein Telegramm und WebUI , so dass Sie beides genießen können! Sehen Sie ein Video über Widgets und download die Vorlage um mit der Erstellung zu beginnen. Keine Codierung erforderlich!
Datei- und Warteschlangenverwaltung
CANCEL
Verwenden Sie /cancel , um das Rendering abzubrechen.
/cancel
DOWNLOAD
Die images , die Sie in Telegram sehen, verwenden den in Telegram integrierten Bildkompressor. Dadurch wird die Dateigröße begrenzt. Um Telegram zu umgehen, antworten Sie auf Ihr Bild mit /download , um ein unkomprimiertes RAW-Bild zu erhalten
/download
Wenn download eine password anfordert, lesen Sie den Abschnitt Private Galeriefreigabe und Passwörter in diesem Spickzettel.
DELETE
Es gibt zwei Möglichkeiten, images zu löschen: lokal von Ihrem Gerät oder für immer von Ihrem Cloud Drive.
Um images von Ihrem lokalen Gerät zu löschen, sie aber auf dem Cloud Drive zu behalten, verwenden Sie die in Telegram integrierte Löschfunktion. Drücken Sie lange auf ein Bild (oder klicken Sie mit der rechten Maustaste auf das Bild am PC) und wählen Sie "Löschen".
Antworten Sie auf ein Bild mit /delete , um es von Ihrem Cloud-Laufwerk zu löschen.
/delete
Sie können auch /webui eingeben und unseren Dateimanager starten und den Befehl organize verwenden, um images auf einmal zu löschen.
GESCHICHTE
Zeigt eine Liste Ihrer kürzlich erstellten images innerhalb des jeweiligen Telegram-Kanals an. Bei der Verwendung in öffentlichen Gruppen wird nur images angezeigt, die Sie bereits in diesem öffentlichen Kanal erstellt haben, so dass /history auch auf Ihre Privatsphäre achtet.
/history
SHOWPROMPT & VERGLEICHEN
Um die Eingabeaufforderung für ein Bild zu sehen, klicken Sie mit der rechten Maustaste darauf und geben Sie /showprompt
/showprompt
Mit diesem praktischen Befehl können Sie überprüfen, wie ein Bild erstellt wurde. Er zeigt Ihnen die letzte Aktion an, die an dem Bild vorgenommen wurde. Um den gesamten Verlauf zu sehen, geben Sie den Befehl wie folgt ein: /showprompt /history
In der Ausgabe von showprompt ist ein Bildvergleichstool integriert. Klicken Sie auf diesen Link und das Tool wird im Browser geöffnet.
BESCHREIBEN (CLIP)
Mit dem Befehl /showprompt erhalten Sie die genaue Eingabeaufforderung eines AI-Bildes, aber was ist mit Nicht-AI images?
Unser Befehl /describe verwendet Computer-Vision-Techniken, um eine Eingabeaufforderung zu einem von Ihnen hochgeladenen Foto zu schreiben.
/describe
Die Sprache, die /describe verwendet, kann manchmal seltsam sein. Zum Beispiel bedeutet "arafed" eine lustige oder lebhafte Person.
PNG
Standardmäßig erstellt PirateDiffusion images im nahezu verlustfreien JPG-Format. Sie können images auch als PNG-Dateien mit höherer Auflösung anstelle von JPG-Dateien erstellen. Achtung! Dadurch wird das 5-10fache an Speicherplatz verbraucht. Allerdings gibt es einen Haken. Telegram zeigt PNG-Dateien nicht nativ an. Nachdem das PNG erstellt wurde, müssen Sie den Befehl /download (oben) verwenden, um es zu sehen.
/render a cool cat #everythingbad /format:png
VECTOR
IMAGE TO SVG / VECTOR! Antworten Sie auf ein generiertes oder hochgeladenes Bild, um es als Vektoren, insbesondere SVG, zu trace . Vektoren images können stufenlos gezoomt werden, da sie nicht mit gerasterten Pixeln gerendert werden wie reguläre images; Sie haben also klare scharfe Kanten. Hervorragend geeignet für den Druck, Produkte usw. Verwenden Sie den Befehl /bg , wenn Sie ein Logo oder einen Aufkleber erstellen wollen.
/trace
Alle verfügbaren Optionen sind unten aufgeführt. Wir kennen die optionalen Optionen noch nicht. Helfen Sie uns, einen guten Standard zu finden, indem Sie Ihre Erkenntnisse im VIP-Chat mitteilen.
speckle - ganze Zahl - Standardwert 4 - Bereich 1 ... 128 - verwirft Flecken, die kleiner als X px sind
Farbe - Standard - Bildfarbe festlegen
bw - Bild schwarz/weiß machen
mode - Polygon, Spline, oder keine - Standard-Spline - Curver-Anpassung mode
precision - Ganzzahlige Zahl - Standardwert 6 - Bereich 1 ... 8 - Anzahl der signifikanten Bits, die in einem RGB-Kanal verwendet werden - d. h. mehr Farbtreue auf Kosten von mehr "Flecken"
gradient - Ganzzahlige Zahl - Standardwert 16 - Bereich 1 ..128 - Farbunterschied zwischen gradient Ebenen
corner - ganze Zahl - Standardwert 60 - Bereich 1 ... 180 - Minimaler Momentanwinkel (Grad), der als ein corner
length - Fließkommazahl - Standardwert 4 - Bereich 3,5 ... 10 - Iterative Unterteilung durchführen, bis alle Segmente kürzer als dieser Wert sind length
Beispiel trace mit optionalen Feinabstimmungsparametern:
/trace /color /gradient:32 /corner:1
WEB-UI-DATEIMANAGER
Praktisch, um Ihre Dateien in einem Browser zu verwalten und schnell eine visuelle Liste der Modelle zu sehen.
/webui
Im Abschnitt "Konten" oben auf dieser Seite finden Sie Informationen zu Befehlen wie password .
RENDER PROGRESS MONITOR
Es ist unvermeidlich, dass Telegram von Zeit zu Zeit Verbindungsprobleme hat. Wenn Sie wissen möchten, ob unsere Server die images erstellen, diese aber nicht zu Telegram gelangen, verwenden Sie diesen Befehl. Sie können render und Ihre images von Cloud Drive abholen.
/monitor
Wenn /monitor nicht funktioniert, versuchen Sie /start. Dies wird dem Bot einen Anstoß geben.
PING
"Sind wir down, ist Telegram down, oder hat die Warteschlange mich vergessen?" /ping versucht, all diese Fragen auf einen Blick zu beantworten
/ping
Wenn /ping nicht funktioniert, versuchen Sie /start. Dies wird dem Bot einen Anstoß geben.
SETTINGS
Sie können die Standardkonfiguration Ihres Bots überschreiben, z. B. nur ein bestimmtes sampler, steps, und eine sehr nützliche Einstellung: Ihr bevorzugtes Basismodell anstelle von Stable Diffusion 1.5
/settings
Verfügbare settings: /settings /concept:none /settings /guidance:random /settings /style:none /settings /sampler:random /settings /steps:default /settings /silent:off Achten Sie genau auf die Statusmeldungen, wenn Sie eine Einstellungsänderung vornehmen, da sie Ihnen mitteilen, wie Sie die Änderung rückgängig machen können. Manchmal ist für die Rückgängigmachung der Parameter off, none oder default erforderlich. Bevor Sie eine Änderung an den Standardeinstellungen vornehmen, sollten Sie die Standardeinstellungen, wie unten beschrieben, als Loadout auf save speichern, damit Sie die Änderungen rückgängig machen können, wenn Sie mit Ihrer Konfiguration nicht zufrieden sind und von vorne beginnen möchten.
LOADOUTS
Der Befehl /settings zeigt auch Ihre Ausrüstungen am Ende der Antwort an.
Erleichtern Sie sich den Wechsel von Arbeitsabläufen, indem Sie Loadouts speichern. Vielleicht haben Sie zum Beispiel ein bevorzugtes Basismodell und sampler für anime und ein anderes für Realismus oder ein anderes settings für ein bestimmtes Projekt oder einen bestimmten Kunden. Mit Loadouts können Sie alle Ihre settings im Handumdrehen ersetzen.
Wenn ich zum Beispiel meine settings so wie sie ist, auf save stellen möchte, kann ich mir einen Namen wie Morgan's Presets Feb 14 ausdenken:
/settings /save:morgans-presets-feb14
Verwalten Sie Ihre Ausrüstungen: Save aktuell settings: /settings /save:coolset1 Aktuelles anzeigen settings: /settings /show:coolset1 Abrufen einer Einstellung: /settings /load:coolset1
SILENT MODE
Sind die Debugging-Meldungen, wie z. B. die Bestätigung der Wiederholung einer Eingabeaufforderung, zu wortreich? Mit dieser Funktion können Sie den Bot vollständig silent machen. Vergessen Sie nur nicht, dass Sie diese Funktion aktiviert haben, sonst werden Sie denken, dass der Bot Sie ignoriert. Er wird Ihnen nicht einmal eine geschätzte Zeit von render oder irgendwelche Bestätigungen mitteilen!
/settings /silent:on
Um sie wieder einzuschalten, ändern Sie einfach ON in OFF
Veraltet und experimentell
Dies ist eine Sammlung von Experimenten. Ältere Befehle werden noch unterstützt, sind aber durch neuere Techniken ersetzt worden. Diese sind für die Produktion nur schwer zu empfehlen, machen aber dennoch Spaß.
ÄSTHETIK-BEWERTUNG
Ästhetik ist eine experimentelle Option, die ein Modell zur Bewertung der Ästhetik eines gerenderten Bildes als Teil des Rendering-Prozesses ermöglicht. Dies ist jetzt auch in der Graydient API verfügbar.
Diese Modelle des maschinellen Lernens versuchen, die visuelle Qualität/Schönheit eines Bildes auf numerische Weise zu bewerten
/render a cool cat <sdxl> /aesthetics
Sie liefert eine Ästhetik ("Schönheit") von 1-10 und eine Artefaktbewertung von 1-5 (niedrig ist besser). Um zu sehen, was als gut oder schlecht angesehen wird, sehen Sie hier den Datensatz. Die Bewertung kann auch in / angezeigt werden.showprompt
BREW
Brew wurde durch /polly ersetzt (es diente der Hinzufügung von Zufallseffekten).
/brew ein cooler Hund = /polly cooler Hund
Dies führt zu demselben Ergebnis.
MEME
Wir haben dieses Meme als Scherz hinzugefügt, aber es funktioniert immer noch und ist ziemlich witzig. Sie können den Text der Schriftart Internet Huge IMPACT oben und unten in Ihr Bild einfügen, einen Abschnitt nach dem anderen.
/meme /top:Man kann nicht einfach
(nächste Runde)
/meme /bottom:Gang nach Mordor
ANLEITUNG PIX 2 PIX
Ersetzt durch: Inpaint, Outpaint, und Remix
Das war seinerzeit der letzte Schrei, eine Technologie namens Instruct Pix2Pix, der /edit-Befehl. Antworten Sie auf ein Foto wie dieses:
/Bearbeiten Feuerwerk zum Himmel hinzufügen
Stellen Sie "Was wäre wenn"-Fragen style für images von Landschaften und Natur, in natürlicher Sprache, um Veränderungen zu sehen. Diese Technologie ist zwar cool, aber Instruct Pix2Pix liefert Ergebnisse mit niedriger Auflösung, so dass es schwer zu empfehlen ist. Außerdem ist es auf seine eigene Art style beschränkt, so dass es nicht mit unseren concepts, Loras, Embeddings usw. kompatibel ist. Es ist auf eine Auflösung von 512×512 beschränkt. Wenn Sie mit Lewds oder anime arbeiten, ist es das falsche Werkzeug für diese Aufgabe. Verwenden Sie stattdessen /remix . Sie können auch control den Effekt mit einem Stärkeparameter
/edit /strength:0.5 Was ist, wenn die Gebäude brennen?
STILEN
Die Formatvorlagen wurden durch das leistungsfähigere Rezeptsystem ersetzt. Stile werden verwendet, um persönliche Eingabeaufforderungs-Kurzbefehle zu erstellen, die nicht zur Weitergabe gedacht sind. Sie können mit dem Kopierbefehl Stile mit einer anderen Person austauschen, aber sie werden nicht funktionieren, wenn Sie diese Codes nicht kennen. Unsere Benutzer fanden das verwirrend, deshalb sind die Rezepte global. Um diese Funktion zu erkunden, geben Sie ein: