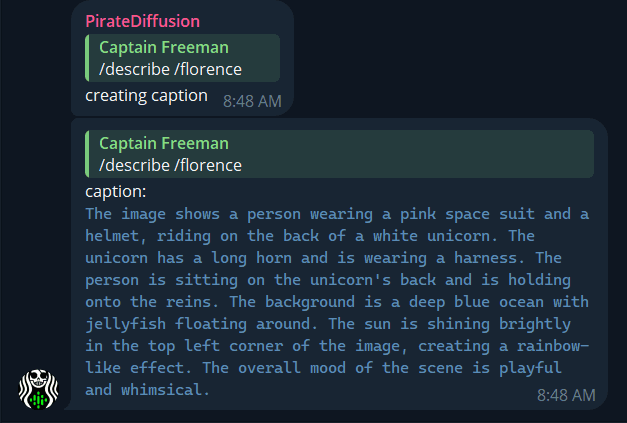
Veuillez nous mettre temporairement en pause ou nous inscrire sur la liste blanche pour créer un compte.
Si vous avez ouvert notre lien à partir d'une application, cherchez les 3 points en haut à droite pour ouvrir notre page dans votre navigateur. Nous n'affichons pas de publicités et ne vendons/partageons pas vos données, mais notre site web nécessite Javascript pour fonctionner correctement. Nous vous remercions ! -Équipe Graydient
PirateDiffusion Guide
Pirate Diffusion
Is there a Checkpoint, Embedding, LoRA, or other model that you want preloaded? Request a model install
Pirate Diffusionby Graydient AI is the most powerful bot on Telegram. It is a multi-modal bot, meaning that it handles large language models like DeepSeek and Llama 3.3, tens of thousands of image models like HiDream, Chroma, FLUX, Stable Diffusion 3.5, AuraFlow, Pony, and SDXL and also video models like Wan, Hunyuan and LightTricks (LTX).
Une valeur incroyable
Contrairement à d'autres services d'IA générative, aucun "jeton" ou "crédit" n'est requis. PirateDiffusion est conçu pour une utilisation illimitée, libre de droits, et il est fourni avec Graydientet webUI.
Pourquoi utiliser un robot ?
Il est extrêmement rapide et léger sur mobile, et vous pouvez l'utiliser en solo ou dans des groupes d'étrangers ou d'amis. Notre site community crée des macros de chat pour les flux de travail puissants de ComfyUI, de sorte que vous obtenez tous les avantages d'un résultat de rendu de bureau à partir d'un simple bot de chat. C'est fou.
Que peut-il faire d'autre ?
Images, vidéo, et LLM chats. Il peut faire à peu près tout.
Vous pouvez créer des images 4k en quelques frappes sans interface graphique. Vous pouvez utiliser toutes les principales fonctions de Stable Diffusion via le chat. Certaines fonctionnalités nécessitent une interface visuelle, et une page web s'affiche pour celles-ci (intégration Unified WebUI ).
Créez vous-même avec votre bot privé, ou rejoignez des groupes pour voir ce que d'autres personnes sont en train de créer. Vous pouvez également créer des bots thématiques comme /animebot qui relie nos LLM PollyGPT aux modèles StableDiffusion, et discuter avec eux pour vous aider à créer ! Créez un workflow qui vous est totalement propre en utilisant des loadouts, recipe (macros), des widgets (visual gui builder) et des bots personnalisés. Cela fait beaucoup !
Histoire de l'origine
Le nom Pirate Diffusion provient de la fuite du modèle Stable Diffusion 1.5 d'octobre 2022, qui était source ouverte. Nous avons créé le premier bot Stable Diffusion sur Telegram et des milliers de personnes se sont manifestées, et c'est ainsi que nous avons commencé. Mais pour être tout à fait clair : il n'y a pas de piratage en cours ici, nous avons juste aimé le nom. Cependant, un nombre suffisant de personnes (et notre banque) ont trouvé que le nom était un peu exagéré, et nous avons donc rebaptisé notre entreprise "Graydient", mais nous aimons Pirate Diffusion. Il attire des personnes amusantes et intéressantes.
La génération illimitée de vidéos est disponible pour les membres Plus !
Si vous êtes membre du plan vidéo de Graydient, vous pouvez utiliser différents flux de travail vidéo. Il existe deux catégories générales de flux vidéo : la transformation d'un message en vidéo et la transformation d'une photo existante en vidéo. (À l'avenir, nous prévoyons d'ajouter la vidéo à la vidéo, mais cela n'est pas encore possible).
Text to music – two modes!
AUTOMATIC LYRICS
/makesong Write a song about being in the face by a California Rattlesnake. Incorporate "dirty sanchez" and "Roosevelt Hoover"
MANUAL LYRICS
We plan to offer multiple music workflows. The first is called “music-ace” and it works like this:
/workflow /run:music-ace [verse] gonna make some songs [bridge] gonna make em [chorus] with pirate diffusion yeah!
Tout d'abord, parcourez notre page sur les flux de travail et trouvez les noms courts de texte à vidéo. Les plus courants sont :
WAN 2.1 - le meilleur modèle vidéo open source actuel, écrivez une simple invite et cela se produit ! WAN semble avoir une meilleure adhésion au message et une meilleure animation que HunYuan, mais une moins bonne anatomie.
Boringvideo - crée des vidéos ordinaires réalistes qui semblent provenir d'un iPhone
HunYuan - trois types, voir le bas de la page du workflow pour les trouver. Hunyuan crée les vidéos les plus réalistes. Plus le chiffre "Q" est élevé, plus la qualité est grande, mais plus les vidéos sont courtes.
Vidéo - ceux qui s'appellent simplement Vidéo utilisent LTX Lighttricks, idéal pour les dessins animés en 3D.
/wf /run:video-hunylora-q8 cinematic low angle video of a ronald mcdonald clown eating a square hamburger, the restaurant ((sign text says "Wendys")), ronald mcdonald's clown costume has red afro hair and a red nose with white face paint, the restaurant is brown, the burger is pointy and square, the background has blur bokeh and people are walking around
PirateDiffusion supporte les vidéos et loras Hunyuan et LightTricks / LTX ! Nous ajoutons plusieurs modèles de vidéos et vous pouvez les utiliser de façon illimitée dans le cadre de notre service, ainsi qu'une formation illimitée aux images et aux loras.
Dans LTX, la structure de l'invite a une grande importance. Une invite courte produira une image statique. Une invite comportant trop d'actions et d'instructions entraînera un panoramique de la vidéo vers des pièces ou des personnages aléatoires.
Meilleures pratiques : Comment faire en sorte que votre site images soit cohérent
Nous recommandons d'utiliser un modèle d'invite comme celui-ci :
Décrivez d'abord ce que fait la caméra ou qui elle suit. Par exemple, une caméra en contre-plongée zoom, une caméra aérienne, un panoramique lent, un zoom arrière ou un éloignement, etc.
Décrivez ensuite le sujet et une action qu'il effectue sur quoi ou sur qui. Cette partie demande de l'entraînement ! Dans l'exemple ci-dessus, remarquez que Ronald mangeant le hamburger vient après la caméra et la mise en place de la scène
Décrivez la scène. Cela permet à l'IA de "segmenter" les éléments que vous souhaitez voir. Dans notre exemple, nous décrivons le costume et l'arrière-plan du clown.
Donnez des références à l'appui. Par exemple, dites "Cela ressemble à une scène de film ou d'émission de télévision"
You can specify a lora to control the art direction or character likeness. Add this to the end of the prompt like <move-enhancer-huny>
De l'image à la vidéo
Vous pouvez télécharger une photo et la transformer en vidéo. Il n'y a pas qu'une seule commande - regardez la série de workflow " animate " pour utiliser différents types de modèles d'IA. Essayez différents modèles et stratégies d'incitation pour trouver celui qui convient le mieux à votre projet, ou consultez le canal PLAYROOM de PirateDiffusion pour voir ce que d'autres ont créé avec ces modèles.
Le rapport hauteur/largeur de la vidéo sera déterminé par l'image que vous téléchargez, veuillez donc la recadrer en conséquence.
Pour ce faire, collez d'abord la photo dans le chat et cliquez sur "Répondre" comme si vous alliez parler à la photo, puis donnez-lui une commande comme celle-ci :
/wf /run:animate-wan21 a woman makes silly faces towards the camera
ou essayez l'un des autres flux de travail comme SkyReels :
/wf /run:animate-skyreels camera video that slightly changes the angle, focused on a lovely girl smiling and looking at the camera, she looks curious and confident while maintaining eyes on the viewer, her hair is parted, she sits in front of a bookshelf and peeping gremlin eyes behind her, she is relaxing vibe
Nous hébergeons des modèles d'IA open source pour la conversion d'images en vidéos. Les deux modèles les plus populaires sont :
animate-skyreels = convertir une image en vidéo en utilisant les vidéos réalistes HunYuan
animate-ltx90 = utilise le modèle LightTricks. Idéal pour les dessins animés en 3D et les vidéos cinématiques.
Paramètres spéciaux :
/slot1 = length de la vidéo en images. Les settings sûrs sont 89, 97, 105, 113, 121, 137, 153, 185, 201, 225, 241, 257. Plus est possible mais instable
/slot2 = images par seconde. 24 est recommandé. Les flux de travail turbo sont exécutés à 18 images par seconde, mais peuvent être modifiés. Au-delà de 24 images par seconde, c'est du cinéma, tandis que 30 images par seconde semblent plus réalistes. 60 images par seconde est possible à un faible nombre d'images, mais cela ressemble à la vitesse d'un tamia.
Limites :
Vous devez être membre de Graydient Plus pour créer des vidéos.
De nombreux exemples de vidéos sont disponibles aujourd'hui dans le canal VIP et Playroom. Venez passer du temps avec nous et envoyez-nous vos idées pendant que nous mettons la dernière main à la vidéo.
Précédent / Changelog :
Ajouté Wan 2.1 et Skyreels. Utilisez workflow /show : pour inspecter les paramètres des deux
Ajout de nouveaux Flux comme ur4 (ultra realistic 4) et flux (Bento TWO model)
Ajout des vidéos Hunyuan et LightTricks / LTX avec support lora
Ajout de Llama 3.3 et de nombreux autres LLM, tapez la commande //lm pour les parcourir.
Vous pouvez désormais utiliser jusqu'à six loras Flux avec certains flux de travail Flux .
Un HD Anime Illustrious workflow a été ajouté. Croustillant !
Flux Redux, Flux Controlnet Depth, et tant de nouveaux flux de travail sont maintenant disponibles.
Une meilleure peinture ! Essayez de répondre à une image avec /zoomout-flux
Meilleure intégration de LoRamaker. Utilisez /makelora pour créer une lora privée dans votre navigateur web, puis utilisez-la dans Telegram en quelques minutes.
Nouvelle commande LLM*. Tapez /llm suivi d'une question. Elle est actuellement alimentée par le modèle Llama 3 de 70 milliards de paramètres, et elle est rapide ! Nous ne censurons pas vos messages, mais le modèle lui-même peut avoir ses propres garde-fous. *LLM est l'abréviation de "Large Language Model", comme dans les modèles de chat similaires à ChatGPT.
De nombreux points de contrôle FLUX se trouvent ici. Tapez /workflows pour les explorer et obtenir leurs commandes. Autre nouveauté : un raccourci pour les flux de travail est /wf. Tutoriel vidéo
Plus de modèles, plus de 10 000 ! Essayez le nouveau Juggernaut 9 Lightning, il est plus rapide que Juggernaut X. Vous pouvez également l'utiliser en ajoutant ce hashtag : #jugg9
Les bots personnalisés peuvent désormais conserver des souvenirs. Voir "souvenirs" dans le tutoriel PollyGPT
Meilleure surveillance de render ! Tapez /monitor pour l'afficher, c'est une petite page web. Si les serveurs Telegram de votre ville sont occupés ou hors ligne, le site images peut être récupéré depuis notre Cloud Drive beaucoup plus rapidement !
Nouveau Bots! Essayez : /xtralargebot /animebot /lightningbot et bots bavard comme /kimmybot /angelinabot /nicolebot /senseibot
Les membres du plan Plus peuvent désormais choisir le paramètre Llama3 70 milliards pour leur bots
Nouvelles recettes : Essayez #quick pour une HD rapide images, ou #quickp pour les portraits, #quickw pour les photos larges.
Polly Mise à jour ! - Utilisez /polly pour discuter avec le robot, et cliquez avec le bouton droit de la souris sur la réponse pour converser.
Polly n'utilise plus que les modèles que vous avez marqués comme favoris dans Mes modèles
La nouvelle commande /unified envoie images à Stable2go pour l'édition web.
La nouvelle commande /bots - personnalisez Polly à votre goût, LLM + modèles d'images !
Essayez un nouveau recipe! Tapez /render #quick et votre invite
Préfabriqués et personnalisés bots
BASE : La commande LLM
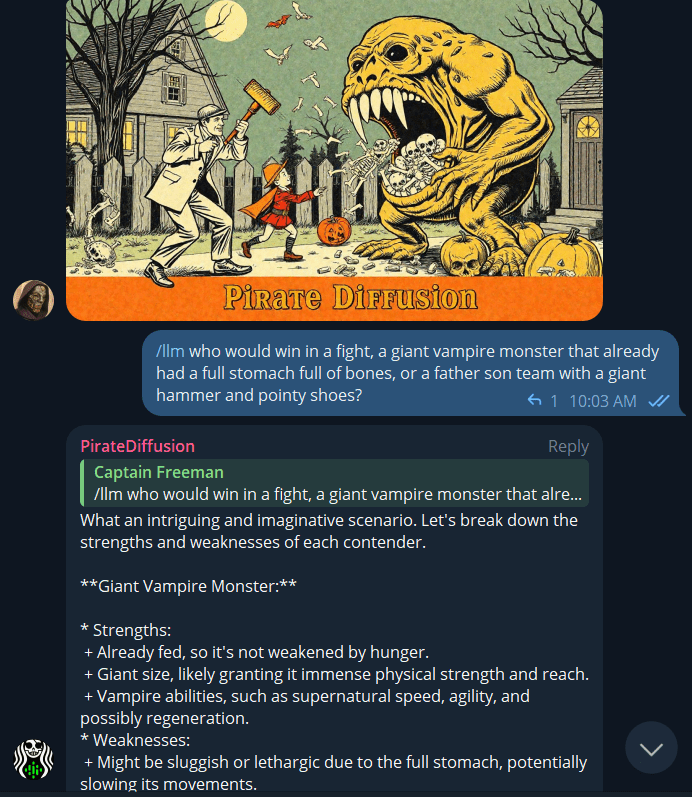
/llm who would win a fight between a pacifist tiger with a shotgun or a thousand angry penguins parachuting above with forks and knives?
Tapez /llm (comme LLM, grand modèle linguistique) et posez une question, comme ChatGPT. Il est alimenté par le modèle Llama3 de 70 milliards de paramètres.
CRÉEZ VOTRE PROPRE AGENT LLM
Pour passer à un autre modèle et personnaliser un autre personnage de chatbot, connectez-vous à my.graydient.ai et cliquez sur chatbots pour choisir d'autres LLM comme Mixtral et Wizard.
Présentation "POLLY"
Polly est l'un des caractères de PirateDiffusion qui parle et crée images. Essayez-le :
Si vous êtes dans le @piratediffusion_bot, vous pouvez parler à Polly comme suit :
/polly a silly policeman investigates a donut factory
Vous pouvez également l'utiliser à partir de votre navigateur web en vous connectant à my.graydient.ai et en cliquant sur l'icône Chat Bots .
INTRODUCTION À LA PERSONNALISATION BOTS
Polly n'est qu'un des nombreux personnages créés par notre site community. Pour voir la liste des autres personnages publics, tapez :
/bots
Pour en créer un nouveau, tapez
/bots /new
Cela lancera PollyGPT dans votre navigateur web pour former votre propre personnage, qui pourra ensuite être accessible en tant que personnage dans votre @piratediffusion_bot.
EXPLORER LE SUR-MESURE BOTS
Le site AI community regorge de créateurs intéressants. Certains proposent des modèles de langage de grande taille (alternatives à ChatGPT) ainsi que des modèles d'images open source (alternatives à DALLE et MJ). Notre logiciel original fait le lien entre ces deux éléments pour créer un "bot" facile à utiliser sur Telegram ou sur le web. Visitez notre page Polly GPTdocs - maintenant avec des souvenirs ! pour plus d'informations et des modèles pour créer votre propre bots.
Activation du robot
Un compte Graydient et un compte Telegram (gratuit) sont nécessaires pour utiliser PirateDiffusion. Configurer
Besoin d'aide avec votre robot ? Vous êtes bloqué sur mode? Contactez nous
Notions de base sur les comptes
NOUVEL UTILISATEUR
/start
COMMENT COMMENCER
Connectez-vous à my.graydient.ai et trouvez l'icône Setup dans le tableau de bord, et suivez les instructions.
Si vous avez mis à jour votre compte sur Patreon, votre email et celui de Patreon doivent correspondre. Si vous ne pouvez pas activer et déverrouiller toutes les fonctionnalités, veuillez taper /debug et envoyer ce numéro.
USERNAME
/username Tiny Dancer
Le robot utilisera votre nom Telegram comme nom public community username (affiché dans des endroits tels que les recettes, en vedette images). Vous pouvez changer cela à tout moment avec la commande /username , comme ceci :WEBUI et PASSWORDPirateDiffusion est livré avec un site web compagnon pour les opérations qui sont difficiles à faire, comme l'organisation de vos fichiers et l'inpainting. Pour accéder à votre archive, tapez :
/webui
Il est privé par défaut. Pour définir votre password, utilisez une commande comme celle-ci
Une invite est une description complète qui indique à l'IA quelle image générer :
Doit-il être réaliste ? Un type d'œuvre d'art ?
Décrire le moment de la journée, le point de vue et l'éclairage
Décrire correctement le sujet et ses actions
Décrire le lieu en dernier lieu, et autres détails
Exemple de base :
une femme blonde de 25 ans, influenceuse Instagram, vivant le style de vie du travel van.
Conseil : Utilisez /render #quick - une macro pour obtenir cette qualité sans avoir à taper des négations.
Conseils pour les messages rapides
1. Décrire toujours l'ensemble du tableau, à chaque fois
Une invite n'est pas un message de chat, ce qui signifie qu'il ne s'agit pas d'une conversation à plusieurs tours. Chaque invite est un nouveau tour pour le système, qui oublie tout ce qui a été tapé au tour précédent. Par exemple, si nous demandons "un chien en costume", nous l'obtiendrons certainement. Cette invite décrit complètement une photo. Si nous demandons seulement "rendez-le rouge" (idée incomplète), nous ne verrons pas du tout le chien parce que "il" n'a pas été reporté, et l'invite sera donc mal comprise. Il faut toujours présenter l'instruction complète.
2. L'ordre des mots est important
Placez les mots les plus importants au début du texte. Si vous créez un portrait, placez l'apparence de la personne en premier et ce qu'elle porte, suivi de ce qu'elle est et de l'endroit où elle se trouve comme les détails les moins importants.
3. Length est également important
Les mots du début sont les plus importants, et chaque mot vers la fin reçoit de moins en moins d'attention - jusqu'à environ 77 "tokens" ou instructions. Cependant, vous devez savoir que chaque IA concept de notre système est formée sur des sujets différents, et que le choix de la bonne concept aura un impact sur la façon dont vous serez compris. Il est préférable de s'en tenir à l'essentiel et d'apprendre à connaître le concepts système ci-dessous) plutôt que de rédiger de longs messages pour obtenir des résultats de la plus haute qualité.
Suggestions positives
Les invites positives et négatives sont des mots qui indiquent à l'IA ce que nous voulons voir et ce que nous ne voulons pas voir. Les humains ne communiquent généralement pas sous une forme aussi binaire, mais dans un environnement très bruyant, nous pourrions dire "ceci, mais cela !".
Positif : Une scène de plage de jour avec un sable bleu clair, des palmiers Négatif : Personnes, bateaux, bikinis, NSFW
Ceci est entré dans les deux cases de l'éditeur de Stable2go, comme ceci :
Les messages positifs contiennent le sujet et les détails de l'image. Ils permettent de décrire l'art style et son environnement, ainsi que vos attentes en matière d'esthétique. Exemples :
photo réaliste d'un chiot de la meilleure qualité
dessin de chef-d'oeuvre d'un tournesol, fond bokeh
photo en contre-plongée d'un scooter dans une allée, aquarelles
une tortue avec une ((bière))
Important: une commande de création d'image doit précéder l'invite positive, comme /render et /polly. Voir la syntaxe ci-dessous:
Renforcer l'impact des points positifs
Pour mettre davantage l'accent sur certains mots, ajoutez des parenthèses imbriquées. Cela augmente leur facteur de 1,1x.
Dans l'exemple ci-dessus, nous disons que la "tortue" est le sujet, parce qu'elle apparaît au début de l'invite, mais que la bière est tout aussi importante, même si elle apparaît plus tard dans l'invite. Lorsqu'il s'agit de créer des situations improbables, il est utile d'insister davantage.
Négatifs décrivez ce que vous ne voulez pas voir dans l'image.
Si vous voulez un Seamonster mais pas la mer, le monstre est fait pour vous. positif et l'océan est votre négatif.
Les négatifs peuvent également favoriser la qualité des photos, en décourageant l'utilisation de membres supplémentaires, d'une faible résolution, etc.
Renforcer les aspects négatifs
Les parenthèses permettent une mise en valeur de 1,1 fois. Utilisez des crochets pour les négations.
(donnez-moi ce que je veux) [mais, pas, ces, choses]
DépannageSi l'image a un aspect glitched et que le site guidance est réglé sur 7, il se peut que les négatifs soient réglés trop fortement. Essayez de réduire leur intensité.
Les points positifs et négatifs étaient autrefois le seul moyen d'orienter l'IA vers ce que nous voulions, mais ce n'est plus nécessaire. Utilisez plutôt concepts (ci-dessous) plus d'exemples
Commandes professionnelles
Créez images comme un professionnel de la diffusion stable avec ces paramètres :
RENDER
Si vous ne souhaitez pas bénéficier de l'aide à l'écriture de Polly ou de votre bots personnalisé, passez à la commande /render pour passer en mode manuel. Essayez une leçon rapide.
/render a close-up photo of a gorilla jogging in the park <sdxl>
Les points positifs indiquent à l'IA ce qu'elle doit mettre en avant. Cela s'exprime par des (parenthèses rondes). Chaque paire de crochets représente un multiple de 1,1x du renforcement positif. Les négatifs font l'inverse, en utilisant des crochets.
L'ajout d'un trop grand nombre de parenthèses peut limiter les possibilités de remplissage de l'IA. Par conséquent, si vous constatez des anomalies dans votre image, essayez de réduire le nombre de parenthèses et d'inversions.
Astuce : Comment modifier rapidement une invite : Une fois l'invite soumise, rappelez-la rapidement en appuyant sur la flèche vers le haut du bureau Telegram. Vous pouvez également appuyer une seule fois sur la confirmation de l'invite qui apparaît dans une police de caractères alt. L'ordre des mots est important. Pour de meilleurs résultats, placez les mots les plus importants au début de votre message : Angle de la caméra, Qui, Quoi, Où.
TRADUCTION
Vous préférez demander dans une autre langue ? Vous pouvez consulter le site render images dans plus de 50 langues :
/render /translate un perro muy guapo <sdxl>
Il n'est pas nécessaire de spécifier la langue, il le sait, c'est tout. Lorsque vous traduisez, évitez d'utiliser l'argot. Si l'IA n'a pas compris votre demande, essayez de la reformuler en termes plus clairs.
Limites de la traduction
Certains mots d'argot régional peuvent être mal compris. Il convient donc d'utiliser la fonction de traduction de la manière la plus littérale et la plus exacte possible. Par exemple, "cubito de hielo" peut signifier petit glaçon ou petit seau de glace en espagnol, selon la région et la nuance contextuelle.
Pour être honnête, cela peut également se produire en anglais, car l'IA peut prendre les choses trop au pied de la lettre. Par exemple, un utilisateur a demandé un ours polaire en train de chasser , et l'IA lui a donné un fusil de sniper. Une conformité malveillante !
Pour éviter cela, utilisez plusieurs mots dans vos messages positifs et négatifs.
RECIPE MACROS
Les recettes sont des modèles d'invite. Un site recipe peut contenir des jetons, des échantillonneurs, des modèles, des inversions textuelles, etc. Cela permet de gagner du temps et vaut la peine d'être appris si vous vous retrouvez à répéter sans cesse les mêmes choses dans votre message.
Lorsque nous avons introduit les inversions négatives, beaucoup nous ont demandé pourquoi elles n'étaient pas activées par défaut, et la réponse est control - tout le monde aime les settings légèrement différents. Notre solution a été de créer des recettes : des hashtags qui convoquent des modèles d'invite.
La plupart des recettes ont été créées par community, et peuvent changer à tout moment car elles sont gérées par leurs propriétaires respectifs. Une invite est censée n'avoir qu'une seule recipe, sinon les choses peuvent devenir bizarres.
Il y a deux façons d'utiliser un recipe. Vous pouvez l'appeler par son nom en utilisant un hashtag, comme le "quick" recipe:
/render a cool dog #quick
Certaines recettes populaires sont #nfix et #eggs et #boost et #everythingbad et #sdxlreal.
Important : lors de la création d'un site recipe, il est nécessaire d'ajouter $prompt quelque part dans votre zone d'invite positive, sinon le site recipe ne pourra pas accepter votre saisie de texte. Vous pouvez l'ajouter n'importe où, c'est flexible.
Dans le champ "autres commandes", vous pouvez empiler d'autres paramètres d'amélioration de la qualité ci-dessous.
COMPOSE
Compose permet une création multi-prompt et multi-régionale. Les zones disponibles sont les suivantes : arrière-plan, bas, bas-centre, bas-gauche, bas-droite, centre, gauche, droite, haut, haut-centre, haut-gauche, haut-droite. Le format de chaque zone est x1, y1, x2, y2.
/compose /size:2000x700 /left:The tower of Thai food /center:Jungles of Thailand, tropical rainforest [blurry] /right: Castle made of stone, castle in the jungle, tropical vegetation
Autre exemple
/compose /seed:1 /images:2 /size:384×960 /top:ZeldaKingdom GloomyCumulonimbus /bottom:1983Toyota Have a Cookie /guidance:5
Conseil : utilisez une adresse guidance d'environ 5 pour un meilleur mélange. Vous pouvez également spécifier le modèle. Guidance s'applique à l'ensemble de l'image. Nous travaillons à l'ajout de guidance régionaux.
/compose /size:1000x2000 /top: Lion roaring, lion on top of building /center: Apartment building, front of building, entrance /bottom: Dirty city streets, New York city streets [[ugly]] [[blurry] /images:1 /guidance:7
Blend vous permet de fusionner plusieurs images qui sont stockés images dans votre bibliothèque ControlNet . Ceci est basé sur une technologie appelée adaptateurs IP. Ce nom est horriblement confus pour la plupart des gens, nous l'appelons donc simplement blend.
Tout d'abord, créez une image prédéfinie concepts en collant une photo dans votre robot et en lui donnant un nom exactement comme vous le feriez pour ControlNet. Si vous avez déjà des contrôles enregistrés, ils fonctionnent également.
/control /new:chicken
Une fois que vous en avez deux ou plus, vous pouvez les réunir à l'adresse blend .
/render /blend:chicken:1 /blend:zelda:-0.4
Astuce : Les adaptateurs IP supportent les images négatives images. Il est recommandé de soustraire une image de bruit pour obtenir de meilleures images.
Vous pouvez control le bruit de cette image avec /blendnoise
La valeur par défaut est 0.25. Vous pouvez la désactiver avec /blendnoise:0.0
Vous pouvez également définir l'intensité de l'effet des adaptateurs IP avec /blendguidance - la valeur par défaut est de 0,7.
Conseil : Blend peut également être utilisé pour peindre des modèles SDXL.
/render /adetailer a close-up photo of a gorilla jogging in the park <sdxl>
Cette fonction analyse votre image pour détecter les mains, les yeux et les visages défectueux immédiatement après la création de l'image, et les corrige automatiquement. Il fonctionne avec SDXL et SD15 à partir de mars 24.
Limites : Il peut manquer des faces tournées à ~15 degrés ou créer deux faces dans ce cas.
After Detailer fonctionne mieux lorsqu'il est utilisé avec de bonnes incitations positives et négatives, et des inversions, expliquées ci-dessous :
GRATUIT U
FreeU (Free Lunch in Diffusion U-Net) est un détaillant expérimental qui élargit la gamme guidance à quatre intervalles distincts au cours de la période render. Il existe quatre valeurs possibles, chacune comprise entre 0 et 2. b1 : facteur d'épine dorsale de la première étape b2 : facteur d'épine dorsale de la deuxième étape s1 : facteur de saut de la première étape s2 : facteur de saut de la deuxième étape
/render <av5> a drunk horse in Rome /freeu:1.1,1.2,0.9,0.2
Commandes de création d'images
POLLY
Polly est votre assistant de création d'images et le moyen le plus rapide de rédiger des messages-guides détaillés. Lorsque vous 'Fave un modèle dans conceptsPolly choisira au hasard l'un de vos modèles préférés.
Pour utiliser Polly dans Telegram, parlez-lui comme suit :
/polly a silly policeman investigates a donut factory
La réponse contiendra une invite que vous pouvez render ou copier dans votre presse-papiers pour l'utiliser avec la commande /render (expliquée ci-dessous).
Vous pouvez également avoir une conversation régulière en commençant par /raw
/polly /raw explain the cultural significance of japanese randoseru
Vous pouvez également l'utiliser à partir de votre navigateur web en vous connectant à my.graydient.ai et en cliquant sur l'icône Polly .
Bots affiche la liste des assistants que vous avez créés. Par exemple, si mon assistante est Alice, je peux l'utiliser comme /alicebot va me faire un sandwich. Le @piratediffusion_bot doit être dans le même canal que vous.
Pour en créer un nouveau, tapez
/bots /new
RENDER
Si vous ne souhaitez pas bénéficier de l'aide à l'écriture de Polly ou de votre bots personnalisé, passez à la commande /render pour passer en mode manuel. Essayez une leçon rapide.
/render a close-up photo of a gorilla jogging in the park <sdxl>
Les points positifs indiquent à l'IA ce qu'elle doit mettre en avant. Cela s'exprime par des (parenthèses rondes). Chaque paire de crochets représente un multiple de 1,1x du renforcement positif. Les négatifs font l'inverse, en utilisant des crochets.
L'ajout d'un trop grand nombre de parenthèses peut limiter les possibilités de remplissage de l'IA. Par conséquent, si vous constatez des anomalies dans votre image, essayez de réduire le nombre de parenthèses et d'inversions.
Astuce : Comment modifier rapidement une invite : Une fois l'invite soumise, rappelez-la rapidement en appuyant sur la flèche vers le haut du bureau Telegram. Vous pouvez également appuyer une seule fois sur la confirmation de l'invite qui apparaît dans une police de caractères alt. L'ordre des mots est important. Pour de meilleurs résultats, placez les mots les plus importants au début de votre message : Angle de la caméra, Qui, Quoi, Où.
TRADUCTION
Vous préférez demander dans une autre langue ? Vous pouvez consulter le site render images dans plus de 50 langues :
/render /translate un perro muy guapo <sdxl>
Il n'est pas nécessaire de spécifier la langue, il le sait, c'est tout. Lorsque vous traduisez, évitez d'utiliser l'argot. Si l'IA n'a pas compris votre demande, essayez de la reformuler en termes plus clairs.
Limites de la traduction
Certains mots d'argot régional peuvent être mal compris. Il convient donc d'utiliser la fonction de traduction de la manière la plus littérale et la plus exacte possible. Par exemple, "cubito de hielo" peut signifier petit glaçon ou petit seau de glace en espagnol, selon la région et la nuance contextuelle.
Pour être honnête, cela peut également se produire en anglais, car l'IA peut prendre les choses trop au pied de la lettre. Par exemple, un utilisateur a demandé un ours polaire en train de chasser , et l'IA lui a donné un fusil de sniper. Une conformité malveillante !
Pour éviter cela, utilisez plusieurs mots dans vos messages positifs et négatifs.
RECIPE MACROS
Les recettes sont des modèles d'invite. Un site recipe peut contenir des jetons, des échantillonneurs, des modèles, des inversions textuelles, etc. Cela permet de gagner du temps et vaut la peine d'être appris si vous vous retrouvez à répéter sans cesse les mêmes choses dans votre message.
Lorsque nous avons introduit les inversions négatives, beaucoup nous ont demandé pourquoi elles n'étaient pas activées par défaut, et la réponse est control - tout le monde aime les settings légèrement différents. Notre solution a été de créer des recettes : des hashtags qui convoquent des modèles d'invite.
La plupart des recettes ont été créées par community, et peuvent changer à tout moment car elles sont gérées par leurs propriétaires respectifs. Une invite est censée n'avoir qu'une seule recipe, sinon les choses peuvent devenir bizarres.
Il y a deux façons d'utiliser un recipe. Vous pouvez l'appeler par son nom en utilisant un hashtag, comme le "quick" recipe:
/render a cool dog #quick
Certaines recettes populaires sont #nfix et #eggs et #boost et #everythingbad et #sdxlreal.
Important : lors de la création d'un site recipe, il est nécessaire d'ajouter $prompt quelque part dans votre zone d'invite positive, sinon le site recipe ne pourra pas accepter votre saisie de texte. Vous pouvez l'ajouter n'importe où, c'est flexible.
Dans le champ "autres commandes", vous pouvez empiler d'autres paramètres d'amélioration de la qualité ci-dessous.
COMPOSE
Compose permet une création multi-prompt et multi-régionale. Les zones disponibles sont les suivantes : arrière-plan, bas, bas-centre, bas-gauche, bas-droite, centre, gauche, droite, haut, haut-centre, haut-gauche, haut-droite. Le format de chaque zone est x1, y1, x2, y2.
/compose /size:2000x700 /left:The tower of Thai food /center:Jungles of Thailand, tropical rainforest [blurry] /right: Castle made of stone, castle in the jungle, tropical vegetation
Autre exemple
/compose /seed:1 /images:2 /size:384×960 /top:ZeldaKingdom GloomyCumulonimbus /bottom:1983Toyota Have a Cookie /guidance:5
Conseil : utilisez une adresse guidance d'environ 5 pour un meilleur mélange. Vous pouvez également spécifier le modèle. Guidance s'applique à l'ensemble de l'image. Nous travaillons à l'ajout de guidance régionaux.
/compose /size:1000x2000 /top: Lion roaring, lion on top of building /center: Apartment building, front of building, entrance /bottom: Dirty city streets, New York city streets [[ugly]] [[blurry] /images:1 /guidance:7
Blend vous permet de fusionner plusieurs images qui sont stockés images dans votre bibliothèque ControlNet . Ceci est basé sur une technologie appelée adaptateurs IP. Ce nom est horriblement confus pour la plupart des gens, nous l'appelons donc simplement blend.
Tout d'abord, créez une image prédéfinie concepts en collant une photo dans votre robot et en lui donnant un nom exactement comme vous le feriez pour ControlNet. Si vous avez déjà des contrôles enregistrés, ils fonctionnent également.
/control /new:chicken
Une fois que vous en avez deux ou plus, vous pouvez les réunir à l'adresse blend .
/render /blend:chicken:1 /blend:zelda:-0.4
Astuce : Les adaptateurs IP supportent les images négatives images. Il est recommandé de soustraire une image de bruit pour obtenir de meilleures images.
Vous pouvez control le bruit de cette image avec /blendnoise
La valeur par défaut est 0.25. Vous pouvez la désactiver avec /blendnoise:0.0
Vous pouvez également définir l'intensité de l'effet des adaptateurs IP avec /blendguidance - la valeur par défaut est de 0,7.
Conseil : Blend peut également être utilisé pour peindre des modèles SDXL.
/render /adetailer a close-up photo of a gorilla jogging in the park <sdxl>
Cette fonction analyse votre image pour détecter les mains, les yeux et les visages défectueux immédiatement après la création de l'image, et les corrige automatiquement. Il fonctionne avec SDXL et SD15 à partir de mars 24.
Limites : Il peut manquer des faces tournées à ~15 degrés ou créer deux faces dans ce cas.
After Detailer fonctionne mieux lorsqu'il est utilisé avec de bonnes incitations positives et négatives, et des inversions, expliquées ci-dessous :
GRATUIT U
FreeU (Free Lunch in Diffusion U-Net) est un détaillant expérimental qui élargit la gamme guidance à quatre intervalles distincts au cours de la période render. Il existe quatre valeurs possibles, chacune comprise entre 0 et 2. b1 : facteur d'épine dorsale de la première étape b2 : facteur d'épine dorsale de la deuxième étape s1 : facteur de saut de la première étape s2 : facteur de saut de la deuxième étape
/render <av5> a drunk horse in Rome /freeu:1.1,1.2,0.9,0.2
Concepts vue d'ensemble
Concepts sont des modèles d'IA spécialisés qui génèrent des choses spécifiques qui ne peuvent pas être bien comprises avec une simple invite. Plusieurs sites concepts peuvent être utilisés ensemble : Généralement, un modèle de base et 1 à 3 LoRas ou Inversions constituent l'utilisation la plus courante.
Vous pouvez également former votre propre personnel en lançant l'interface web de formation :
/makelora
Une remarque sur les loras personnalisées et la protection de la vie privée :
Loras privé : Utilisez toujours la commande /makelora de votre conversation privée avec @piratediffusion_bot pour créer une lora que vous seul pouvez voir. Vous pouvez également utiliser cette commande dans votre sous-domaine privé, mais elle n'apparaîtra PAS sur l'instance partagée de Stable2go ou la création rapide dans MyGraydient.
Public Loras : Pour former et partager votre LoRa avec l'ensemble de community, connectez-vous à my.graydient.ai et cliquez sur l'icône LoRaMaker. Ces loras apparaîtront pour tout le monde, y compris votre bot Telegram.
Famille de modèles Notre logiciel prend en charge deux familles de Stable Diffusion à l'heure actuelle : SD15 (plus ancienne, formée à 512×512) et Stable Diffusion XL, qui est nativement de 1024×1024. En restant proche de ces résolutions, vous obtiendrez les meilleurs résultats (et éviterez les membres en double, etc.).
La chose la plus importante à noter est que les familles ne sont pas compatibles entre elles. Une base SDXL ne peut pas être utilisée avec une Lora SD15, et vice-versa.
Syntaxe :
LISTE DES MODÈLES
The term AI model can also mean chat models, so we call image models “concepts”. A concept can be a person, pose, effect, or art style. To bring those things into your creation, we call their “trigger word” which appear in angled brackets like this: <sdxl> Our platform has over 8 terabytes of AI concepts preloaded. PirateDiffusion is never stuck in one style, we add new ones daily.
/concepts
L'objectif de la commande /concepts est de rechercher rapidement les mots déclencheurs pour les modèles sous forme de liste dans Telegram. À la fin de cette liste, vous trouverez également un lien pour consulter visuellement concepts sur notre site web.
Utilisation concepts
Pour créer une image, associez le mot déclencheur d'un site conceptà la commande render (expliquée ci-dessous) et décrivez la photo.
To use one, use it’s trigger name anywhere in the prompt. For example, one of the most popular concepts of the moment is called Realistic Vision 5 SDXL, a realistic “base model” — the basis of the overall image style. The trigger name for Realistic Vision 5 SDXL is <realvis5-xl> so we would then prompt.
/render a dog <realvis4-xl>
Conseil : Choisissez un modèle de base (comme realvis4-xl), un ou trois loras et quelques inversions négatives pour créer une image équilibrée. L'ajout d'un trop grand nombre d'images ou d'images contradictoires (comme 2 poses) sur le site concepts peut provoquer des artefacts. Essayez une leçon ou créez-en une vous-même
RECHERCHE DE MODÈLES
Vous pouvez effectuer des recherches directement à partir de Telegram.
/concept /search:emma
MODÈLES RÉCENTS
Rappelez-vous rapidement les derniers que vous avez essayés :
/concept /recent
MODÈLES PRÉFÉRÉS
Utilisez la commande fave pour suivre et mémoriser vos modèles préférés dans une liste personnelle.
/concept /fave:concept-name
MON MODÈLE PAR DÉFAUT
La diffusion stable 1.5 est le modèle par défaut, mais pourquoi ne pas le remplacer par votre modèle préféré ?
This will impact both your Telegram and Stable2go account. After you do this command, you don’t have to write that <concept-name> every time in your prompts. Of course, you can override it with a different model in a /render.
/concept /default:concept-name
Types de Concepts
Les modèles de base sont également appelés "modèles complets" et déterminent le plus fortement le site style de l'image. Les LoRas et les inversions textuelles sont des modèles plus petits pour des contrôles fins. Il s'agit de petits fichiers spécifiques à un sujet, généralement une personne ou une pose. Les modèles d'inpainting ne sont utilisés que par les outils Inpaint et Outpaint, et ne doivent pas être utilisés pour le rendu ou à d'autres fins.
Tags spéciaux concept
Le système concepts est organisé par étiquettes, avec un large éventail de sujets allant des animaux aux poses.
Il existe des balises spéciales appelées Types, qui vous indiquent comment le modèle se comporte. Il existe également des remplacements pour les invites positives et négatives, appelés "Detailers" et "Negatives". Lorsque vous utilisez le type Negative concept , n'oubliez pas de définir également le poids comme négatif.
INVERSIONS NÉGATIVES
Le système de modèles dispose de modèles spéciaux appelés inversions négatives, également appelés "negative embeddings". Ces modèles ont été entraînés intentionnellement sur le site images , afin de guider l'IA sur ce qu'il ne faut pas faire. Ainsi, en appelant ces modèles en tant que négatif, ils augmentent la qualité de manière significative. Le poids de ces modèles doit être entre doubles [[crochets négatifs]], entre -0,01 et -2.
/render <sdxl> [[<fastnegative-xl:-2>]]
Takoyaki on a plate
Les modèles portant des noms à consonance rapide comme "Hyper" et "Turbo" peuvent render images rapidement avec des paramètres faibles, expliqués ci-dessous dans Guidance / CFG.
Les chiffres qui figurent à côté des noms de modèles sont des "poids"
Vous pouvez control déterminer l'influence d'un modèle sur votre image en ajustant son poids. Nous avons besoin de poids parce que les modèles ont des opinions et qu'ils tirent l'image dans leur propre direction d'apprentissage. Lorsque plusieurs modèles sont ajoutés, cela peut entraîner une pixellisation et une distorsion s'ils ne sont pas d'accord. Pour résoudre ce problème, nous pouvons diminuer ou augmenter le poids de chaque modèle afin d'obtenir ce que nous voulons.
Les règles de pondération
Les modèles complets ne sont pas réglables. Également connus sous le nom de points de contrôle ou modèles de base, il s'agit de grands fichiers qui déterminent l'influence artistique globale style. Pour modifier l'influence artistique du modèle de base, il suffit de le remplacer par un autre modèle de base. C'est la raison pour laquelle le système en comporte autant.
Les LoRas et les inversions textuelles ont des poids flexibles.
Le fait de déplacer le poids vers le positif rend ces modèles plus audacieux. En termes simples, les LoRas sont des versions plus détaillées des inversions textuelles.
MEILLEURES PRATIQUES
Utilisez toujours un modèle de base et ajoutez des loras et des inversions.
Le chargement de plusieurs modèles de base ne les blend pas, il n'en chargera qu'un seul, mais il "tokenisera" les autres que vous avez chargés, ce qui signifie que vous pouvez simplement taper leur nom et la même chose se produira sans ralentir votre render (moins de modèles en mémoire = plus rapide).
Pour les LoRas et les Inversions, vous pouvez utiliser les deux et plusieurs d'entre eux à la fois, mais la plupart des gens s'en tiennent à 1-3 car c'est plus facile à équilibrer.
Les utilisateurs de SDXL trouveront dans le système de nombreuses étiquettes appelées "-type". Il s'agit d'une sous-famille de modèles qui fonctionnent mieux lorsqu'ils sont chargés ensemble. Au moment de la rédaction de ce guide, le type le plus populaire est le Poney (pas littéralement les poneys) qui a une meilleure cohésion rapide, en particulier pour les trucs sexy. Les Loras Pony fonctionnent mieux avec les modèles de base Pony, et ainsi de suite.
PONDÉRATIONS POSITIVES DU MODÈLE
Les limites des poids sont -2 (négatif) et 2 (maximum). Une pondération comprise entre 0,4 et 0,7 donne généralement les meilleurs résultats. Les nombres supérieurs à 0,1 ont un effet similaire à celui d'une ((invite positive)). Il existe plus de dix chiffres de précision décimale, mais la plupart des gens s'en tiennent à un seul chiffre, et c'est ce que nous recommandons.
LES POIDS DE MODÈLE NÉGATIFS (voir les inversions négatives ci-dessus)
Il est possible d'influencer négativement l'image pour obtenir un effet positif net.
Par exemple, quelqu'un a formé une collection de mains d'IA à l'allure bizarre et l'a chargée en négatif pour créer de belles mains. La solution était très ingénieuse. Vous trouverez de nombreux types d'astuces de qualité comme celle-ci dans notre système. Ils save nous font perdre du temps de taper des choses comme [[mauvaise qualité]] encore et encore. Lorsque vous utilisez un modèle négatif, faites glisser le poids vers le négatif, typiquement -1 ou -2. Cela a un effet similaire à celui d'une [[invite négative]].
Dépannage
Utiliser plusieurs modèles peut être comme jouer plusieurs chansons en même temps : si elles ont toutes le même volume (poids), il est difficile de distinguer quoi que ce soit.
Si l'adresse images apparaît comme trop pixelisée, assurez-vous que vous disposez d'un modèle de base et que votre adresse guidance est réglée sur 7 ou moins, et que vos valeurs positives et négatives ne sont pas trop élevées. Essayez d'ajuster vos poids pour trouver le meilleur équilibre. Pour en savoir plus sur Guidance et les paramètres, consultez le guide ci-dessous.
Paramètres
Résolution : Largeur et hauteur
Les photos du modèle d'IA sont "formées" à une taille spécifique, de sorte que la création de images proche de ces tailles produit les meilleurs résultats. Lorsque nous essayons de prendre des photos trop grandes trop tôt, il peut en résulter des problèmes (jumeaux, membres supplémentaires).
Lignes directrices
Modèles stables de Diffusion XL : Commencez à 1024×1024, et c'est généralement sûr en dessous de 1400×1400.
Stable Diffusion 1.5 a été entraîné à 512×512, les limites supérieures sont donc de 768×768. Quelques modèles avancés comme Photon fonctionneront à 960×576. Plus de conseils sur la taille du SD15
Il est toujours possible d'augmenter l'échelle dans un deuxième temps pour se rapprocher du 4K, voir l'information sur l'upscalerFacelift ci-dessous.
Syntaxe
Vous pouvez facilement modifier la forme d'une image à l'aide de ces commandes abrégées : /portrait /tall /landscape /wide
/render /portrait a gorilla jogging in the park <sdxl>
Vous pouvez également définir manuellement la résolution à l'aide de /size. Par défaut, les projets images sont créés en 512×512. Ces images peuvent être un peu floues, c'est pourquoi la commande size vous permettra d'obtenir un résultat plus clair.
/render /size:768x768 a gorilla jogging in the park <sdxl>
Limites : Stable Diffusion 1.5 est entraîné à 512×512, de sorte qu'une taille trop élevée entraînera des têtes doubles et d'autres mutations. SDXL est entraîné à 1024×1024, donc une taille comme 1200×800 fonctionnera mieux avec un modèle SDXL qu'avec un modèle SD 1.5, car il y aura moins de répétitions probables. Si vous obtenez des sujets en double en utilisant /size , essayez de commencer l'invite avec 1 femme/homme et décrivez l'arrière-plan plus en détail à la fin de l'invite. Pour obtenir 2000×2000 et 4000×4000, utilisez la mise à l'échelle.
Seed
Un nombre arbitraire utilisé pour initialiser le processus de génération d'images. Il ne s'agit pas d'une image spécifique (ce n'est pas comme une photo d'identité dans la base de données), mais plutôt d'un marqueur général. L'objectif de seed est d'aider à répéter une invite d'image. Seed était à l'origine le meilleur moyen de conserver des caractères persistants, mais il a été remplacé par le système Concepts .
Pour répéter une image : les adresses Seed, Guidance, Sampler, Concepts et l'invite doivent être les mêmes. Toute déviation de ces éléments modifiera l'image.
SYNTAX
/render /seed:123456 cats in space
Steps
Le nombre d'itérations que l'IA prend pour refine l'image, avec plus de steps conduisant généralement à une meilleure qualité. Bien entendu, un nombre d'itérations plus élevé se traduit par un traitement plus lent.
/render /steps:25 (((cool))) cats in space, heavens
Le fait de fixer la valeur de steps à 25 correspond à la moyenne. Si vous ne spécifiez pas steps, nous le fixons par défaut à 50, ce qui est élevé. La plage de steps va de 1 à 100 lorsqu'elle est réglée manuellement, et jusqu'à 200 steps lorsqu'elle est utilisée avec un préréglage. Les préréglages sont les suivants :
waymore - 200 steps, deux images - meilleur pour la qualité
plus de -100 steps, trois images
moins - 25 steps, six images
wayless - 15 steps, neuf images! - le meilleur pour les courants d'air
/render /steps:waymore (((cool))) cats in space, heavens
Bien qu'il puisse être tentant de mettre /steps:waymore sur chaque render, cela ne fait que ralentir votre workflow car le temps de calcul est plus long. Augmentez la valeur de steps lorsque vous avez créé votre meilleur message. Sinon, apprenez à utiliser LCM sampler pour obtenir la meilleure qualité images avec le moins de steps. Un trop grand nombre de steps peut également détériorer une image.
EXCEPTIONS
L'ancien conseil était de travailler à partir de 35 steps pour obtenir une bonne qualité, mais ce n'est plus toujours le cas, car les nouveaux modèles à haut rendement peuvent créer une image étonnante avec seulement 4 steps!
Guidance (CFG)
L'échelle Classifier-Free Guidance est un paramètre qui détermine dans quelle mesure l'IA suit l'invite ; des valeurs plus élevées signifient une plus grande adhésion à l'invite.
Lorsque cette valeur est plus élevée, l'image peut paraître plus nette, mais l'IA aura moins de "créativité" pour remplir les espaces, ce qui peut entraîner une pixellisation et des imperfections.
La valeur par défaut la plus sûre est 7 pour les modèles de base les plus courants. Cependant, il existe des modèles spéciaux à haut rendement qui utilisent une échelle différente ( guidance ), expliquée ci-dessous.
SYNTAX
/render <sdxl> [[<fastnegative-xl:-2>]]
/guidance:7
/size:1024x1024
Takoyaki on a plate
Le niveau de réglage du site guidance dépend du site sampler que vous utilisez. Les échantillonneurs sont expliqués ci-dessous. La quantité de steps autorisée pour "résoudre" une image peut également jouer un rôle important.
Exceptions à la règle
Les modèles typiques suivent ce schéma guidance et pas à pas, mais les nouveaux modèles à haut rendement nécessitent beaucoup moins de guidance pour fonctionner de la même manière, entre 1,5 et 2,5. Ceci est expliqué ci-dessous :
Modèles à haut rendement
Faible Steps, Faible Guidance
La plupart des concepts ont besoin d'un guidance de 7 et de 35+ steps pour générer une bonne image. Cette situation est en train de changer avec l'arrivée de modèles plus efficaces.
Ces modèles peuvent créer images en 1/4 de temps, ne nécessitant que 4 à 12 steps avec des guidance inférieurs. Vous pouvez les trouver étiquetés comme Turbo, Hyper, LCM et Lightning dans le système concepts , et ils sont compatibles avec les modèles classiques. Vous pouvez les utiliser avec les Loras et les Inversions de la même famille de modèles. La famille SDXL offre le plus grand choix (utilisez le menu déroulant, tout à droite). Juggernaut 9 Lightining est un choix populaire.
Some of our other favorite Lightning models are <boltning-xl> and <realvis4light-xl> which look great with a guidance of 2, steps between 4-12, and Refiner (no fix) turned off. Polish it off with a good negative like [[<fastnegative-xl:-2>]]. Follow it up with an upscale, and the effects are stunning!
Consultez les notes de ces modèles spéciaux pour plus de détails sur leur utilisation, comme l'Aetherverse-XL (illustré ci-dessous), avec un guidance de 2,5 et 8 steps comme illustré ci-dessous.
VASS (SDXL uniquement)
Vass est un HDR mode pour SDXL, qui peut également améliorer la composition et réduire la saturation des couleurs. Certains le préfèrent, d'autres non. Si l'image semble trop colorée, essayez-la sans Refiner (NoFix).
Le nom vient de Timothy Alexis Vass, un chercheur indépendant qui a exploré l'espace latent SDXL et a fait des observations intéressantes. fait des observations intéressantes. Son objectif est de corriger les couleurs et d'améliorer le contenu de images. Nous avons adapté le code qu'il a publié pour qu'il fonctionne dans PirateDiffusion.
/render a cool cat <sdxl> /vass
Pourquoi et quand l'utiliser : Essayez-le sur SDXL images qui est trop jaune, décentré ou dont la gamme de couleurs semble limitée. Vous devriez constater une meilleure vibration et des arrière-plans plus nets.
Limitations : Cette méthode ne fonctionne qu'avec SDXL.
ANALYSEURS ET POIDS
La partie du logiciel qui ingère votre message est appelée analyseur. L'analyseur a le plus grand impact sur la cohésion de l'invite, c'est-à-dire sur la manière dont l'IA comprend ce que vous essayez d'exprimer et ce à quoi il faut donner la priorité.
PirateDiffusion dispose de trois modes d'analyse : default, LPW et Weights (analyseur "nouveau"). Ils ont tous leurs points forts et leurs inconvénients, et le choix dépend donc de l'adresse style et de ce que vous pensez de la syntaxe.
MODE 1 - ANALYSEUR PAR DÉFAUT (LE PLUS SIMPLE)
L'analyseur par défaut offre le plus de compatibilité et de fonctionnalités, mais ne peut passer que 77 tokens (idées logiques ou parties de mots) avant que Stable Diffusion ne cesse de prêter attention à la longue invite. Pour transmettre ce qui est important, vous pouvez ajouter un renforcement (positif) et [négatif] comme expliqué dans la section ci-dessus (voir positifs). Cela fonctionne avec SD 1.5 et SDXL.
((high quality, masterpiece, masterwork)) A wizard browsing through a magical marketplace with a mystical air around him. He has pointy ears, spectacles perched precariously on his nose, and a wand twirling in hsi hand. His robes are adorned with intricate patterns and patterns of magic dust. There is a bubbling magical cauldron, and mythical creatures peeking around from behind him.
Il s'agit d'un utilitaire de rééquilibrage de l'invite qui permet à la compréhension de l'invite d'aller beaucoup plus loin que 77 tokens, améliorant ainsi la compréhension de l'invite dans son ensemble. Bien entendu, nous en ferions la norme s'il n'y avait pas quelques compromis regrettables :
Limites
Pour obtenir les meilleurs résultats, il est nécessaire d'utiliser une adresse guidance plus basse, de l'ordre de 7 ou moins.
LPW Ne doit pas être combiné avec une incitation positive ou négative très forte.
(((((Cela va casser)))))
[[[[ également cette]]]]
Ne fonctionne pas bien avec Loras ou Inversion concepts
/render /lpw my spoon is too big, ((((big spoon)))) [small spoon], super big, massively big, you would not believe the size, and I've seen many spoons and let me tell you, this spoon in my hand, right here, is yuuuuge, the biggest spoon you'll ever see, and if anyone's said they've seen a bigger spoon, they're cheating, Big spoon, gigantic ladle, extra large serving bowl, oversized utensil, huge portion size, bulky kitchenware, impressive cooking tools, rustic table setting, hearty meals, heavyweight handle, strong grip, stylish design, handcrafted wooden piece, <coma2>
POIDS DES MOTS
PARSER "NEW" AKA PROMPT WEIGHTS
Une autre stratégie pour améliorer la cohésion des messages est d'attribuer un "poids" à chaque mot. La plage de poids est de 0 à 2 en utilisant des décimales, comme pour LoRas. La syntaxe est un peu délicate, mais les poids positifs et négatifs sont pris en charge pour une précision incroyable
Faites particulièrement attention aux négations, qui utilisent une paire de combinaisons [( )] pour exprimer les négations. Dans l'exemple ci-dessus, chat bleu et chien rouge sont les négations. Cette caractéristique ne peut pas être mélangée avec /lpw (ci-dessus).
CLIP SKIP
Cette caractéristique est controversée, car elle est très subjective et les effets varient considérablement d'un modèle à l'autre.
Les modèles d'IA sont constitués de couches et, dans les premières couches, ils contiendraient trop d'informations générales (certains diraient, de la camelote), ce qui donnerait des compositions ennuyeuses ou répétitives.
L'idée derrière Clip Skip est d'ignorer le bruit généré dans ces couches et d'aller directement à la viande.
En théorie, cela permet de renforcer la cohésion et de susciter l'intention. Toutefois, dans la pratique, l'écrêtage d'un trop grand nombre de calques peut donner une mauvaise image. Bien que le jury ne se soit pas encore prononcé sur cette question, un réglage "sûr" très répandu est clipskip 2.
Raffineur (SDXL uniquement)
Le raffineur est une technique de suppression du bruit et de lissage, recommandée pour les peintures et les illustrations. Il crée des images plus lisses avec des couleurs plus nettes. Cependant, c'est parfois le contraire de ce que vous souhaitez. Pour les images réalistes images, la désactivation de l'affineur permet d'obtenir plus de couleurs et de détails, comme le montre l'illustration ci-dessous. Vous pouvez ensuite augmenter l'échelle de l'image pour réduire le bruit et augmenter la résolution.
SYNTAX
/render a cool cat <sdxl> /nofix
Pourquoi et quand l'utiliser ? Lorsque l'image semble trop délavée ou que les couleurs de la peau sont ternes. Ajoutez un post-traitement en utilisant l'une des commandes de réponse (ci-dessous) comme /highdef ou /facelift pour rendre l'image plus soignée.
Échantillonneurs
Un sampler (également appelé programmateur) est un algorithme qui détermine comment l'IA doit résoudre votre demande en fonction des paramètres donnés. Le "meilleur" sampler est très subjectif. Plus d'informations et de comparaisons images
La seule exception est le LCM sampler , qui est spécifiquement utilisé pour le rendu en basse guidance et basse steps.
SAMPLER COMMANDES ET SYNTAXE
Pour obtenir la liste des échantillonneurs disponibles, il suffit de taper /samplers
Les échantillonneurs sont une fonction de réglage très prisée par les amateurs d'intelligence artificielle, et voici ce qu'ils font. Ils sont également appelés "planificateurs de bruit". La quantité de steps et le choix de sampler peuvent avoir un impact important sur une image. Même avec une faible steps, vous pouvez obtenir une image formidable avec notre sampler comme DPM 2++ avec l'option mode "Karras". Voir la page des échantillonneurs pour des comparaisons.
Pour l'utiliser, ajoutez ceci à votre invite
/render /sampler:dpm2m /karras a beautiful woman <sdxl>
Karras est une option de mode qui fonctionne avec 4 échantillonneurs. D'après nos tests, il peut donner des résultats plus agréables.
LCM dans Stable Diffusion signifie Latent Consistency Models (modèles de cohérence latente). Utilisez-le pour obtenir images plus rapidement en l'empilant avec les versions inférieures steps et guidance. Le compromis est la vitesse au détriment de la qualité, bien qu'il puisse produire des images étonnants très rapidement dans de grands lots.
/render /sampler:lcm /guidance:1.5 /steps:6 /images:9 /size:1024x1024 <realvis2-xl> /seed:469498 /nofix Oil painting, oil on board, painted picture Retro fantasy art by Brom by Gerald Brom ((high quality, masterpiece,masterwork)) [[low resolution,m worst quality, blurry, mediocre, bad art, deformed, disfigured, elongated, disproportionate, anatomically incorrect, unrealistic proportions, melted, abstract, surrealism, sloppy, crooked, skull, skulls]] Closeup Portrait A wizard stands in an alien landscape desert wearing wizards robes and a magic hat
Conseils : Lorsque vous utilisez SDXL, ajoutez /nofix pour désactiver le raffineur, cela peut aider à améliorer la qualité, en particulier lors de la réalisation de /more
Il fonctionne avec les modèles SD 1.5 et SDXL. Essayez-le avec guidance entre 2-4 et steps entre 8-12. N'hésitez pas à expérimenter et à partager vos résultats dans le groupe de discussion VIP prompt engineering, qui se trouve dans votre section d'adhésion sur Patreon.
Cela varie selon le modèle, mais même /guidance:1.5 /steps:6 /images:9 donne de bons résultats SDXL en moins de 10 secondes !
Dans l'exemple ci-dessus, le créateur utilise l'outil spécial LCM sampler qui permet d'obtenir des valeurs très basses guidance et très basses steps, tout en créant des valeurs très élevées images. Comparez cette invite avec quelque chose comme : /sampler:dpm2m /karras /guidance:7 /steps:35 Pour aller plus loin, la commande VAE contrôle les couleurs et /nofix désactive le raffineur SDXL. Ces commandes fonctionnent bien avec LCM.
VAE SURVEILLANCE
VAE signifie Variational AutoEncoder, une partie du logiciel qui a une grande influence sur la couleur de l'image. Pour SDXL, il n'existe pour l'instant qu'un seul site fantastique : VAE .
VAE est un type spécial de modèle qui peut être utilisé pour modifier le contraste, la qualité et la saturation des couleurs. Si une image semble trop brumeuse et que votre guidance est réglé sur plus de 10, le VAE pourrait être le coupable. VAE signifie "variational autoencoder" (autoencodeur variationnel) et est une technique qui reclasse images, de la même manière qu'un fichier zip peut compresser et restaurer une image. Le site VAE "réhydrate" l'image sur la base des données auxquelles elle a été exposée, au lieu de valeurs discrètes. Si tous vos rendus images apparaissent désaturés, flous ou avec des taches violettes, changer le VAE est la meilleure solution. (Veuillez également nous en informer afin que nous puissions définir la bonne valeur par défaut). 16 bit VAE fonctionne le plus rapidement.
Syntaxe
/render #sdxlreal a hamster singing in the subway /vae:GraydientPlatformAPI__bright-vae-xl
Options préréglées disponibles sur VAE :
/vae:GraydientPlatformAPI__bright-vae-xl
/vae:GraydientPlatformAPI__sd-vae-ft-ema
/vae:GraydientPlatformAPI__vae-klf8anime2
/vae:GraydientPlatformAPI__vae-blessed2
/vae:GraydientPlatformAPI__vae-anything45
/vae:GraydientPlatformAPI__vae-orange
/vae:GraydientPlatformAPI__vae-pastel
Tiers VAE:
Téléchargez-en un ou trouvez-en un sur le site web de Huggingface avec ce répertoire de dossiers configuré :
Le dossier vae doit présenter les caractéristiques suivantes :
Une seule adresse VAE par dossier, dans un dossier de premier niveau d'un profil Huggingface, comme indiqué ci-dessus.
Le dossier doit contenir un fichier config.json
Le fichier doit être au format .bin
Le fichier bin doit être nommé "diffusion_pytorch_model.bin"
Où en trouver d'autres : Huggingface et Civitai peuvent en avoir d'autres, mais ils doivent être convertis au format ci-dessus.
Pour le SD15, nous avons de nombreuses options en stock. Voici l'avis non scientifique d'une personne sur les différences :
kofi2 - très coloré et saturé
blessed2 - moins saturé que kofi2
anything45 - moins saturé que blessed2
orange - saturation moyenne, vert vif
pastel - couleurs vives, comme les vieux maîtres hollandais
ft-mse-840000-ema-pruned - pour plus de réalisme
Dépannage : Certains sites VAE sont incompatibles avec certains modèles de base. Il en résulte deux problèmes : des fuites de lumière vert fluo (ou) un carré noir, essayez donc un autre VAE si cela se produit.
Projets
Vous pouvez render images directement dans les dossiers de projet dans l'WebUI unifiée et dans PirateDiffusion Telegram.
Telegram et méthode API :
/render my cool prompt /project:xyz
Méthode Web :
Tout d'abord, render une image pour lancer votre projet dans votre @piratediffusion_bot
Continuez jusqu'à la fin de ce guide pour les commandes liées à /projet.
ControlNet via PirateDiffusion
Les ControlNets sont des pochoirs d'image à image pour guider l'image finale. Croyez-le ou non, vous pouvez utiliser Controlnet en mode natif dans Telegram, sans navigateur, bien que nous prenions en charge les deux.
Vous pouvez fournir une image de départ comme pochoir, choisir un mode, et changer l'apparence de cette image source avec une invite positive et négative. Vous pouvez control l'effet avec le curseur de poids. Les entrées images entre 768×768 ou 1400×1400 sont les plus efficaces.
À l'heure actuelle, les modes pris en charge sont les suivants : contours, profondeur, arêtes, mains, pose, référence, segment, squelette et facepush, chacun ayant des paramètres enfant. Plus d'exemples
Visualisation des préréglages enregistrés sur controlnet
/control
Créer un préréglage ControlNet
Tout d'abord, téléchargez une image. Ensuite, "répondez" à cette image avec cette commande, en lui donnant un nom comme "myfavoriteguy2"
/control /new:myfavoriteguy2
Les controlnets sont sensibles à la résolution, ils répondront donc avec la résolution de l'image dans le nom. Ainsi, si je télécharge une photo de Will Smith, le robot répondra will-smith-1000×1000 ou toute autre taille d'image. Cela vous aidera à vous souvenir de la taille de l'image à cibler ultérieurement.
Rappel d'un préréglage ControlNet
Si vous avez oublié ce que fait votre preset, utilisez la commande show pour les voir : /control ou pour voir un preset spécifique :
/control /show:myfavoriteguy2
Utilisation des modes ControlNet
Le (nouveau) paramètre abrégé pour control guidance est /cg:0.1-2 - contrôle le degré d'adhérence de render à une controlnet mode donnée. Le point idéal est 0,1-0,5. Vous pouvez également l'écrire à l'ancienne sous la forme /controlguidance:1
Échange de visages
L'échange de visages est également disponible en tant que commande de réponse. Vous pouvez également utiliser ce faceswap pratique (roop, insightface) pour changer les visages d'une photo téléchargée. Créez d'abord le site control pour l'image, puis ajoutez une deuxième image pour échanger les visages.
En tant que commande de réponse (clic droit sur une image finie, à partir de n'importe quel modèle)
/faceswap myfavoriteguy2
facelift prend également en charge le paramètre /strength , mais son fonctionnement n'est pas celui auquel vous vous attendez :
/faceswap /strength:0.5 myfavoriteguy2
Si vous mettez un /strength inférieur à 1, il y aura *blend* l'"image avant" avec l'"image après" - littéralement blend les deux, comme dans photoshop avec une opacité de 50% (si la force était de 0.5). La raison en est que l'algorithme sous-jacent n'a pas de paramètre de "force" comme on pourrait s'y attendre, et c'était donc notre seule option.
Visages poussés
L'échange de visages (expliqué ci-dessus), mais en tant que commande render-time, est appelé "poussée de visages"
Vous pouvez également utiliser notre technologie FaceSwap d'une certaine manière (similaire à LoRa), mais il s'agit simplement d'un moyen de gagner du temps pour créer un échange de visage. Il n'y a pas de poids ou de grande flexibilité, il trouvera tous les visages réalistes dans un nouveau render et échangera le images contre un visage. Utilisez les mêmes noms de presets ControlNet pour l'utiliser.
/render a man eating a sandwich /facepush:myfavoriteguy2
Facepush Limites
Facepush ne fonctionne qu'avec les modèles Stable Diffusion 1.5 comme et le point de contrôle doit être réaliste. Elle ne fonctionne pas avec les modèles SDXL et peut ne pas fonctionner avec la commande /more ou certaines résolutions élevées. Cette fonctionnalité est expérimentale. Si vous avez des problèmes avec /facepush , essayez de rendre votre invite, puis faites /faceswap sur l'image. Vous saurez si l'image n'est pas assez réaliste. Ce problème peut parfois être résolu en appliquant une commande /facelift pour rendre la cible plus nette. /more et /remix ne fonctionnent pas (encore) comme prévu.
Outils haut de gamme (divers)
Augmenter le nombre de pixels et de détails
Augmentez les détails d'une image par 4, et supprimez les lignes et les imperfections des photos, à l'instar de la fonction "beauté" mode sur les appareils photo des smartphones. Modes pour photos réalistes et œuvres d'art. Plus d'informations
HAUTE DÉFINITION
La commande HighDef (également connue sous le nom de High Res Fix) est un doubleur de pixels rapide. Il suffit de répondre à l'image pour l'agrandir.
/highdef
La commande highdef n'a pas de paramètres, car la commande /more peut faire ce que fait HighDef et plus encore. Ceci est simplement là pour vous faciliter la tâche. Pour les pros qui veulent en savoir plus sur control, remontez vers le haut et regardez la vidéo tutorielle /more .
Après avoir utilisé la commande /highdef ou /more , vous pouvez procéder à une nouvelle mise à l'échelle, comme expliqué ci-dessous.
UPSCALERS
Facelift est destiné à la réalisation de portraits réalistes.
Vous pouvez utiliser /strength entre 0,1 et 1 pour control l'effet. La valeur par défaut est 1 si elle n'est pas spécifiée.
/facelift
La commande /facelift vous permet également d'accéder à notre bibliothèque d'upscalers. Ajoutez ces paramètres pour control l'effet :
Facelift est un convertisseur de phase 2. Vous devez d'abord utiliser HighDef avant d'utiliser Facelift. Il s'agit de la commande générale de mise à l'échelle, qui a deux effets : elle augmente les détails des visages et multiplie par quatre les pixels. Son fonctionnement est similaire à celui de beauty mode sur votre smartphone, ce qui signifie qu'elle peut parfois sabler les visages, en particulier les illustrations. Heureusement, il existe d'autres modes de fonctionnement :
/facelift /photo
Cette option désactive la retouche du visage et convient bien aux paysages ou aux portraits naturels.
/facelift /anime
Malgré son nom, il n'est pas réservé à anime - utilisez-le pour booster vos illustrations.
/facelift /size:2000x2000
Limites : Facelift essaiera de 4x votre image, jusqu'à 4000×4000. Telegram n'autorise généralement pas cette taille, et si votre image est déjà en haute définition, essayer de la multiplier par 4 risque d'épuiser la mémoire. Si l'image est trop grande et ne revient pas, essayez de la récupérer en tapant /history pour l'extraire de l'interface web, car Telegram a des limites de taille de fichier. Vous pouvez également utiliser le paramètre size comme indiqué ci-dessus pour utiliser moins de mémoire vive lors de l'agrandissement.
REFINE
Refine est pour les fois où vous voulez éditer votre texte en dehors de Telegram et dans votre navigateur web. C'est une question de qualité de vie.
Votre abonnement comprend à la fois Telegram et Stable2go WebUI. La commande refine vous permet de passer de Telegram à l'interface web. C'est pratique pour modifier rapidement du texte dans votre navigateur web, au lieu de faire un copier/coller.
/refine
Le site WebUI se lancera dans Brew mode par défaut. Cliquez sur "Avancé" pour passer à Render.
Remix outil
Transformations d'image à image
L'outil remix est magique. Une image téléchargée ou rendue peut être transformée dans l'art style d'un concept avec l'outil Remix . Vous pouvez également utiliser des photos d'entrée comme images de référence pour changer radicalement de sujet.
SYNTAX
Remix est la commande de transfert d'image à image style , également connue sous le nom de commande de re-promptage.
Remix nécessite une image en entrée, et détruira chaque pixel de l'image pour en créer une entièrement nouvelle. Elle est similaire à la commande /more , mais vous pouvez lui transmettre un autre nom de modèle et une invite à modifier l'art style de l'image.
Remix est la deuxième commande de "réponse" la plus populaire. Répondez littéralement à une photo comme si vous alliez lui parler, puis entrez la commande. Cet exemple fait basculer l'art style que vous avez utilisé au départ dans le modèle de base appelé Niveau 4.
/remix a portrait <level4>
Vous pouvez utiliser vos photos téléchargées avec /remix et elles seront complètement modifiées. Pour préserver les pixels (ne pas modifier le visage, par exemple), envisagez plutôt de dessiner un masque à l'aide de Inpaint.
Utilisations : Style Transfert et création "haut de gamme
Vous pouvez également utiliser l'outil remix pour réinterpréter des photos de faible résolution images en quelque chose de nouveau, par exemple en transformant des photos de jeux vidéo de faible résolution en une image réaliste moderne images, ou en vous transformant en caricature ou en illustration anime . Cette vidéo vous montre comment faire :
Plus d'outils (commande de réponse)
L'outil Plus permet de créer des variations de la même image
Pour voir le même sujet dans des variations légèrement différentes, utilisez l'outil "plus".
Ce qui se passe sous le capot : La valeur de seed augmente et celle de guidance est aléatoire, tout en conservant l'invite d'origine. Limites : Il se peut que guidance soit surchargé lors de l'utilisation de modèles efficaces.
Pour en savoir plus, répondez littéralement à une image en cliquant avec le bouton droit de la souris, comme si vous parliez à une personne. Les commandes de réponse permettent de manipuler images et d'inspecter les informations, comme IMG2IMG ou la recherche de l'invite d'origine.
PLUS DE SYNTAX
more est la commande Reply la plus courante. Elle vous renvoie une image similaire à images lorsque vous répondez à une image déjà générée par une invite. La commande /more ne fonctionne pas sur une image téléchargée.
/more
La commande more est plus puissante qu'il n'y paraît. Elle accepte également Strength, Guidance, et Size, ce qui vous permet de l'utiliser également comme upscaler de seconde phase, particulièrement utile pour les modèles Stable Diffusion 1.5. Consultez ce tutoriel vidéo pour la maîtriser.
Outil d'incrustation
AKA Remplissage génératif
Inpainting est un outil de masquage qui vous permet de dessiner un masque autour d'une zone et d'y inviter quelque chose de nouveau, ou de supprimer l'objet comme une gomme magique. L'outil inpaint dispose de sa propre boîte d'invite positive et négative, qui accepte également les codes de déclenchement pour concepts.
Note : Notre logiciel a été mis à jour depuis cette vidéo, mais les mêmes principes s'appliquent toujours.
REMPLISSAGE GÉNÉRATIF, ALIAS INPAINTING
Inpaint est utile pour modifier une zone ponctuelle d'une photo. Contrairement à After Detailer, l'outil inpaint vous permet de sélectionner et de masquer la zone que vous souhaitez modifier.
Cet outil possède une interface graphique - il est intégré à Stable2go. Inpaint ouvre un navigateur web dans lequel vous pouvez littéralement peindre sur l'image, en créant une zone masquée qui peut faire l'objet d'une invite. Il est possible de peindre sur une photo non IA téléchargée (changer les mains, le ciel, la coupe de cheveux, les vêtements, etc.) ainsi que sur une photo IA images.
/inpaint lucioles qui bourdonnent la nuit
Dans l'interface graphique, il existe des styles artistiques spéciaux et spécifiques (inpaint models) disponibles dans le menu déroulant de cet outil, n'oubliez donc pas d'en sélectionner un. . Utilisez strength et guidance pour control l'effet, où Strength se réfère à votre inpaint invite seulement.
/inpaint /size:512x768 /strength:1 /guidance:7 fireflies at (night)
Conseil : la taille sera héritée de l'image originale, et il est recommandé d'utiliser une taille de 512×768. Il est recommandé de spécifier une taille, sinon la valeur par défaut est 512×512, ce qui risque d'écraser l'image. Si une personne est éloignée dans l'image, son visage peut changer, à moins que l'image ne soit plus fidèle.
Vous pouvez également inverser inpaint, par exemple en utilisant d'abord la commande /bg pour supprimer automatiquement l'arrière-plan d'une image, puis en demandant de changer l'arrière-plan. Pour ce faire, copiez l'ID du masque à partir des résultats de /bg . Utilisez ensuite la propriété /maskinvert
/inpaint /mask :IAKdybW /maskinvert une vue majestueuse du ciel nocturne avec des planètes et des comètes qui défilent.
OUTPAINT AKA CANVAS ZOOM ET PANNING
DERNIÈRE VERSION (FLUX)
Développe n'importe quelle image en utilisant les mêmes règles que inpaint, mais sans interface graphique, de sorte que nous devons spécifier un mot déclencheur pour savoir quel type d'art style doit être utilisé. Vous pouvez spécifier la direction dans laquelle il va avec une valeur d'emplacement
/workflow /run:zoomout-flux fireflies at night
DIRECTIONNEL CONTROL
Vous pouvez ajouter du rembourrage en utilisant les valeurs des emplacements, dans le sens inverse des aiguilles d'une montre. Ainsi, slot1 = TOP
/workflow /run:zoomout-flux fireflies at night /slot1:200 /slot2:50 /slot3:100 /slot4:300
ANCIENNES VERSIONS (SDXL)
Développez n'importe quelle image en utilisant les mêmes règles que inpaint, mais sans interface graphique, de sorte que nous devons spécifier un mot déclencheur pour le type d'art style à utiliser. Les mêmes modèles inpaint sont utilisés pour l'outpainting. Apprenez les noms en parcourant la page des modèles ou en utilisant
Vous pouvez vérifier quels modèles sont disponibles avec /concept /inpainting
/outpaint fireflies at night <sdxl-inpainting>
Outpaint dispose de paramètres supplémentaires. Utilisez top, right, bottom et left pour control la direction dans laquelle la toile doit s'étendre. Si vous omettez le côté, la toile s'étendra uniformément dans les quatre directions. Vous pouvez également ajouter un arrière-plan blur bokeh (1-100), le facteur zoom (1-12) et la contraction de la zone d'origine (0-256). Ajoutez de la force pour la faire régner.
/outpaint /side:top /blur:10 /zoom:6 /contract:50 /strength:1 the moon is exploding, fireworks <sdxl-inpainting>
Paramètres facultatifs
/side:bottom/top/left/right - vous pouvez spécifier une direction pour développer votre image ou aller dans les quatre en même temps si vous n'ajoutez pas cette commande.
/blur:1-100 - estompe le bord entre la zone originale et la zone nouvellement ajoutée.
/zoom:1-12 - affecte l'échelle de l'ensemble de l'image, par défaut elle est fixée à 4.
/contract:0-256 - réduit la taille de la zone originale par rapport à la zone peinte. Par défaut, il est fixé à 64.
CONSEIL : pour de meilleurs résultats, modifiez vos messages-guides pour chaque utilisation de outpaint et n'incluez que les éléments que vous souhaitez voir dans la nouvelle zone étendue. La copie d'invites originales ne fonctionne pas toujours comme prévu.
Supprimer l'outil BG
Zapping d'arrière-plan rapide comme l'éclair
L'outil de suppression de l'arrière-plan est une solution facile, en une seule étape, pour éliminer tout ce qui se trouve derrière le sujet. Images à 800×800 environ est la meilleure solution. Vous pouvez également utiliser l'outil d'incrustation (ci-dessus) pour masquer et mettre en place un nouvel arrière-plan.
COMMANDES DE SUPPRESSION DE L'ARRIÈRE-PLAN
Pour supprimer un arrière-plan réaliste, il suffit de lui répondre par /bg
/bg
Pour les illustrations de toutes sortes, ajoutez ce paramètre anime et l'enlèvement sera plus net.
/bg /anime
Vous pouvez également ajouter le paramètre PNG pour download une image non compressée. Il renvoie par défaut un JPG haute résolution.
/bg /format:png
Vous pouvez également utiliser une valeur de couleur hexagonale pour spécifier la couleur de l'arrière-plan
/bg /anime /format:png /color:FF4433
Vous pouvez également download le masque séparément
/bg /masques
Astuce : Que puis-je faire avec le masque ? Ne faire apparaître que l'arrière-plan ! Cela ne peut cependant pas se faire en une seule étape. Répondez d'abord au masque avec /showprompt pour obtenir le code de l'image que nous utilisons pour l'inpainting, ou choisissez-le parmi les masques inpainting récents. Ajoutez /maskinvert à l'arrière-plan au lieu de l'avant-plan lorsque vous faites un render.
Répondez à la photo d'arrière-plan avec /control /new :Chambre à coucher (ou toute autre pièce/zone)
Télécharger ou render l'image cible, la deuxième image qui recevra l'arrière-plan stocké.
Répondre à la cible avec /bg /replace:Bedroom /blur:10
Le paramètre blur est compris entre 0 et 255, ce qui permet de contrôler l'adoucissement entre le sujet et l'arrière-plan. Le remplacement de l'arrière-plan fonctionne mieux lorsque l'ensemble du sujet est visible, ce qui signifie que certaines parties du corps ou de l'objet ne sont pas obstruées par un autre objet. Cela empêche l'image de flotter ou de créer un arrière-plan irréaliste.
FAIRE TOURNER UN OBJET
Vous pouvez faire pivoter n'importe quelle image, comme s'il s'agissait d'un objet en 3D. Cela fonctionne beaucoup mieux après avoir supprimé l'arrière-plan à l'aide de la fonction /bg
/spin
L'essorage fonctionne mieux lorsque l'arrière-plan est supprimé. La commande spin prend en charge /guidance. Notre système choisit au hasard une adresse guidance 2 - 10. Pour plus de détails, ajoutez également /steps:100
DÉCRIRE UNE PHOTO
Mise à jour ! Il existe maintenant deux modes de description : CLIP et FLORENCE2
Générez une invite à partir de n'importe quelle image grâce à la vision par ordinateur avec Describe ! Il s'agit d'une commande de type "réponse", donc faites un clic droit sur l'image comme si vous alliez lui parler, et écrivez
/describe /florence
Le paramètre supplémentaire Florence permet d'obtenir une invite beaucoup plus détaillée. Il utilise le nouveau modèle de vision artificielle Florence2. /describe utilise le modèle CLIP.
Exemple
Lancer des widgets dans PirateDiffusion
Vous pouvez créer des boutons prédéfinis pour faciliter la création de boutons-poussoirs, sans apprendre à coder. Cela est possible grâce à notre système de widgets. Il vous suffit de remplir une feuille de calcul avec vos modèles d'invite et de la connecter à votre robot. Par exemple, nous fournissons un modèle pour un personnage faisant widget:
Les widgets créent à la fois un Telegram et un WebUI , pour que vous puissiez profiter des deux ! Regarder une vidéo sur les widgets et download le modèle pour commencer à construire. Aucun codage n'est nécessaire !
Gestion des fichiers et des files d'attente
ANNULER
Utilisez /cancel pour interrompre ce que vous êtes en train de rendre
/cancel
DOWNLOAD
Les images que vous voyez dans Telegram utilisent le compresseur d'images intégré à Telegram. Il limite la taille du fichier. Pour contourner Telegram, répondez à votre image par /download pour obtenir une image RAW non compressée.
/download
Si le site download demande une adresse password, voir la section Partage de galerie privée et mots de passe de cette antisèche.
DELETE
Il y a deux façons de supprimer images: localement depuis votre appareil, ou à jamais depuis votre Cloud Drive.
Pour supprimer images de votre appareil local tout en les conservant sur le Cloud Drive, utilisez la fonction de suppression intégrée de Telegram. Appuyez longuement sur une image (ou cliquez avec le bouton droit de la souris sur l'image à partir d'un ordinateur) et choisissez de la supprimer.
Répondez à une image avec /delete pour l'effacer de votre disque dur.
/delete
Vous pouvez également taper /webui et lancer notre gestionnaire de fichiers, et utiliser la commande organize pour supprimer par lots images en une seule fois.
HISTOIRE
Affiche la liste des messages que vous avez récemment créés sur images, dans le canal Telegram en question. Lorsqu'il est utilisé dans des groupes publics, il n'affiche que images que vous avez déjà créé dans ce canal public uniquement, de sorte que /history est également sensible à votre vie privée.
/history
SHOWPROMPT & COMPARER
Pour voir l'invite d'une image, cliquez dessus avec le bouton droit de la souris et tapez /showprompt
/showprompt
Cette commande pratique vous permet de vérifier comment une image a été créée. Elle vous indique la dernière action effectuée sur l'image. Pour voir l'historique complet, écrivez la commande comme suit : /showprompt /history
Un outil de comparaison d'images est intégré à la sortie de showprompt . Cliquez sur ce lien et l'outil s'ouvrira dans le navigateur.
DÉCRIRE (CLIP)
La commande /showprompt vous donnera l'invite exacte d'une image IA, mais qu'en est-il des images non IA images?
Notre commande /describe utilise des techniques de vision artificielle pour rédiger un message à propos de n'importe quelle photo que vous avez téléchargée.
/describe
Le langage utilisé par /describe peut parfois être curieux. Par exemple, "arafed" signifie une personne amusante ou vivante.
PNG
Par défaut, PirateDiffusion crée images en JPG presque sans perte. Vous pouvez également créer images sous forme de PNG à plus haute résolution au lieu de JPG. Attention : Cette méthode utilise 5 à 10 fois plus d'espace de stockage. Cependant, il y a un problème. Telegram n'affiche pas les fichiers PNG de manière native. Une fois le fichier PNG créé, vous devez utiliser la commande /download (ci-dessus) pour l'afficher.
/render a cool cat #everythingbad /format:png
VECTOR
IMAGE VERS SVG / VECTEUR ! Répondez à une image générée ou téléchargée pour trace la transformer en vecteurs, plus précisément en SVG. Vecteurs images qui peuvent être zoomés à l'infini puisqu'ils ne sont pas rendus avec des pixels tramés comme images; vous avez donc des bords nets et clairs. Idéal pour l'impression, les produits, etc. Utilisez la commande /bg si vous créez un logo ou un autocollant.
/trace
Toutes les options disponibles sont énumérées ci-dessous. Nous ne connaissons pas encore les options facultatives, alors aidez-nous à trouver une bonne option par défaut en nous faisant part de vos observations dans le chat VIP.
speckle - nombre entier - valeur par défaut 4 - plage 1 ... 128 - écarte les patchs dont la taille est inférieure à X px
color - default - couleur de l'image
bw - rend l'image en noir et blanc
mode - polygone, spline, ou aucune - spline par défaut - Ajustement du curseur mode
precision - nombre entier - valeur par défaut 6 - plage 1 ... 8 - Nombre de bits significatifs à utiliser dans un canal RVB - c.-à-d. plus de fidélité des couleurs au prix d'un plus grand nombre de "taches"
gradient - nombre entier - valeur par défaut 16 - plage 1 ..128 - Différence de couleur entre les couches gradient
corner - nombre entier - valeur par défaut 60 - plage 1 ... 180 - Angle momentané minimal (degré) à considérer comme un angle d'attaque. corner
length - nombre à virgule flottante - valeur par défaut 4 - plage 3,5 ... 10 - Effectue une subdivision itérative lisse jusqu'à ce que tous les segments soient plus courts que cette valeur. length
Exemple trace avec des paramètres optionnels affinés :
/trace /color /gradient:32 /corner:1
GESTIONNAIRE DE FICHIERS WEB UI
Pratique pour gérer vos fichiers dans un navigateur et consulter rapidement une liste visuelle de modèles.
/webui
Consultez la section des comptes en haut de cette page pour des choses comme les commandes password .
RENDER PROGRÈS MONITOR
Inévitablement, Telegram a des problèmes de connexion de temps en temps. Si vous voulez savoir si nos serveurs envoient bien l'adresse images , mais pas à Telegram, utilisez cette commande. Vous pouvez render et récupérer votre images sur Cloud Drive.
/monitor
Si /monitor ne fonctionne pas, essayez /start. Cela donnera un coup de pouce au robot.
PING
"Nous sommes en panne, Telegram est en panne ou la file d'attente m'a oublié ? /ping tente de répondre à toutes ces questions en un coup d'œil
/ping
Si /ping ne fonctionne pas, essayez /start. Cela donnera un coup de pouce au robot.
SETTINGS
Vous pouvez modifier la configuration par défaut de votre robot, par exemple en ne sélectionnant qu'une adresse sampler, steps, et une option très utile : mettre votre modèle de base préféré à la place de Stable Diffusion 1.5.
/settings
Disponible settings: /settings /concept:none /settings /guidance:random /settings /style:none /settings /sampler:random /settings /steps:default /settings /silent:off Prêtez attention aux messages d'état lorsque vous modifiez un paramètre, car ils vous indiquent comment revenir en arrière. Parfois, le retour en arrière nécessite les paramètres off, none ou default Avant de modifier les paramètres par défaut, vous pouvez souhaiter save les modifier en tant que chargement, comme expliqué ci-dessous, afin de pouvoir revenir en arrière si vous n'êtes pas satisfait de votre configuration et que vous souhaitez recommencer.
CHARGES
La commande /settings affiche également vos chargements au bas de la réponse.
Facilitez le passage d'un flux de travail à l'autre en sauvegardant les chargements. Par exemple, vous pouvez avoir un modèle de base préféré et sampler pour anime, et un autre pour le réalisme, ou une autre settings pour un projet ou un client spécifique. Les chargements vous permettent de remplacer tous vos settings en un clin d'œil.
Par exemple, si je veux save mon settings tel quel, je peux inventer un nom comme Morgan's Presets Feb 14 :
/settings /save:morgans-presets-feb14
Gérez vos chargements : Save current settings: /settings /save:coolset1 Afficher l'état actuel settings: /settings /show:coolset1 Récupérer un paramètre : /settings /load:coolset1
SILENT MODE
Les messages de débogage, comme la confirmation de la répétition de l'invite, sont-ils trop longs ? Vous pouvez rendre le robot complètement silent grâce à cette fonction. N'oubliez pas que vous l'avez activée, sinon vous penserez que le robot vous ignore, car il ne vous indiquera même pas l'heure estimée de render ni aucune confirmation !
/settings /silent:on
Pour le réactiver, il suffit de remplacer ON par OFF.
Déclassé et expérimental
Il s'agit d'une collection d'expériences et les anciennes commandes sont toujours supportées, mais ont été remplacées par des techniques plus récentes. Elles sont difficiles à recommander pour la production, mais restent amusantes à utiliser.
NOTATION DE L'ESTHÉTIQUE
Esthétique est une option expérimentale qui permet d'activer un modèle d'évaluation esthétique sur une image rendue, dans le cadre du processus de rendu. Cette option est également disponible dans l'API Graydient .
Ces modèles d'apprentissage automatique tentent d'évaluer la qualité visuelle / la beauté d'une image de manière numérique.
/render a cool cat <sdxl> /aesthetics
Il renvoie une note d'esthétique ("beauté") de 1 à 10 et une note d'artefacts de 1 à 5 (la note la plus basse étant la meilleure). Pour voir ce qui est considéré comme bon ou mauvais, voici l'ensemble des données. La note peut également être consultée dans /showprompt
BREW
Brew a été remplacé par /polly. (il permettait d'ajouter des effets aléatoires)
/brew un chien cool = /polly un chien cool
Le résultat est le même.
MEME
Nous l'avons ajouté à titre de plaisanterie, mais il fonctionne toujours et est tout à fait hilarant. Vous pouvez ajouter le texte de la police Internet Huge IMPACT en haut et en bas de votre image, une section à la fois.
/meme /top:On ne peut pas simplement
(tour suivant)
/meme /bottom:Entrer dans le Mordor
INSTRUCTURE PIX 2 PIX
Remplacé par : Inpaint La peinture, la peinture extérieure, et Remix
C'était le truc à la mode à l'époque, une technologie appelée Instruct Pix2Pix, la commande /edit. Répondre à une photo comme celle-ci :
/modifier ajouter des feux d'artifice dans le ciel
Posez des questions du type "que se passerait-il si" à style pour images des paysages et de la nature, en langage naturel pour voir les changements. Bien que cette technologie soit intéressante, Instruct Pix2Pix produit des résultats de faible résolution, il est donc difficile de la recommander. Elle est également verrouillée sur son propre art style, et n'est donc pas compatible avec nos concepts, loras, embeddings, etc. Il est verrouillé à une résolution de 512×512. Si vous travaillez sur des lewds ou anime, ce n'est pas le bon outil pour le travail. Utilisez plutôt /remix . Vous pouvez également control l'effet avec un paramètre de force
/edit /strength:0.5 Et si les bâtiments sont en feu ?
STYLES
Les styles ont été remplacés par le système de recettes, plus puissant. Les styles sont utilisés pour créer des raccourcis personnels qui ne sont pas destinés à être partagés. Vous pouvez échanger des styles avec une autre personne à l'aide de la commande de copie, mais ils ne fonctionneront pas si vous ne connaissez pas ces codes. Nos utilisateurs ont trouvé cela déroutant, c'est pourquoi les recettes sont globales. Pour découvrir cette fonctionnalité, tapez :