統一WebUI 操作ガイド
![]()
概要
Unified Web Editor (旧Stable2go)は、Graydient's originalWebUI for creating AIimages, preloaded with popular open source AI models from ourcommunity.他のサービスとは異なり、「トークン」や「クレジット」は必要ありません。他のGraydient ツールと同様、Unified は無制限に使用でき、ロイヤリティ・フリーです。現在では、Fluxのように、多くのモデル・ファミリーをサポートしているため、名称を変更しました。
これらのモデルは何テラバイトものストレージと専用のグラフィック・アダプタを必要とするが、Graydient 、ウェブ上であればどこでも動作する。 Unifiedはすべてのデバイスで高速に動作し、ファイルはGraydient クラウド上で同期されます。
現在、FLUX と Stable Diffusion 3.5 のモデルが100以上用意されており、画像ごとに料金が発生しないので、無制限に楽しむことができます。 FLUX ビデオチュートリアル
新着情報:ビデオ
新しい ワークフローを追加しました!ワークフローは「タスク」メニューの画像アップロードボタンとネガティブプロンプトのすぐ下にあります。
ビデオワークフロー
テキストからビデオへの変換、画像からビデオへの変換もサポートしています。
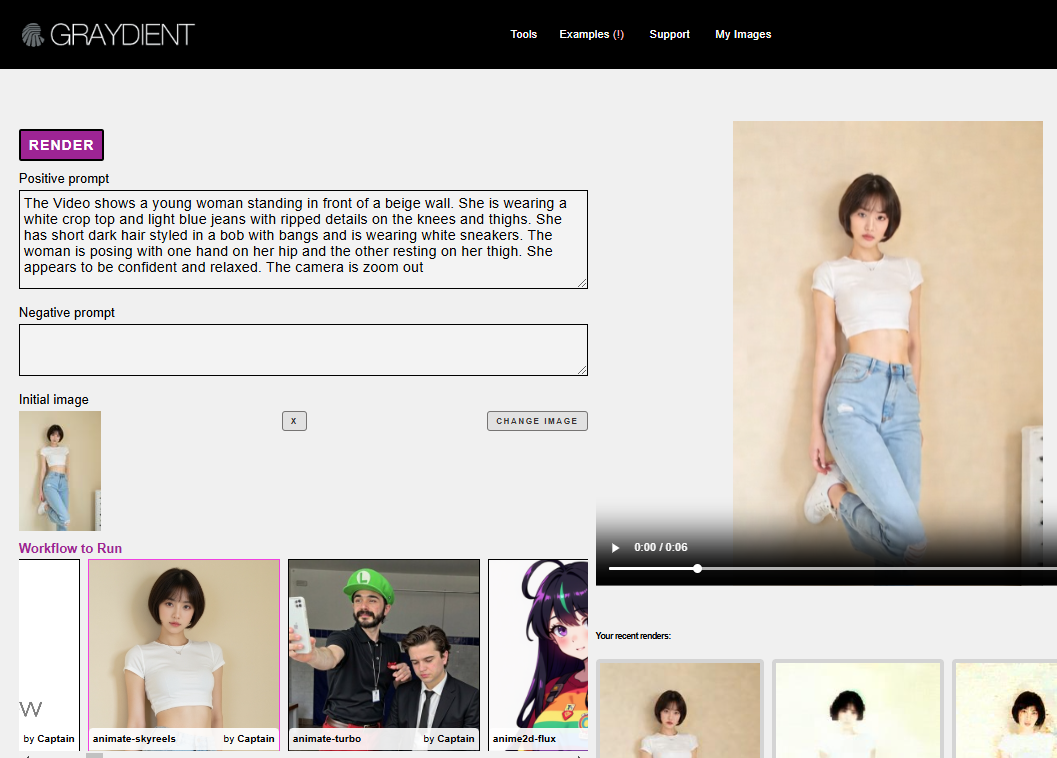
例えば、写真をビデオにすることができます。 その方法を紹介しよう:
- ユニファイド・エディターをクリック
- タスク>ワークフローをクリックし、アニメート・スカイリールを選択します(これが最新で、他にもあります)。
- プロンプトボックスの下にある「Initial Photo」と書かれたところに写真をアップロードしてください。
- そして、あなたのプロンプトを入力してください。 ビデオは2分以内に生成されます。
写真を必要としないTEXT-TO-VIDEOワークフローもある。
LTXとHUNYUANのビデオワークフローから選択し、communityHunYuan Loraライブラリからconcepts 追加することができます。
イメージワークフロー
ビデオと同じように、ワークフロー・エリアをクリックして作成を開始します。例えば、AIを使ってシームレスな繰り返しパターンを作る方法を学ぶことができます。これは、システムにある数多くのワークフローのほんの一例です。
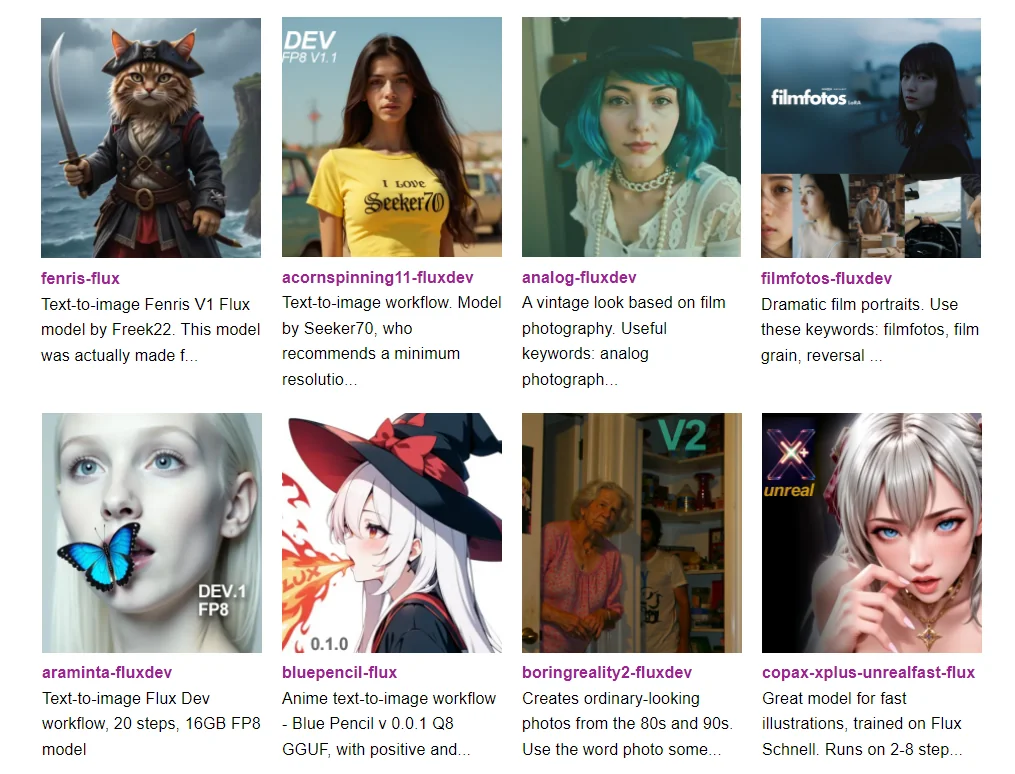
ワークフローは初心者向け
シンプルなプロンプトから始め、1024×1024で一度に2つのimages 。

concepts システムはプロのために設計されている。
workflow から始める代わりに、ゼロから始めることもできる。concepts 、あなたが望むものを正確に得るためには、 システムの仕組みを完全に理解する必要があるので、これはちょっとしたウサギの穴です。この方法はより技術的ですが、より多くのパワーとcontrol を得ることができます。 Graydient ダッシュボードのインスピレーションセクションにある人気のプロンプトを編集することから始めることをお勧めします。
10,000以上のモデルがプリロードされており、起動に時間がかからない
毎週、新しいモデルを導入して います。concepts システムには、私たちのcommunity やウェブ上のあらゆるところから、訓練されたオリジナルのモデルが満載です。
プロンプトとは、AIにどのような画像を生成するかを指示する完全な記述である:
- リアルであるべき?アートワークの一種?
- 時間帯、視点、照明を描写する
- 被写体とその行動をよく描写する
- 最後に場所とその他の詳細を記述する
基本的な例:
映画のようなリアルな写真、ボサボサの犬が愚かな帽子をかぶって見る人を見ている、歩道の風景、ニューヨークのダウンタウン、タイムズスクエア、幸せ、ボケの背景、被写界深度、高画質、フィルムグレイン

ポジティブなプロンプト
ポジティブ・プロンプトとネガティブ・プロンプトは、私たちが見たいものと見たくないものをAIに伝える言葉だ。人間は通常、このような二項対立の形ではコミュニケーションをとらないが、非常に騒がしい環境では、"これはダメだけど、あれはダメ!"と言うかもしれない。
ポジティブ澄んだ青い砂浜、ヤシの木がある昼間のビーチシーン
否定的: 人、ボート、ビキニ、NSFW
Stable2goエディターの2つのボックスにこのように入力します:

ポジティブなプロンプトには画像の主題とそれを支える詳細が含まれる。芸術style 、周囲の環境、美学への期待などを説明するのに役立つ。. 例
- 最高品質のリアルな子犬の写真
- ひまわりの傑作デッサン、ボケの背景
- 車道のスクーターのローアングル写真、水彩画
- /トルトゥーガをビールと一緒に*」と訳す。
- ビールと亀

Concepts
Concepts は、プロンプトだけではよく理解できない特定の事柄を生成する特殊なAIモデルである。複数のconcepts :通常、1つのベースモデルと1~3つのLoRasまたはInversionsを使用するのが一般的です。

モデルファミリー
当社のソフトウェアは、現在2つのStable Diffusionファミリーをサポートしています:SD15(古いモデルで、512×512でトレーニングされています)とStable Diffusion XL(ネイティブで1024×1024です)です。 これらの解像度に近づけることで、最良の結果を得ることができます。
最も注意しなければならないのは、ファミリーは互いに互換性がないということだ。SDXLベースはSD15ローラには使用できませんし、その逆も同様です。

種類Concepts
ベースモデルは「フルモデル」とも呼ばれ、画像のstyle を最も強く決定します。LoRasとTextual Inversionsは、微調整用の小さなモデルです。これらは1つの被写体、通常は人物やポーズに特化した小さなファイルです。インペイントモデルは、Inpaint と Outpaint ツールでのみ使用され、レンダリングやその他の目的には使用しないでください。

スペシャルconcept タグ
concepts システムはタグによって構成され、動物からポーズまで幅広いトピックがある。
Typeと呼ばれる特別なタグがあり、モデルがどのように振る舞うかを教えてくれます。また、PositivesとNegative Promptsの代わりに、DetailersとNegativeと呼ばれるものがあります。ネガティブconcept タイプを使用するときは、ウェイトもネガティブに設定することを忘れないでください。

Hyper」や「Turbo」のような速そうな名前のモデルは、render images 。 Guidance / CFG.
複数のブレンドconcepts: ウェイトを使う
concepts の隣に表示されるスライダーはウェイトと呼ばれる。ベースモデルは絵の具のキャンバスのようなもので、常に100%のウェイトを持っています。サポートする小さなモデルは、(マイナス)-2から2(最大)のウェイトの間で調整できます。通常、3つ以下のモデルを選択する場合は、0.4から0.7の間のウェイトが最適です。バランスを見ながら調整してください。

ネガティブモデルを使用する場合は、ウェイトをマイナス(通常は-1または-2)にスライドさせる。
少なくとも1つのベースを使用する
複数のベースモデルを追加することもできますが(使いやすくするため)、ベースは1つしか使えないので、不要なベースモデルは削除することを忘れないでください。ベースモデルはブレンドできないが、LoRaとInversionsはブレンドできる。 また、LoRaやTIをベース/フルモデルの代わりとして選択しないように注意してください。
トラブルシューティング
多くのモデルを使用することは、同時に多くの曲を演奏するようなものである。それらがすべて同じ音量(重さ)であれば、何かを選ぶことは難しい。
images が過度にブロック化されていたり、ピクセル化されているように見える場合は、ベース・モデルを使用し、guidance を 7 以下に設定し、ポジとネガが強すぎないようにしてください。ウェイトを調整して、最適なバランスを見つけましょう。Guidance とパラメータについては、以下のガイドを参照してください。
パラメータ

解像度幅と高さ
AIモデルの写真は特定のサイズで "訓練 "されているため、images 、そのサイズに近いものを作成するのが最良の結果を生む。あまり早く大きくしようとすると、不具合(双子、余分な手足)が生じる可能性がある。
ガイドライン
- 安定した拡散XLモデル:1,024×1,024からスタートし、通常は1,400×1,400以下が安全。
- Stable Diffusion 1.5は512×512でトレーニングされているため、上限は768×768となる。Photonのようないくつかの高度なモデルは、960×576で実行されます。その他のSD15サイズのヒント
- 4Kに近い2段階目のアップスケーリングはいつでも可能です。下記のFacelift アップスケーラー情報をご覧ください。



高効率モデル
低Steps, 低Guidance
ほとんどのconcepts 、素晴らしい画像を生成するにはguidance 7と35以上steps 。これは、より高効率のモデルが登場するにつれて変化している。
これらのモデルは、images を1/4の時間で作成することができ、guidance の低い4-12steps で済む。これらの モデルには ターボ、ハイパー、LCM 、ライトニング concepts とタグ付けされており、クラシックモデルと互換性があります。同じモデルファミリーのLorasやInversionsと一緒に使うことができます。SDXLファミリーが最も品揃えが豊富です(右端のプルダウンメニューを使用してください)。

Some of our favorite Lightning models are <boltning-xl> and <realvis4light-xl> which look great with a guidance of 2, steps between 4-12, and Refiner (no fix) turned off. Polish it off with a good negative like [[<fastnegative-xl:-2>]]. Follow it up with an upscale, and the effects are stunning!
使い方の詳細については、これらの特別なモデルタイプのノートをご覧ください。 エーテルバース-XL(下の写真)。guidance は2.5、steps は8。


ロング・プロンプト・ウェイト(実験的)
オンにすると、肯定的および否定的なプロンプトを長く書くことができます。デモビデオを見る
例
((high quality, masterpiece, masterwork)) A wizard browsing through a magical marketplace with a mystical air around him. He has pointy ears, spectacles perched precariously on his nose, and a wand twirling in hsi hand. His robes are adorned with intricate patterns and patterns of magic dust. There is a bubbling magical cauldron, and mythical creatures peeking around from behind him.

これは、プロンプトの理解度を77のトークンよりもはるかに高めることができ、プロンプトの理解度を全体的に向上させる、プロンプトのバランス調整ユーティリティである。 もちろん、いくつかの不運なトレードオフがなければ、これを標準に設定するだろう:
制限事項
- 最良の結果を得るには、 guidance 、7 以下が必要。
- LPWは、非常に強い肯定的または否定的なプロンプトと組み合わせてはならない。
- (((((;゚Д゚))))))))))))
- [[[これもそうだろう]]]。
- ロラスやインバージョンとは相性が悪い。 concepts
- LPW はRemix ツールと100% 互換性があるわけではありません。
- では動作しない。LCM sampler